
diff options
| author | George Hazan <ghazan@miranda.im> | 2018-09-14 16:33:56 +0300 |
|---|---|---|
| committer | George Hazan <ghazan@miranda.im> | 2018-09-14 16:33:56 +0300 |
| commit | 50d176bfe78d4b5ffd829a874e503facef398e7d (patch) | |
| tree | 3048927747b53a7c79ef73a5671d9ec912322382 /libs | |
| parent | cc03b109287f4c818a4d6df09cbfa48784e1e4a6 (diff) | |
merge with libmdbx release
Diffstat (limited to 'libs')
27 files changed, 4278 insertions, 2437 deletions
diff --git a/libs/libmdbx/src/README-RU.md b/libs/libmdbx/src/README-RU.md index f4ae5e8f14..5dd062c1a6 100644 --- a/libs/libmdbx/src/README-RU.md +++ b/libs/libmdbx/src/README-RU.md @@ -12,31 +12,31 @@ and [by Yandex](https://translate.yandex.ru/translate?url=https%3A%2F%2Fgithub.c ### Project Status - -**Сейчас MDBX _активно перерабатывается_** и к середине 2018 -ожидается большое изменение как API, так и формата базы данных. -К сожалению, обновление приведет к потере совместимости с -предыдущими версиями. - -Цель этой революции - обеспечение более четкого надежного -API и добавление новых функции, а также наделение базы данных -новыми свойствами. - -В настоящее время MDBX предназначена для Linux, а также -поддерживает Windows (начиная с Windows Server 2008) в качестве -дополнительной платформы. Поддержка других ОС может быть -обеспечена на коммерческой основе. Однако такие -усовершенствования (т. е. pull-requests) могут быть приняты в -мейнстрим только в том случае, если будет доступен -соответствующий публичный и бесплатный сервис непрерывной -интеграции (aka Continuous Integration). +**Сейчас MDBX _активно перерабатывается_** и к середине 2018 ожидается +большое изменение как API, так и формата базы данных. К сожалению, +обновление приведет к потере совместимости с предыдущими версиями. + +Цель этой революции - обеспечение более четкого надежного API и +добавление новых функции, а также наделение базы данных новыми +свойствами. + +В настоящее время MDBX предназначена для Linux, а также поддерживает +Windows (начиная с Windows Server 2008) в качестве дополнительной +платформы. Поддержка других ОС может быть обеспечена на коммерческой +основе. Однако такие усовершенствования (т. е. pull-requests) могут быть +приняты в мейнстрим только в том случае, если будет доступен +соответствующий публичный и бесплатный сервис непрерывной интеграции +(aka Continuous Integration). ## Содержание - - [Обзор](#Обзор) - [Сравнение с другими СУБД](#Сравнение-с-другими-СУБД) - [История & Acknowledgments](#История) - [Основные свойства](#Основные-свойства) +- [Доработки и усовершенствования относительно LMDB](#Доработки-и-усовершенствования-относительно-lmdb) +- [Недостатки и Компромиссы](#Недостатки-и-Компромиссы) + - [Проблема долгих чтений](#Проблема-долгих-чтений) + - [Сохранность данных в режиме асинхронной фиксации](#Сохранность-данных-в-режиме-асинхронной-фиксации) - [Сравнение производительности](#Сравнение-производительности) - [Интегральная производительность](#Интегральная-производительность) - [Масштабируемость чтения](#Масштабируемость-чтения) @@ -44,21 +44,18 @@ API и добавление новых функции, а также надел� - [Отложенная фиксация](#Отложенная-фиксация) - [Асинхронная фиксация](#Асинхронная-фиксация) - [Потребление ресурсов](#Потребление-ресурсов) -- [Недостатки и Компромиссы](#Недостатки-и-Компромиссы) - - [Проблема долгих чтений](#Проблема-долгих-чтений) - - [Сохранность данных в режиме асинхронной фиксации](#Сохранность-данных-в-режиме-асинхронной-фиксации) -- [Доработки и усовершенствования относительно LMDB](#Доработки-и-усовершенствования-относительно-lmdb) ## Обзор - _libmdbx_ - это встраиваемый key-value движок хранения со специфическим набором свойств и возможностей, ориентированный на создание уникальных -легковесных решений с предельной производительностью под Linux и Windows. +легковесных решений с предельной производительностью под Linux и +Windows. _libmdbx_ позволяет множеству процессов совместно читать и обновлять -несколько key-value таблиц с соблюдением [ACID](https://ru.wikipedia.org/wiki/ACID), -при минимальных накладных расходах и амортизационной стоимости любых операций Olog(N). +несколько key-value таблиц с соблюдением +[ACID](https://ru.wikipedia.org/wiki/ACID), при минимальных накладных +расходах и амортизационной стоимости любых операций Olog(N). _libmdbx_ обеспечивает [serializability](https://en.wikipedia.org/wiki/Serializability) @@ -72,20 +69,26 @@ _libmdbx_ позволяет выполнять операции чтения с параллельно на каждом ядре CPU, без использования атомарных операций и/или примитивов синхронизации. -_libmdbx_ не использует [LSM](https://en.wikipedia.org/wiki/Log-structured_merge-tree), а основан на [B+Tree](https://en.wikipedia.org/wiki/B%2B_tree) с [отображением](https://en.wikipedia.org/wiki/Memory-mapped_file) всех данных в память, -при этом текущая версия не использует [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging). -Это предопределяет многие свойства, в том числе удачные и противопоказанные сценарии использования. +_libmdbx_ не использует +[LSM](https://en.wikipedia.org/wiki/Log-structured_merge-tree), а +основан на [B+Tree](https://en.wikipedia.org/wiki/B%2B_tree) с +[отображением](https://en.wikipedia.org/wiki/Memory-mapped_file) всех +данных в память, при этом текущая версия не использует +[WAL](https://en.wikipedia.org/wiki/Write-ahead_logging). Это +предопределяет многие свойства, в том числе удачные и противопоказанные +сценарии использования. -### Сравнение с другими СУБД -Ввиду того, что в _libmdbx_ сейчас происходит революция, я посчитал лучшим решением -ограничится здесь ссылкой на [главу Comparison with other databases](https://github.com/coreos/bbolt#comparison-with-other-databases) в описании _BoltDB_. +### Сравнение с другими СУБД +Ввиду того, что в _libmdbx_ сейчас происходит революция, я посчитал +лучшим решением ограничится здесь ссылкой на [главу Comparison with +other databases](https://github.com/coreos/bbolt#comparison-with-other-databases) +в описании _BoltDB_. ### История - -_libmdbx_ является результатом переработки и развития "Lightning Memory-Mapped Database", -известной под аббревиатурой +_libmdbx_ является результатом переработки и развития "Lightning +Memory-Mapped Database", известной под аббревиатурой [LMDB](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database). Изначально доработка производилась в составе проекта [ReOpenLDAP](https://github.com/leo-yuriev/ReOpenLDAP). Примерно за год @@ -102,226 +105,223 @@ Technologies](https://www.ptsecurity.ru). #### Acknowledgments +Howard Chu (Symas Corporation) - the author of LMDB, from which +originated the MDBX in 2015. -Howard Chu (Symas Corporation) - the author of LMDB, -from which originated the MDBX in 2015. - -Martin Hedenfalk <martin@bzero.se> - the author of `btree.c` code, -which was used for begin development of LMDB. +Martin Hedenfalk <martin@bzero.se> - the author of `btree.c` code, which +was used for begin development of LMDB. Основные свойства ================= -_libmdbx_ наследует все ключевые возможности и особенности -своего прародителя [LMDB](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database), -но с устранением ряда описываемых далее проблем и архитектурных недочетов. - -1. Данные хранятся в упорядоченном отображении (ordered map), ключи всегда - отсортированы, поддерживается выборка диапазонов (range lookups). - -2. Данные отображается в память каждого работающего с БД процесса. - К данным и ключам обеспечивается прямой доступ в памяти без необходимости их - копирования. - -3. Транзакции согласно - [ACID](https://ru.wikipedia.org/wiki/ACID), посредством - [MVCC](https://ru.wikipedia.org/wiki/MVCC) и - [COW](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BF%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D0%BF%D1%80%D0%B8_%D0%B7%D0%B0%D0%BF%D0%B8%D1%81%D0%B8). - Изменения строго последовательны и не блокируются чтением, - конфликты между транзакциями невозможны. - При этом гарантируется чтение только зафиксированных данных, см [relaxing serializability](https://en.wikipedia.org/wiki/Serializability). - -4. Чтение и поиск [без блокировок](https://ru.wikipedia.org/wiki/%D0%9D%D0%B5%D0%B1%D0%BB%D0%BE%D0%BA%D0%B8%D1%80%D1%83%D1%8E%D1%89%D0%B0%D1%8F_%D1%81%D0%B8%D0%BD%D1%85%D1%80%D0%BE%D0%BD%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F), - без [атомарных операций](https://ru.wikipedia.org/wiki/%D0%90%D1%82%D0%BE%D0%BC%D0%B0%D1%80%D0%BD%D0%B0%D1%8F_%D0%BE%D0%BF%D0%B5%D1%80%D0%B0%D1%86%D0%B8%D1%8F). - Читатели не блокируются операциями записи и не конкурируют - между собой, чтение масштабируется линейно по ядрам CPU. +_libmdbx_ наследует все ключевые возможности и особенности своего +прародителя +[LMDB](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database), +но с устранением ряда описываемых далее проблем и архитектурных +недочетов. + +1. Данные хранятся в упорядоченном отображении (ordered map), ключи +всегда отсортированы, поддерживается выборка диапазонов (range lookups). + +2. Данные отображается в память каждого работающего с БД процесса. К +данным и ключам обеспечивается прямой доступ в памяти без необходимости +их копирования. + +3. Транзакции согласно [ACID](https://ru.wikipedia.org/wiki/ACID), +посредством [MVCC](https://ru.wikipedia.org/wiki/MVCC) и +[COW](https://ru.wikipedia.org/wiki/%D0%9A%D0%BE%D0%BF%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5_%D0%BF%D1%80%D0%B8_%D0%B7%D0%B0%D0%BF%D0%B8%D1%81%D0%B8). +Изменения строго последовательны и не блокируются чтением, конфликты +между транзакциями невозможны. При этом гарантируется чтение только +зафиксированных данных, см [relaxing +serializability](https://en.wikipedia.org/wiki/Serializability). + +4. Чтение и поиск [без +блокировок](https://ru.wikipedia.org/wiki/%D0%9D%D0%B5%D0%B1%D0%BB%D0%BE%D0%BA%D0%B8%D1%80%D1%83%D1%8E%D1%89%D0%B0%D1%8F_%D1%81%D0%B8%D0%BD%D1%85%D1%80%D0%BE%D0%BD%D0%B8%D0%B7%D0%B0%D1%86%D0%B8%D1%8F), +без [атомарных +операций](https://ru.wikipedia.org/wiki/%D0%90%D1%82%D0%BE%D0%BC%D0%B0%D1%80%D0%BD%D0%B0%D1%8F_%D0%BE%D0%BF%D0%B5%D1%80%D0%B0%D1%86%D0%B8%D1%8F). +Читатели не блокируются операциями записи и не конкурируют между собой, +чтение масштабируется линейно по ядрам CPU. > Для точности следует отметить, что "подключение к БД" (старт первой > читающей транзакции в потоке) и "отключение от БД" (закрытие БД или > завершение потока) требуют краткосрочного захвата блокировки для > регистрации/дерегистрации текущего потока в "таблице читателей". -5. Эффективное хранение дубликатов (ключей с несколькими - значениями), без дублирования ключей, с сортировкой значений, в - том числе целочисленных (для вторичных индексов). +5. Эффективное хранение дубликатов (ключей с несколькими значениями), +без дублирования ключей, с сортировкой значений, в том числе +целочисленных (для вторичных индексов). -6. Эффективная поддержка коротких ключей фиксированной длины, в том числе целочисленных. +6. Эффективная поддержка коротких ключей фиксированной длины, в том +числе целочисленных. 7. Амортизационная стоимость любой операции Olog(N), - [WAF](https://en.wikipedia.org/wiki/Write_amplification) (Write - Amplification Factor) и RAF (Read Amplification Factor) также Olog(N). +[WAF](https://en.wikipedia.org/wiki/Write_amplification) (Write +Amplification Factor) и RAF (Read Amplification Factor) также Olog(N). -8. Нет [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) и журнала - транзакций, после сбоев не требуется восстановление. Не требуется компактификация - или какое-либо периодическое обслуживание. Поддерживается резервное копирование - "по горячему", на работающей БД без приостановки изменения данных. +8. Нет [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) и +журнала транзакций, после сбоев не требуется восстановление. Не +требуется компактификация или какое-либо периодическое обслуживание. +Поддерживается резервное копирование "по горячему", на работающей БД без +приостановки изменения данных. -9. Отсутствует какое-либо внутреннее управление памятью или кэшированием. Всё - необходимое штатно выполняет ядро ОС! +9. Отсутствует какое-либо внутреннее управление памятью или +кэшированием. Всё необходимое штатно выполняет ядро ОС. -Сравнение производительности -============================ - -Все представленные ниже данные получены многократным прогоном тестов на -ноутбуке Lenovo Carbon-2, i7-4600U 2.1 ГГц, 8 Гб ОЗУ, с SSD-диском -SAMSUNG MZNTD512HAGL-000L1 (DXT23L0Q) 512 Гб. - -Исходный код бенчмарка [_IOArena_](https://github.com/pmwkaa/ioarena) и -сценарии тестирования [доступны на -github](https://github.com/pmwkaa/ioarena/tree/HL%2B%2B2015). - --------------------------------------------------------------------------------- - -### Интегральная производительность - -Показана соотнесенная сумма ключевых показателей производительности в трёх -бенчмарках: - - - Чтение/Поиск на машине с 4-мя процессорами; - - - Транзакции с [CRUD](https://ru.wikipedia.org/wiki/CRUD)-операциями - (вставка, чтение, обновление, удаление) в режиме **синхронной фиксации** - данных (fdatasync при завершении каждой транзакции или аналог); - - - Транзакции с [CRUD](https://ru.wikipedia.org/wiki/CRUD)-операциями - (вставка, чтение, обновление, удаление) в режиме **отложенной фиксации** - данных (отложенная запись посредством файловой систем или аналог); - -*Бенчмарк в режиме асинхронной записи не включен по двум причинам:* +Доработки и усовершенствования относительно LMDB +================================================ - 1. Такое сравнение не совсем правомочно, его следует делать с движками - ориентированными на хранение данных в памяти ([Tarantool](https://tarantool.io/), [Redis](https://redis.io/)). +1. Утилита `mdbx_chk` для проверки целостности структуры БД. - 2. Превосходство libmdbx становится еще более подавляющим, что мешает - восприятию информации. +2. Автоматическое динамическое управление размером БД согласно +параметрам задаваемым функцией `mdbx_env_set_geometry()`, включая шаг +приращения и порог уменьшения размера БД, а также выбор размера +страницы. Соответственно, это позволяет снизить фрагментированность +файла БД на диске и освободить место, в том числе в **Windows**. - +3. Автоматическая без-затратная компактификация БД путем возврата +освобождающихся страниц в область нераспределенного резерва в конце +файла данных. При этом уменьшается количество страниц находящихся в +памяти и участвующих в в обмене с диском. --------------------------------------------------------------------------------- +4. Поддержка ключей и значений нулевой длины, включая сортированные +дубликаты. -### Масштабируемость чтения +5. Возможность связать с каждой завершаемой транзакцией до 3 +дополнительных маркеров посредством `mdbx_canary_put()`, и прочитать их +в транзакции чтения посредством `mdbx_canary_get()`. -Для каждого движка показана суммарная производительность при -одновременном выполнении запросов чтения/поиска в 1-2-4-8 потоков на -машине с 4-мя физическими процессорами. +6. Возможность посредством `mdbx_replace()` обновить или удалить запись +с получением предыдущего значения данных, а также адресно изменить +конкретное multi-значение. - +7. Режим `LIFO RECLAIM`. --------------------------------------------------------------------------------- + Для повторного использования выбираются не самые старые, а + самые новые страницы из доступных. За счет этого цикл + использования страниц всегда имеет минимальную длину и не + зависит от общего числа выделенных страниц. -### Синхронная фиксация + В результате механизмы кэширования и обратной записи работают с + максимально возможной эффективностью. В случае использования + контроллера дисков или системы хранения с + [BBWC](https://en.wikipedia.org/wiki/BBWC) возможно + многократное увеличение производительности по записи + (обновлению данных). - - Линейная шкала слева и темные прямоугольники соответствуют количеству - транзакций в секунду, усредненному за всё время теста. +8. Генерация последовательностей посредством `mdbx_dbi_sequence()`. - - Логарифмическая шкала справа и желтые интервальные отрезки - соответствуют времени выполнения транзакций. При этом каждый отрезок - показывает минимальное и максимальное время, затраченное на выполнение - транзакций, а крестиком отмечено среднеквадратичное значение. +9. Обработчик `OOM-KICK`. -Выполняется **10.000 транзакций в режиме синхронной фиксации данных** на -диске. При этом требуется гарантия, что при аварийном выключении питания -(или другом подобном сбое) все данные будут консистентны и полностью -соответствовать последней завершенной транзакции. В _libmdbx_ в этом -режиме при фиксации каждой транзакции выполняется системный вызов -[fdatasync](https://linux.die.net/man/2/fdatasync). + Посредством `mdbx_env_set_oomfunc()` может быть установлен + внешний обработчик (callback), который будет вызван при + исчерпании свободных страниц по причине долгой операцией чтения + на фоне интенсивного изменения данных. + Обработчику будет передан PID и pthread_id виновника. + В свою очередь обработчик может предпринять одно из действий: -В каждой транзакции выполняется комбинированная CRUD-операция (две -вставки, одно чтение, одно обновление, одно удаление). Бенчмарк стартует -на пустой базе, а при завершении, в результате выполняемых действий, в -базе насчитывается 10.000 небольших key-value записей. + * нейтрализовать виновника (отправить сигнал kill #9), если + долгое чтение выполняется сторонним процессом; - + * отменить или перезапустить проблемную операцию чтения, если + операция выполняется одним из потоков текущего процесса; --------------------------------------------------------------------------------- + * подождать некоторое время, в расчете на то, что проблемная операция + чтения будет штатно завершена; -### Отложенная фиксация + * прервать текущую операцию изменения данных с возвратом кода + ошибки. - - Линейная шкала слева и темные прямоугольники соответствуют количеству - транзакций в секунду, усредненному за всё время теста. +10. Возможность открыть БД в эксклюзивном режиме посредством флага +`MDBX_EXCLUSIVE`. - - Логарифмическая шкала справа и желтые интервальные отрезки - соответствуют времени выполнения транзакций. При этом каждый отрезок - показывает минимальное и максимальное время, затраченное на выполнение - транзакций, а крестиком отмечено среднеквадратичное значение. +11. Возможность получить отставание текущей транзакции чтения от +последней версии данных в БД посредством `mdbx_txn_straggler()`. -Выполняется **100.000 транзакций в режиме отложенной фиксации данных** -на диске. При этом требуется гарантия, что при аварийном выключении -питания (или другом подобном сбое) все данные будут консистентны на -момент завершения одной из транзакций, но допускается потеря изменений -из некоторого количества последних транзакций, что для многих движков -предполагает включение -[WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) (write-ahead -logging) либо журнала транзакций, который в свою очередь опирается на -гарантию упорядоченности данных в журналируемой файловой системе. -_libmdbx_ при этом не ведет WAL, а передает весь контроль файловой -системе и ядру ОС. +12. Возможность явно запросить обновление существующей записи, без +создания новой посредством флажка `MDBX_CURRENT` для `mdbx_put()`. -В каждой транзакции выполняется комбинированная CRUD-операция (две -вставки, одно чтение, одно обновление, одно удаление). Бенчмарк стартует -на пустой базе, а при завершении, в результате выполняемых действий, в -базе насчитывается 100.000 небольших key-value записей. +13. Исправленный вариант `mdbx_cursor_count()`, возвращающий корректное +количество дубликатов для всех типов таблиц и любого положения курсора. - +14. Возможность получить посредством `mdbx_env_info()` дополнительную +информацию, включая номер самой старой версии БД (снимка данных), +который используется одним из читателей. --------------------------------------------------------------------------------- +15. Функция `mdbx_del()` не игнорирует дополнительный (уточняющий) +аргумент `data` для таблиц без дубликатов (без флажка `MDBX_DUPSORT`), а +при его ненулевом значении всегда использует его для сверки с удаляемой +записью. -### Асинхронная фиксация +16. Возможность открыть dbi-таблицу, одновременно с установкой +компараторов для ключей и данных, посредством `mdbx_dbi_open_ex()`. - - Линейная шкала слева и темные прямоугольники соответствуют количеству - транзакций в секунду, усредненному за всё время теста. +17. Возможность посредством `mdbx_is_dirty()` определить находятся ли +некоторый ключ или данные в "грязной" странице БД. Таким образом, +избегая лишнего копирования данных перед выполнением модифицирующих +операций (значения, размещенные в "грязных" страницах, могут быть +перезаписаны при изменениях, иначе они будут неизменны). - - Логарифмическая шкала справа и желтые интервальные отрезки - соответствуют времени выполнения транзакций. При этом каждый отрезок - показывает минимальное и максимальное время, затраченное на выполнение - транзакций, а крестиком отмечено среднеквадратичное значение. +18. Корректное обновление текущей записи, в том числе сортированного +дубликата, при использовании режима `MDBX_CURRENT` в +`mdbx_cursor_put()`. -Выполняется **1.000.000 транзакций в режиме асинхронной фиксации -данных** на диске. При этом требуется гарантия, что при аварийном -выключении питания (или другом подобном сбое) все данные будут -консистентны на момент завершения одной из транзакций, но допускается -потеря изменений из значительного количества последних транзакций. Во -всех движках при этом включался режим предполагающий минимальную -нагрузку на диск по записи, и соответственно минимальную гарантию -сохранности данных. В _libmdbx_ при этом используется режим асинхронной -записи измененных страниц на диск посредством ядра ОС и системного -вызова [msync(MS_ASYNC)](https://linux.die.net/man/2/msync). +19. Возможность узнать есть ли за текущей позицией курсора строка данных +посредством `mdbx_cursor_eof()`. -В каждой транзакции выполняется комбинированная CRUD-операция (две -вставки, одно чтение, одно обновление, одно удаление). Бенчмарк стартует -на пустой базе, а при завершении, в результате выполняемых действий, в -базе насчитывается 10.000 небольших key-value записей. +20. Дополнительный код ошибки `MDBX_EMULTIVAL`, который возвращается из +`mdbx_put()` и `mdbx_replace()` при попытке выполнить неоднозначное +обновление или удаления одного из нескольких значений с одним ключом. -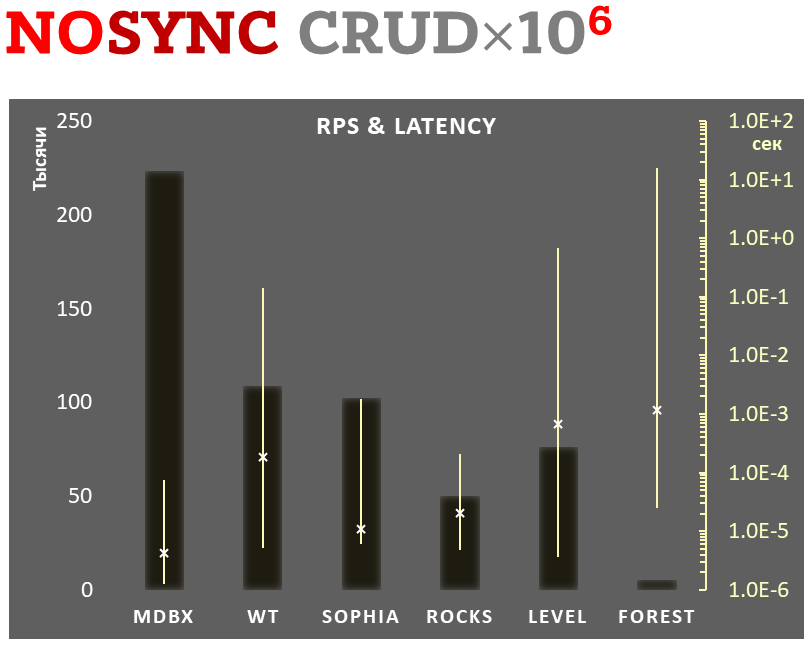 +21. Возможность посредством `mdbx_get_ex()` получить значение по +заданному ключу, одновременно с количеством дубликатов. --------------------------------------------------------------------------------- +22. Наличие функций `mdbx_cursor_on_first()` и `mdbx_cursor_on_last()`, +которые позволяют быстро выяснить стоит ли курсор на первой/последней +позиции. -### Потребление ресурсов +23. Возможность автоматического формирования контрольных точек (сброса +данных на диск) при накоплении заданного объёма изменений, +устанавливаемого функцией `mdbx_env_set_syncbytes()`. -Показана соотнесенная сумма использованных ресурсов в ходе бенчмарка в -режиме отложенной фиксации: +24. Управление отладкой и получение отладочных сообщений посредством +`mdbx_setup_debug()`. - - суммарное количество операций ввода-вывода (IOPS), как записи, так и - чтения. +25. Функция `mdbx_env_pgwalk()` для обхода всех страниц БД. - - суммарное затраченное время процессора, как в режиме пользовательских процессов, - так и в режиме ядра ОС. +26. Три мета-страницы вместо двух, что позволяет гарантированно +консистентно обновлять слабые контрольные точки фиксации без риска +повредить крайнюю сильную точку фиксации. - - использованное место на диске при завершении теста, после закрытия БД из тестирующего процесса, - но без ожидания всех внутренних операций обслуживания (компактификации LSM и т.п.). +27. Гарантия сохранности БД в режиме `WRITEMAP+MAPSYNC`. + > В текущей версии _libmdbx_ вам предоставляется выбор между безопасным + > режимом (по умолчанию) асинхронной фиксации, и режимом `UTTERLY_NOSYNC` + > когда при системной аварии есть шанс полного разрушения БД как в LMDB. + > Для подробностей смотрите раздел + > [Сохранность данных в режиме асинхронной фиксации](#Сохранность-данных-в-режиме-асинхронной-фиксации). -Движок _ForestDB_ был исключен при оформлении результатов, так как -относительно конкурентов многократно превысил потребление каждого из -ресурсов (потратил процессорное время на генерацию IOPS для заполнения -диска), что не позволяло наглядно сравнить показатели остальных движков -на одной диаграмме. +28. Возможность закрыть БД в "грязном" состоянии (без сброса данных и +формирования сильной точки фиксации) посредством `mdbx_env_close_ex()`. -Все данные собирались посредством системного вызова -[getrusage()](http://man7.org/linux/man-pages/man2/getrusage.2.html) и -сканированием директорий с данными. +29. При завершении читающих транзакций, открытые в них DBI-хендлы не +закрываются и не теряются при завершении таких транзакций посредством +`mdbx_txn_abort()` или `mdbx_txn_reset()`. Что позволяет избавится от ряда +сложно обнаруживаемых ошибок. -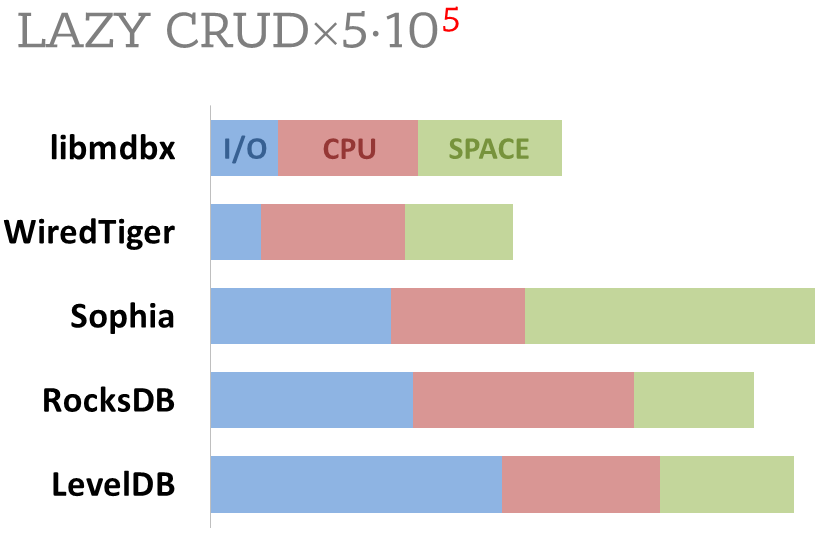 +30. Все курсоры, как в транзакциях только для чтения, так и в пишущих, +могут быть переиспользованы посредством `mdbx_cursor_renew()` и ДОЛЖНЫ +ОСВОБОЖДАТЬСЯ ЯВНО. + > + > ## _ВАЖНО_, Обратите внимание! + > + > Это единственное изменение в API, которое значимо меняет + > семантику управления курсорами и может приводить к утечкам + > памяти. Следует отметить, что это изменение вынужденно. + > Так устраняется неоднозначность с массой тяжких последствий: + > + > - обращение к уже освобожденной памяти; + > - попытки повторного освобождения памяти; + > - повреждение памяти и ошибки сегментации. -------------------------------------------------------------------------------- @@ -382,7 +382,6 @@ _libmdbx_ при этом не ведет WAL, а передает весь ко #### Проблема долгих чтений - *Следует отметить*, что проблема "сборки мусора" так или иначе существует во всех СУБД (Vacuum в PostgreSQL). Однако в случае _libmdbx_ и LMDB она проявляется более остро, прежде всего из-за высокой @@ -448,19 +447,17 @@ _libmdbx_ при этом не ведет WAL, а передает весь ко за счет эффективной работы [BBWC](https://en.wikipedia.org/wiki/BBWC) при включении `LIFO RECLAIM` в _libmdbx_. - #### Сохранность данных в режиме асинхронной фиксации - При работе в режиме `WRITEMAP+MAPSYNC` запись измененных страниц выполняется ядром ОС, что имеет ряд преимуществ. Так например, при крахе приложения, ядро ОС сохранит все изменения. Однако, при аварийном отключении питания или сбое в ядре ОС, на диске -может быть сохранена только часть измененных страниц БД. При этом с большой -вероятностью может оказаться, что будут сохранены мета-страницы со -ссылками на страницы с новыми версиями данных, но не сами новые данные. -В этом случае БД будет безвозвратна разрушена, даже если до аварии -производилась полная синхронизация данных (посредством +может быть сохранена только часть измененных страниц БД. При этом с +большой вероятностью может оказаться, что будут сохранены мета-страницы +со ссылками на страницы с новыми версиями данных, но не сами новые +данные. В этом случае БД будет безвозвратна разрушена, даже если до +аварии производилась полная синхронизация данных (посредством `mdbx_env_sync()`). В _libmdbx_ эта проблема устранена путем полной переработки @@ -488,186 +485,194 @@ _libmdbx_ при этом не ведет WAL, а передает весь ко * При открытии БД выполняется автоматический откат к последней сильной фиксации. Этим обеспечивается гарантия сохранности БД. -Такая гарантия надежности не дается бесплатно. Для -сохранности данных, страницы, формирующие крайний снимок с -сильной фиксацией, не должны повторно использоваться -(перезаписываться) до формирования следующей сильной точки -фиксации. Таким образом, крайняя точка фиксации создает -описанный выше эффект "долгого чтения". Разница же здесь в том, -что при исчерпании свободных страниц ситуация будет -автоматически исправлена, посредством записи изменений на диск -и формирования новой сильной точки фиксации. +Такая гарантия надежности не дается бесплатно. Для сохранности данных, +страницы, формирующие крайний снимок с сильной фиксацией, не должны +повторно использоваться (перезаписываться) до формирования следующей +сильной точки фиксации. Таким образом, крайняя точка фиксации создает +описанный выше эффект "долгого чтения". Разница же здесь в том, что при +исчерпании свободных страниц ситуация будет автоматически исправлена, +посредством записи изменений на диск и формирования новой сильной точки +фиксации. Таким образом, в режиме безопасной асинхронной фиксации _libmdbx_ будет -всегда использовать новые страницы до исчерпания места в БД или до явного -формирования сильной точки фиксации посредством `mdbx_env_sync()`. -При этом суммарный трафик записи на диск будет примерно такой же, -как если бы отдельно фиксировалась каждая транзакция. +всегда использовать новые страницы до исчерпания места в БД или до +явного формирования сильной точки фиксации посредством +`mdbx_env_sync()`. При этом суммарный трафик записи на диск будет +примерно такой же, как если бы отдельно фиксировалась каждая транзакция. В текущей версии _libmdbx_ вам предоставляется выбор между безопасным -режимом (по умолчанию) асинхронной фиксации, и режимом `UTTERLY_NOSYNC` когда -при системной аварии есть шанс полного разрушения БД как в LMDB. +режимом (по умолчанию) асинхронной фиксации, и режимом `UTTERLY_NOSYNC` +когда при системной аварии есть шанс полного разрушения БД как в LMDB. -В последующих версиях _libmdbx_ будут предусмотрены средства -для асинхронной записи данных на диск с автоматическим -формированием сильных точек фиксации. +В последующих версиях _libmdbx_ будут предусмотрены средства для +асинхронной записи данных на диск с автоматическим формированием сильных +точек фиксации. -------------------------------------------------------------------------------- -Доработки и усовершенствования относительно LMDB -================================================ +Сравнение производительности +============================ -1. Режим `LIFO RECLAIM`. +Все представленные ниже данные получены многократным прогоном тестов на +ноутбуке Lenovo Carbon-2, i7-4600U 2.1 ГГц, 8 Гб ОЗУ, с SSD-диском +SAMSUNG MZNTD512HAGL-000L1 (DXT23L0Q) 512 Гб. - Для повторного использования выбираются не самые старые, а - самые новые страницы из доступных. За счет этого цикл - использования страниц всегда имеет минимальную длину и не - зависит от общего числа выделенных страниц. +Исходный код бенчмарка [_IOArena_](https://github.com/pmwkaa/ioarena) и +сценарии тестирования [доступны на +github](https://github.com/pmwkaa/ioarena/tree/HL%2B%2B2015). - В результате механизмы кэширования и обратной записи работают с - максимально возможной эффективностью. В случае использования - контроллера дисков или системы хранения с - [BBWC](https://en.wikipedia.org/wiki/BBWC) возможно - многократное увеличение производительности по записи - (обновлению данных). +-------------------------------------------------------------------------------- -2. Обработчик `OOM-KICK`. +### Интегральная производительность - Посредством `mdbx_env_set_oomfunc()` может быть установлен - внешний обработчик (callback), который будет вызван при - исчерпании свободных страниц из-за долгой операцией чтения. - Обработчику будет передан PID и pthread_id виновника. - В свою очередь обработчик может предпринять одно из действий: +Показана соотнесенная сумма ключевых показателей производительности в трёх +бенчмарках: - * нейтрализовать виновника (отправить сигнал kill #9), если - долгое чтение выполняется сторонним процессом; + - Чтение/Поиск на машине с 4-мя процессорами; - * отменить или перезапустить проблемную операцию чтения, если - операция выполняется одним из потоков текущего процесса; + - Транзакции с [CRUD](https://ru.wikipedia.org/wiki/CRUD)-операциями + (вставка, чтение, обновление, удаление) в режиме **синхронной фиксации** + данных (fdatasync при завершении каждой транзакции или аналог); - * подождать некоторое время, в расчете на то, что проблемная операция - чтения будет штатно завершена; + - Транзакции с [CRUD](https://ru.wikipedia.org/wiki/CRUD)-операциями + (вставка, чтение, обновление, удаление) в режиме **отложенной фиксации** + данных (отложенная запись посредством файловой систем или аналог); - * прервать текущую операцию изменения данных с возвратом кода - ошибки. +*Бенчмарк в режиме асинхронной записи не включен по двум причинам:* -3. Гарантия сохранности БД в режиме `WRITEMAP+MAPSYNC`. - > В текущей версии _libmdbx_ вам предоставляется выбор между безопасным - > режимом (по умолчанию) асинхронной фиксации, и режимом `UTTERLY_NOSYNC` - > когда при системной аварии есть шанс полного разрушения БД как в LMDB. - > Для подробностей смотрите раздел - > [Сохранность данных в режиме асинхронной фиксации](#Сохранность-данных-в-режиме-асинхронной-фиксации). + 1. Такое сравнение не совсем правомочно, его следует делать с движками + ориентированными на хранение данных в памяти ([Tarantool](https://tarantool.io/), [Redis](https://redis.io/)). -4. Возможность автоматического формирования контрольных точек -(сброса данных на диск) при накоплении заданного объёма изменений, -устанавливаемого функцией `mdbx_env_set_syncbytes()`. + 2. Превосходство libmdbx становится еще более подавляющим, что мешает + восприятию информации. -5. Возможность получить отставание текущей транзакции чтения от -последней версии данных в БД посредством `mdbx_txn_straggler()`. + -6. Утилита mdbx_chk для проверки БД и функция `mdbx_env_pgwalk()` для -обхода всех страниц БД. +-------------------------------------------------------------------------------- -7. Управление отладкой и получение отладочных сообщений посредством -`mdbx_setup_debug()`. +### Масштабируемость чтения -8. Возможность связать с каждой завершаемой транзакцией до 3 -дополнительных маркеров посредством `mdbx_canary_put()`, и прочитать их -в транзакции чтения посредством `mdbx_canary_get()`. +Для каждого движка показана суммарная производительность при +одновременном выполнении запросов чтения/поиска в 1-2-4-8 потоков на +машине с 4-мя физическими процессорами. -9. Возможность узнать есть ли за текущей позицией курсора строка данных -посредством `mdbx_cursor_eof()`. + -10. Возможность явно запросить обновление существующей записи, без -создания новой посредством флажка `MDBX_CURRENT` для `mdbx_put()`. +-------------------------------------------------------------------------------- -11. Возможность посредством `mdbx_replace()` обновить или удалить запись -с получением предыдущего значения данных, а также адресно изменить -конкретное multi-значение. +### Синхронная фиксация -12. Поддержка ключей и значений нулевой длины, включая сортированные -дубликаты. + - Линейная шкала слева и темные прямоугольники соответствуют количеству + транзакций в секунду, усредненному за всё время теста. -13. Исправленный вариант `mdbx_cursor_count()`, возвращающий корректное -количество дубликатов для всех типов таблиц и любого положения курсора. + - Логарифмическая шкала справа и желтые интервальные отрезки + соответствуют времени выполнения транзакций. При этом каждый отрезок + показывает минимальное и максимальное время, затраченное на выполнение + транзакций, а крестиком отмечено среднеквадратичное значение. -14. Возможность открыть БД в эксклюзивном режиме посредством флага -`MDBX_EXCLUSIVE`, например в целях её проверки. +Выполняется **10.000 транзакций в режиме синхронной фиксации данных** на +диске. При этом требуется гарантия, что при аварийном выключении питания +(или другом подобном сбое) все данные будут консистентны и полностью +соответствовать последней завершенной транзакции. В _libmdbx_ в этом +режиме при фиксации каждой транзакции выполняется системный вызов +[fdatasync](https://linux.die.net/man/2/fdatasync). -15. Возможность закрыть БД в "грязном" состоянии (без сброса данных и -формирования сильной точки фиксации) посредством `mdbx_env_close_ex()`. +В каждой транзакции выполняется комбинированная CRUD-операция (две +вставки, одно чтение, одно обновление, одно удаление). Бенчмарк стартует +на пустой базе, а при завершении, в результате выполняемых действий, в +базе насчитывается 10.000 небольших key-value записей. -16. Возможность получить посредством `mdbx_env_info()` дополнительную -информацию, включая номер самой старой версии БД (снимка данных), -который используется одним из читателей. + -17. Функция `mdbx_del()` не игнорирует дополнительный (уточняющий) -аргумент `data` для таблиц без дубликатов (без флажка `MDBX_DUPSORT`), а -при его ненулевом значении всегда использует его для сверки с удаляемой -записью. +-------------------------------------------------------------------------------- -18. Возможность открыть dbi-таблицу, одновременно с установкой -компараторов для ключей и данных, посредством `mdbx_dbi_open_ex()`. +### Отложенная фиксация -19. Возможность посредством `mdbx_is_dirty()` определить находятся ли -некоторый ключ или данные в "грязной" странице БД. Таким образом, -избегая лишнего копирования данных перед выполнением модифицирующих -операций (значения, размещенные в "грязных" страницах, могут быть -перезаписаны при изменениях, иначе они будут неизменны). + - Линейная шкала слева и темные прямоугольники соответствуют количеству + транзакций в секунду, усредненному за всё время теста. -20. Корректное обновление текущей записи, в том числе сортированного -дубликата, при использовании режима `MDBX_CURRENT` в -`mdbx_cursor_put()`. + - Логарифмическая шкала справа и желтые интервальные отрезки + соответствуют времени выполнения транзакций. При этом каждый отрезок + показывает минимальное и максимальное время, затраченное на выполнение + транзакций, а крестиком отмечено среднеквадратичное значение. -21. Все курсоры, как в транзакциях только для чтения, так и в пишущих, -могут быть переиспользованы посредством `mdbx_cursor_renew()` и ДОЛЖНЫ -ОСВОБОЖДАТЬСЯ ЯВНО. - > - > ## _ВАЖНО_, Обратите внимание! - > - > Это единственное изменение в API, которое значимо меняет - > семантику управления курсорами и может приводить к утечкам - > памяти. Следует отметить, что это изменение вынужденно. - > Так устраняется неоднозначность с массой тяжких последствий: - > - > - обращение к уже освобожденной памяти; - > - попытки повторного освобождения памяти; - > - повреждение памяти и ошибки сегментации. +Выполняется **100.000 транзакций в режиме отложенной фиксации данных** +на диске. При этом требуется гарантия, что при аварийном выключении +питания (или другом подобном сбое) все данные будут консистентны на +момент завершения одной из транзакций, но допускается потеря изменений +из некоторого количества последних транзакций, что для многих движков +предполагает включение +[WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) (write-ahead +logging) либо журнала транзакций, который в свою очередь опирается на +гарантию упорядоченности данных в журналируемой файловой системе. +_libmdbx_ при этом не ведет WAL, а передает весь контроль файловой +системе и ядру ОС. -22. Дополнительный код ошибки `MDBX_EMULTIVAL`, который возвращается из -`mdbx_put()` и `mdbx_replace()` при попытке выполнить неоднозначное -обновление или удаления одного из нескольких значений с одним ключом. +В каждой транзакции выполняется комбинированная CRUD-операция (две +вставки, одно чтение, одно обновление, одно удаление). Бенчмарк стартует +на пустой базе, а при завершении, в результате выполняемых действий, в +базе насчитывается 100.000 небольших key-value записей. -23. Возможность посредством `mdbx_get_ex()` получить значение по -заданному ключу, одновременно с количеством дубликатов. + -24. Наличие функций `mdbx_cursor_on_first()` и `mdbx_cursor_on_last()`, -которые позволяют быстро выяснить стоит ли курсор на первой/последней -позиции. +-------------------------------------------------------------------------------- -25. При завершении читающих транзакций, открытые в них DBI-хендлы не -закрываются и не теряются при завершении таких транзакций посредством -`mdbx_txn_abort()` или `mdbx_txn_reset()`. Что позволяет избавится от ряда -сложно обнаруживаемых ошибок. +### Асинхронная фиксация -26. Генерация последовательностей посредством `mdbx_dbi_sequence()`. + - Линейная шкала слева и темные прямоугольники соответствуют количеству + транзакций в секунду, усредненному за всё время теста. -27. Расширенное динамическое управление размером БД, включая выбор -размера страницы посредством `mdbx_env_set_geometry()`, -в том числе в **Windows** + - Логарифмическая шкала справа и желтые интервальные отрезки + соответствуют времени выполнения транзакций. При этом каждый отрезок + показывает минимальное и максимальное время, затраченное на выполнение + транзакций, а крестиком отмечено среднеквадратичное значение. -28. Три мета-страницы вместо двух, что позволяет гарантированно -консистентно обновлять слабые контрольные точки фиксации без риска -повредить крайнюю сильную точку фиксации. +Выполняется **1.000.000 транзакций в режиме асинхронной фиксации +данных** на диске. При этом требуется гарантия, что при аварийном +выключении питания (или другом подобном сбое) все данные будут +консистентны на момент завершения одной из транзакций, но допускается +потеря изменений из значительного количества последних транзакций. Во +всех движках при этом включался режим предполагающий минимальную +нагрузку на диск по записи, и соответственно минимальную гарантию +сохранности данных. В _libmdbx_ при этом используется режим асинхронной +записи измененных страниц на диск посредством ядра ОС и системного +вызова [msync(MS_ASYNC)](https://linux.die.net/man/2/msync). + +В каждой транзакции выполняется комбинированная CRUD-операция (две +вставки, одно чтение, одно обновление, одно удаление). Бенчмарк стартует +на пустой базе, а при завершении, в результате выполняемых действий, в +базе насчитывается 10.000 небольших key-value записей. + + + +-------------------------------------------------------------------------------- + +### Потребление ресурсов + +Показана соотнесенная сумма использованных ресурсов в ходе бенчмарка в +режиме отложенной фиксации: -29. В _libmdbx_ реализован автоматический возврат освобождающихся -страниц в область нераспределенного резерва в конце файла данных. При -этом уменьшается количество страниц загруженных в память и участвующих в -цикле обновления данных и записи на диск. Фактически _libmdbx_ выполняет -постоянную компактификацию данных, но не затрачивая на это -дополнительных ресурсов, а только освобождая их. При освобождении места -в БД и установке соответствующих параметров геометрии базы данных, также будет -уменьшаться размер файла на диске, в том числе в **Windows**. + - суммарное количество операций ввода-вывода (IOPS), как записи, так и + чтения. + + - суммарное затраченное время процессора, как в режиме пользовательских + процессов, так и в режиме ядра ОС. + + - использованное место на диске при завершении теста, после закрытия БД + из тестирующего процесса, но без ожидания всех внутренних операций + обслуживания (компактификации LSM и т.п.). + +Движок _ForestDB_ был исключен при оформлении результатов, так как +относительно конкурентов многократно превысил потребление каждого из +ресурсов (потратил процессорное время на генерацию IOPS для заполнения +диска), что не позволяло наглядно сравнить показатели остальных движков +на одной диаграмме. + +Все данные собирались посредством системного вызова +[getrusage()](http://man7.org/linux/man-pages/man2/getrusage.2.html) и +сканированием директорий с данными. + + -------------------------------------------------------------------------------- @@ -685,16 +690,3 @@ Idx Name Size VMA LMA File off Algn CONTENTS, ALLOC, LOAD, READONLY, CODE ``` - -``` -$ gcc -v -Using built-in specs. -COLLECT_GCC=gcc -COLLECT_LTO_WRAPPER=/usr/lib/gcc/x86_64-linux-gnu/7/lto-wrapper -OFFLOAD_TARGET_NAMES=nvptx-none -OFFLOAD_TARGET_DEFAULT=1 -Target: x86_64-linux-gnu -Configured with: ../src/configure -v --with-pkgversion='Ubuntu 7.2.0-8ubuntu3' --with-bugurl=file:///usr/share/doc/gcc-7/README.Bugs --enable-languages=c,ada,c++,go,brig,d,fortran,objc,obj-c++ --prefix=/usr --with-gcc-major-version-only --program-suffix=-7 --program-prefix=x86_64-linux-gnu- --enable-shared --enable-linker-build-id --libexecdir=/usr/lib --without-included-gettext --enable-threads=posix --libdir=/usr/lib --enable-nls --with-sysroot=/ --enable-clocale=gnu --enable-libstdcxx-debug --enable-libstdcxx-time=yes --with-default-libstdcxx-abi=new --enable-gnu-unique-object --disable-vtable-verify --enable-libmpx --enable-plugin --enable-default-pie --with-system-zlib --with-target-system-zlib --enable-objc-gc=auto --enable-multiarch --disable-werror --with-arch-32=i686 --with-abi=m64 --with-multilib-list=m32,m64,mx32 --enable-multilib --with-tune=generic --enable-offload-targets=nvptx-none --without-cuda-driver --enable-checking=release --build=x86_64-linux-gnu --host=x86_64-linux-gnu --target=x86_64-linux-gnu -Thread model: posix -gcc version 7.2.0 (Ubuntu 7.2.0-8ubuntu3) -``` diff --git a/libs/libmdbx/src/README.md b/libs/libmdbx/src/README.md index 92b6542fa7..7c07de316e 100644 --- a/libs/libmdbx/src/README.md +++ b/libs/libmdbx/src/README.md @@ -9,9 +9,21 @@ libmdbx ## Project Status for now - - The stable versions ([_stable/0.0_](https://github.com/leo-yuriev/libmdbx/tree/stable/0.0) and [_stable/0.1_](https://github.com/leo-yuriev/libmdbx/tree/stable/0.1) branches) of _MDBX_ are frozen, i.e. no new features or API changes, but only bug fixes. - - The next version ([_devel_](https://github.com/leo-yuriev/libmdbx/tree/devel) branch) **is under active non-public development**, i.e. current API and set of features are extreme volatile. - - The immediate goal of development is formation of the stable API and the stable internal database format, which allows realise all PLANNED FEATURES: + - The stable versions + ([_stable/0.0_](https://github.com/leo-yuriev/libmdbx/tree/stable/0.0) + and + [_stable/0.1_](https://github.com/leo-yuriev/libmdbx/tree/stable/0.1) + branches) of _MDBX_ are frozen, i.e. no new features or API changes, but + only bug fixes. + + - The next version + ([_devel_](https://github.com/leo-yuriev/libmdbx/tree/devel) branch) + **is under active non-public development**, i.e. current API and set of + features are extreme volatile. + + - The immediate goal of development is formation of the stable API and + the stable internal database format, which allows realise all PLANNED + FEATURES: 1. Integrity check by [Merkle tree](https://en.wikipedia.org/wiki/Merkle_tree); 2. Support for [raw block devices](https://en.wikipedia.org/wiki/Raw_device); 3. Separate place (HDD) for large data items; @@ -24,19 +36,21 @@ Don't miss [Java Native Interface](https://github.com/castortech/mdbxjni) by [Ca ----- -Nowadays MDBX intended for Linux, and support Windows (since -Windows Server 2008) as a complementary platform. Support for -other OS could be implemented on commercial basis. However such -enhancements (i.e. pull requests) could be accepted in -mainstream only when corresponding public and free Continuous -Integration service will be available. +Nowadays MDBX intended for Linux, and support Windows (since Windows +Server 2008) as a complementary platform. Support for other OS could be +implemented on commercial basis. However such enhancements (i.e. pull +requests) could be accepted in mainstream only when corresponding public +and free Continuous Integration service will be available. ## Contents - - [Overview](#overview) - [Comparison with other DBs](#comparison-with-other-dbs) - [History & Acknowledgments](#history) - [Main features](#main-features) +- [Improvements over LMDB](#improvements-over-lmdb) +- [Gotchas](#gotchas) + - [Long-time read transactions problem](#long-time-read-transactions-problem) + - [Data safety in async-write-mode](#data-safety-in-async-write-mode) - [Performance comparison](#performance-comparison) - [Integral performance](#integral-performance) - [Read scalability](#read-scalability) @@ -44,52 +58,58 @@ Integration service will be available. - [Lazy-write mode](#lazy-write-mode) - [Async-write mode](#async-write-mode) - [Cost comparison](#cost-comparison) -- [Gotchas](#gotchas) - - [Long-time read transactions problem](#long-time-read-transactions-problem) - - [Data safety in async-write-mode](#data-safety-in-async-write-mode) -- [Improvements over LMDB](#improvements-over-lmdb) ## Overview +_libmdbx_ is an embedded lightweight key-value database engine oriented +for performance under Linux and Windows. -_libmdbx_ is an embedded lightweight key-value database engine oriented for performance under Linux and Windows. - -_libmdbx_ allows multiple processes to read and update several key-value tables concurrently, -while being [ACID](https://en.wikipedia.org/wiki/ACID)-compliant, with minimal overhead and operation cost of Olog(N). +_libmdbx_ allows multiple processes to read and update several key-value +tables concurrently, while being +[ACID](https://en.wikipedia.org/wiki/ACID)-compliant, with minimal +overhead and operation cost of Olog(N). _libmdbx_ provides -[serializability](https://en.wikipedia.org/wiki/Serializability) and consistency of data after crash. -Read-write transactions don't block read-only transactions and are -[serialized](https://en.wikipedia.org/wiki/Serializability) by [mutex](https://en.wikipedia.org/wiki/Mutual_exclusion). - -_libmdbx_ [wait-free](https://en.wikipedia.org/wiki/Non-blocking_algorithm#Wait-freedom) provides parallel read transactions -without atomic operations or synchronization primitives. - -_libmdbx_ uses [B+Trees](https://en.wikipedia.org/wiki/B%2B_tree) and [mmap](https://en.wikipedia.org/wiki/Memory-mapped_file), -doesn't use [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging). This might have caveats for some workloads. +[serializability](https://en.wikipedia.org/wiki/Serializability) and +consistency of data after crash. Read-write transactions don't block +read-only transactions and are +[serialized](https://en.wikipedia.org/wiki/Serializability) by +[mutex](https://en.wikipedia.org/wiki/Mutual_exclusion). + +_libmdbx_ +[wait-free](https://en.wikipedia.org/wiki/Non-blocking_algorithm#Wait-freedom) +provides parallel read transactions without atomic operations or +synchronization primitives. + +_libmdbx_ uses [B+Trees](https://en.wikipedia.org/wiki/B%2B_tree) and +[mmap](https://en.wikipedia.org/wiki/Memory-mapped_file), doesn't use +[WAL](https://en.wikipedia.org/wiki/Write-ahead_logging). This might +have caveats for some workloads. ### Comparison with other DBs - -Because _libmdbx_ is currently overhauled, I think it's better to just link -[chapter of Comparison with other databases](https://github.com/coreos/bbolt#comparison-with-other-databases) here. +Because _libmdbx_ is currently overhauled, I think it's better to just +link [chapter of Comparison with other +databases](https://github.com/coreos/bbolt#comparison-with-other-databases) +here. ### History - -The _libmdbx_ design is based on [Lightning Memory-Mapped Database](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database). -Initial development was going in [ReOpenLDAP](https://github.com/leo-yuriev/ReOpenLDAP) project, about a year later it -received separate development effort and in autumn 2015 was isolated to separate project, which was -[presented at Highload++ 2015 conference](http://www.highload.ru/2015/abstracts/1831.html). - -Since early 2017 _libmdbx_ is used in [Fast Positive Tables](https://github.com/leo-yuriev/libfpta), +The _libmdbx_ design is based on [Lightning Memory-Mapped +Database](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database). +Initial development was going in +[ReOpenLDAP](https://github.com/leo-yuriev/ReOpenLDAP) project, about a +year later it received separate development effort and in autumn 2015 +was isolated to separate project, which was [presented at Highload++ +2015 conference](http://www.highload.ru/2015/abstracts/1831.html). + +Since early 2017 _libmdbx_ is used in [Fast PositiveTables](https://github.com/leo-yuriev/libfpta), by [Positive Technologies](https://www.ptsecurity.com). #### Acknowledgments +Howard Chu (Symas Corporation) - the author of LMDB, from which +originated the MDBX in 2015. -Howard Chu (Symas Corporation) - the author of LMDB, -from which originated the MDBX in 2015. - -Martin Hedenfalk <martin@bzero.se> - the author of `btree.c` code, -which was used for begin development of LMDB. +Martin Hedenfalk <martin@bzero.se> - the author of `btree.c` code, which +was used for begin development of LMDB. Main features @@ -98,365 +118,468 @@ Main features _libmdbx_ inherits all keys features and characteristics from [LMDB](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database): -1. Data is stored in ordered map, keys are always sorted, range lookups are supported. - -2. Data is [mmaped](https://en.wikipedia.org/wiki/Memory-mapped_file) to memory of each worker DB process, read transactions are zero-copy. - -3. Transactions are [ACID](https://en.wikipedia.org/wiki/ACID)-compliant, thanks to - [MVCC](https://en.wikipedia.org/wiki/Multiversion_concurrency_control) and [CoW](https://en.wikipedia.org/wiki/Copy-on-write). - Writes are strongly serialized and aren't blocked by reads, transactions can't conflict with each other. - Reads are guaranteed to get only commited data - ([relaxing serializability](https://en.wikipedia.org/wiki/Serializability#Relaxing_serializability)). - -4. Reads and queries are [non-blocking](https://en.wikipedia.org/wiki/Non-blocking_algorithm), - don't use [atomic operations](https://en.wikipedia.org/wiki/Linearizability#High-level_atomic_operations). - Readers don't block each other and aren't blocked by writers. Read performance scales linearly with CPU core count. - > Though "connect to DB" (start of first read transaction in thread) and "disconnect from DB" (shutdown or thread - > termination) requires to acquire a lock to register/unregister current thread from "readers table" - -5. Keys with multiple values are stored efficiently without key duplication, sorted by value, including integers - (reasonable for secondary indexes). - -6. Efficient operation on short fixed length keys, including integer ones. - -7. [WAF](https://en.wikipedia.org/wiki/Write_amplification) (Write Amplification Factor) и RAF (Read Amplification Factor) - are Olog(N). - -8. No [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) and transaction journal. - In case of a crash no recovery needed. No need for regular maintenance. Backups can be made on the fly on working DB - without freezing writers. +1. Data is stored in ordered map, keys are always sorted, range lookups +are supported. + +2. Data is [mmaped](https://en.wikipedia.org/wiki/Memory-mapped_file) to +memory of each worker DB process, read transactions are zero-copy. + +3. Transactions are +[ACID](https://en.wikipedia.org/wiki/ACID)-compliant, thanks to +[MVCC](https://en.wikipedia.org/wiki/Multiversion_concurrency_control) +and [CoW](https://en.wikipedia.org/wiki/Copy-on-write). Writes are +strongly serialized and aren't blocked by reads, transactions can't +conflict with each other. Reads are guaranteed to get only commited data +([relaxing serializability](https://en.wikipedia.org/wiki/Serializability#Relaxing_serializability)). + +4. Reads and queries are +[non-blocking](https://en.wikipedia.org/wiki/Non-blocking_algorithm), +don't use [atomic +operations](https://en.wikipedia.org/wiki/Linearizability#High-level_atomic_operations). +Readers don't block each other and aren't blocked by writers. Read +performance scales linearly with CPU core count. + > Though "connect to DB" (start of first read transaction in thread) and + > "disconnect from DB" (shutdown or thread termination) requires to + > acquire a lock to register/unregister current thread from "readers + > table" + +5. Keys with multiple values are stored efficiently without key +duplication, sorted by value, including integers (reasonable for +secondary indexes). + +6. Efficient operation on short fixed length keys, including integer +ones. + +7. [WAF](https://en.wikipedia.org/wiki/Write_amplification) (Write +Amplification Factor) и RAF (Read Amplification Factor) are Olog(N). + +8. No [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) and +transaction journal. In case of a crash no recovery needed. No need for +regular maintenance. Backups can be made on the fly on working DB + without freezing writers. 9. No custom memory management, all done with standard OS syscalls. +-------------------------------------------------------------------------------- -Performance comparison -===================== +Improvements over LMDB +====================== -All benchmarks were done by [IOArena](https://github.com/pmwkaa/ioarena) -and multiple [scripts](https://github.com/pmwkaa/ioarena/tree/HL%2B%2B2015) -runs on Lenovo Carbon-2 laptop, i7-4600U 2.1 GHz, 8 Gb RAM, -SSD SAMSUNG MZNTD512HAGL-000L1 (DXT23L0Q) 512 Gb. +1. `mdbx_chk` tool for DB integrity check. --------------------------------------------------------------------------------- +2. Automatic dynamic DB size management according to the parameters +specified by `mdbx_env_set_geometry()` function. Including including +growth step and truncation threshold, as well as the choice of page +size. -### Integral performance +3. Automatic returning of freed pages into unallocated space at the end +of database file with optionally automatic shrinking it. This reduces +amount of pages resides in RAM and circulated in disk I/O. In fact +_libmdbx_ constantly performs DB compactification, without spending +additional resources for that. -Here showed sum of performance metrics in 3 benchmarks: +4. Support for keys and values of zero length, including sorted +duplicates. - - Read/Search on 4 CPU cores machine; +5. Ability to assign up to 3 markers to commiting transaction with +`mdbx_canary_put()` and then get them in read transaction by +`mdbx_canary_get()`. - - Transactions with [CRUD](https://en.wikipedia.org/wiki/CRUD) operations - in sync-write mode (fdatasync is called after each transaction); +6. Ability to update or delete record and get previous value via +`mdbx_replace()` Also can update specific multi-value. - - Transactions with [CRUD](https://en.wikipedia.org/wiki/CRUD) operations - in lazy-write mode (moment to sync data to persistent storage is decided by OS). +7. `LIFO RECLAIM` mode: -*Reasons why asynchronous mode isn't benchmarked here:* + The newest pages are picked for reuse instead of the oldest. This allows + to minimize reclaim loop and make it execution time independent of total + page count. - 1. It doesn't make sense as it has to be done with DB engines, oriented for keeping data in memory e.g. - [Tarantool](https://tarantool.io/), [Redis](https://redis.io/)), etc. + This results in OS kernel cache mechanisms working with maximum + efficiency. In case of using disk controllers or storages with + [BBWC](https://en.wikipedia.org/wiki/Disk_buffer#Write_acceleration) + this may greatly improve write performance. - 2. Performance gap is too high to compare in any meaningful way. +8. Sequence generation via `mdbx_dbi_sequence()`. - +9. `OOM-KICK` callback. --------------------------------------------------------------------------------- + `mdbx_env_set_oomfunc()` allows to set a callback, which will be called + in the event of DB space exhausting during long-time read transaction in + parallel with extensive updating. Callback will be invoked with PID and + pthread_id of offending thread as parameters. Callback can do any of + these things to remedy the problem: -### Read Scalability + * wait for read transaction to finish normally; -Summary performance with concurrent read/search queries in 1-2-4-8 threads on 4 CPU cores machine. + * kill the offending process (signal 9), if separate process is doing + long-time read; - + * abort or restart offending read transaction if it's running in sibling + thread; --------------------------------------------------------------------------------- + * abort current write transaction with returning error code. -### Sync-write mode +10. Ability to open DB in exclusive mode with `MDBX_EXCLUSIVE` flag. - - Linear scale on left and dark rectangles mean arithmetic mean transactions per second; +11. Ability to get how far current read-only snapshot is from latest +version of the DB by `mdbx_txn_straggler()`. - - Logarithmic scale on right is in seconds and yellow intervals mean execution time of transactions. - Each interval shows minimal and maximum execution time, cross marks standard deviation. +12. Ability to explicitly request update of present record without +creating new record. Implemented as `MDBX_CURRENT` flag for +`mdbx_put()`. -**10,000 transactions in sync-write mode**. In case of a crash all data is consistent and state is right after last successful transaction. [fdatasync](https://linux.die.net/man/2/fdatasync) syscall is used after each write transaction in this mode. +13. Fixed `mdbx_cursor_count()`, which returns correct count of +duplicated for all table types and any cursor position. -In the benchmark each transaction contains combined CRUD operations (2 inserts, 1 read, 1 update, 1 delete). -Benchmark starts on empty database and after full run the database contains 10,000 small key-value records. +14. `mdbx_env_info()` to getting additional info, including number of +the oldest snapshot of DB, which is used by one of the readers. - +15. `mdbx_del()` doesn't ignore additional argument (specifier) `data` +for tables without duplicates (without flag `MDBX_DUPSORT`), if `data` +is not null then always uses it to verify record, which is being +deleted. --------------------------------------------------------------------------------- +16. Ability to open dbi-table with simultaneous setup of comparators for +keys and values, via `mdbx_dbi_open_ex()`. -### Lazy-write mode +17. `mdbx_is_dirty()`to find out if key or value is on dirty page, that +useful to avoid copy-out before updates. - - Linear scale on left and dark rectangles mean arithmetic mean of thousands transactions per second; +18. Correct update of current record in `MDBX_CURRENT` mode of +`mdbx_cursor_put()`, including sorted duplicated. - - Logarithmic scale on right in seconds and yellow intervals mean execution time of transactions. Each interval shows minimal and maximum execution time, cross marks standard deviation. +19. Check if there is a row with data after current cursor position via +`mdbx_cursor_eof()`. -**100,000 transactions in lazy-write mode**. -In case of a crash all data is consistent and state is right after one of last transactions, but transactions after it -will be lost. Other DB engines use [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) or transaction journal for that, -which in turn depends on order of operations in journaled filesystem. _libmdbx_ doesn't use WAL and hands I/O operations -to filesystem and OS kernel (mmap). +20. Additional error code `MDBX_EMULTIVAL`, which is returned by +`mdbx_put()` and `mdbx_replace()` in case is ambiguous update or delete. -In the benchmark each transaction contains combined CRUD operations (2 inserts, 1 read, 1 update, 1 delete). -Benchmark starts on empty database and after full run the database contains 100,000 small key-value records. +21. Ability to get value by key and duplicates count by `mdbx_get_ex()`. +22. Functions `mdbx_cursor_on_first()` and `mdbx_cursor_on_last()`, +which allows to know if cursor is currently on first or last position +respectively. - +23. Automatic creation of synchronization points (flush changes to +persistent storage) when changes reach set threshold (threshold can be +set by `mdbx_env_set_syncbytes()`). --------------------------------------------------------------------------------- +24. Control over debugging and receiving of debugging messages via +`mdbx_setup_debug()`. -### Async-write mode +25. Function `mdbx_env_pgwalk()` for page-walking all pages in DB. - - Linear scale on left and dark rectangles mean arithmetic mean of thousands transactions per second; +26. Three meta-pages instead of two, this allows to guarantee +consistently update weak sync-points without risking to corrupt last +steady sync-point. - - Logarithmic scale on right in seconds and yellow intervals mean execution time of transactions. Each interval shows minimal and maximum execution time, cross marks standard deviation. +27. Guarantee of DB integrity in `WRITEMAP+MAPSYNC` mode: + > Current _libmdbx_ gives a choice of safe async-write mode (default) + > and `UTTERLY_NOSYNC` mode which may result in full + > DB corruption during system crash as with LMDB. For details see + > [Data safety in async-write mode](#data-safety-in-async-write-mode). -**1,000,000 transactions in async-write mode**. In case of a crash all data will be consistent and state will be right after one of last transactions, but lost transaction count is much higher than in lazy-write mode. All DB engines in this mode do as little writes as possible on persistent storage. _libmdbx_ uses [msync(MS_ASYNC)](https://linux.die.net/man/2/msync) in this mode. +28. Ability to close DB in "dirty" state (without data flush and +creation of steady synchronization point) via `mdbx_env_close_ex()`. -In the benchmark each transaction contains combined CRUD operations (2 inserts, 1 read, 1 update, 1 delete). -Benchmark starts on empty database and after full run the database contains 10,000 small key-value records. +29. If read transaction is aborted via `mdbx_txn_abort()` or +`mdbx_txn_reset()` then DBI-handles, which were opened in it, aren't +closed or deleted. This allows to avoid several types of hard-to-debug +errors. - +30. All cursors in all read and write transactions can be reused by +`mdbx_cursor_renew()` and MUST be freed explicitly. + > ## Caution, please pay attention! + > + > This is the only change of API, which changes semantics of cursor management + > and can lead to memory leaks on misuse. This is a needed change as it eliminates ambiguity + > which helps to avoid such errors as: + > - use-after-free; + > - double-free; + > - memory corruption and segfaults. -------------------------------------------------------------------------------- -### Cost comparison - -Summary of used resources during lazy-write mode benchmarks: +## Gotchas - - Read and write IOPS; +1. At one moment there can be only one writer. But this allows to +serialize writes and eliminate any possibility of conflict or logical +errors during transaction rollback. + +2. No [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) means +relatively big [WAF](https://en.wikipedia.org/wiki/Write_amplification) +(Write Amplification Factor). Because of this syncing data to disk might +be quite resource intensive and be main performance bottleneck during +intensive write workload. + > As compromise _libmdbx_ allows several modes of lazy and/or periodic + > syncing, including `MAPASYNC` mode, which modificate data in memory and + > asynchronously syncs data to disk, moment to sync is picked by OS. + > + > Although this should be used with care, synchronous transactions in a DB + > with transaction journal will require 2 IOPS minimum (probably 3-4 in + > practice) because of filesystem overhead, overhead depends on + > filesystem, not on record count or record size. In _libmdbx_ IOPS count + > will grow logarithmically depending on record count in DB (height of B+ + > tree) and will require at least 2 IOPS per transaction too. + +3. [CoW](https://en.wikipedia.org/wiki/Copy-on-write) for +[MVCC](https://en.wikipedia.org/wiki/Multiversion_concurrency_control) +is done on memory page level with +[B+trees](https://ru.wikipedia.org/wiki/B-%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE). +Therefore altering data requires to copy about Olog(N) memory pages, +which uses [memory bandwidth](https://en.wikipedia.org/wiki/Memory_bandwidth) and is main +performance bottleneck in `MAPASYNC` mode. + > This is unavoidable, but isn't that bad. Syncing data to disk requires + > much more similar operations which will be done by OS, therefore this is + > noticeable only if data sync to persistent storage is fully disabled. + > _libmdbx_ allows to safely save data to persistent storage with minimal + > performance overhead. If there is no need to save data to persistent + > storage then it's much more preferable to use `std::map`. + + +4. LMDB has a problem of long-time readers which degrades performance +and bloats DB. + > _libmdbx_ addresses that, details below. - - Sum of user CPU time and sys CPU time; +5. _LMDB_ is susceptible to DB corruption in `WRITEMAP+MAPASYNC` mode. +_libmdbx_ in `WRITEMAP+MAPASYNC` guarantees DB integrity and consistency +of data. + > Additionally there is an alternative: `UTTERLY_NOSYNC` mode. + > Details below. - - Used space on persistent storage after the test and closed DB, but not waiting for the end of all internal - housekeeping operations (LSM compactification, etc). -_ForestDB_ is excluded because benchmark showed it's resource consumption for each resource (CPU, IOPS) much higher than other engines which prevents to meaningfully compare it with them. +#### Long-time read transactions problem +Garbage collection problem exists in all databases one way or another +(e.g. VACUUM in PostgreSQL). But in _libmdbx_ and LMDB it's even more +important because of high performance and deliberate simplification of +internals with emphasis on performance. -All benchmark data is gathered by [getrusage()](http://man7.org/linux/man-pages/man2/getrusage.2.html) syscall and by -scanning data directory. +* Altering data during long read operation may exhaust available space +on persistent storage. - +* If available space is exhausted then any attempt to update data +results in `MAP_FULL` error until long read operation ends. --------------------------------------------------------------------------------- +* Main examples of long readers is hot backup and debugging of client +application which actively uses read transactions. -## Gotchas +* In _LMDB_ this results in degraded performance of all operations of +syncing data to persistent storage. -1. At one moment there can be only one writer. But this allows to serialize writes and eliminate any possibility - of conflict or logical errors during transaction rollback. - -2. No [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) means relatively - big [WAF](https://en.wikipedia.org/wiki/Write_amplification) (Write Amplification Factor). - Because of this syncing data to disk might be quite resource intensive and be main performance bottleneck - during intensive write workload. - > As compromise _libmdbx_ allows several modes of lazy and/or periodic syncing, including `MAPASYNC` mode, which modificate - > data in memory and asynchronously syncs data to disk, moment to sync is picked by OS. - > - > Although this should be used with care, synchronous transactions in a DB with transaction journal will require 2 IOPS - > minimum (probably 3-4 in practice) because of filesystem overhead, overhead depends on filesystem, not on record - > count or record size. In _libmdbx_ IOPS count will grow logarithmically depending on record count in DB (height of B+ tree) - > and will require at least 2 IOPS per transaction too. - -3. [CoW](https://en.wikipedia.org/wiki/Copy-on-write) - for [MVCC](https://en.wikipedia.org/wiki/Multiversion_concurrency_control) is done on memory page level with [B+ - trees](https://ru.wikipedia.org/wiki/B-%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE). - Therefore altering data requires to copy about Olog(N) memory pages, which uses [memory bandwidth](https://en.wikipedia.org/wiki/Memory_bandwidth) and is main performance bottleneck in `MAPASYNC` mode. - > This is unavoidable, but isn't that bad. Syncing data to disk requires much more similar operations which will - > be done by OS, therefore this is noticeable only if data sync to persistent storage is fully disabled. - > _libmdbx_ allows to safely save data to persistent storage with minimal performance overhead. If there is no need - > to save data to persistent storage then it's much more preferable to use `std::map`. - - -4. LMDB has a problem of long-time readers which degrades performance and bloats DB - > _libmdbx_ addresses that, details below. +* _libmdbx_ has a mechanism which aborts such operations and `LIFO RECLAIM` +mode which addresses performance degradation. + +Read operations operate only over snapshot of DB which is consistent on +the moment when read transaction started. This snapshot doesn't change +throughout the transaction but this leads to inability to reclaim the +pages until read transaction ends. + +In _LMDB_ this leads to a problem that memory pages, allocated for +operations during long read, will be used for operations and won't be +reclaimed until DB process terminates. In _LMDB_ they are used in +[FIFO](https://en.wikipedia.org/wiki/FIFO_(computing_and_electronics)) +manner, which causes increased page count and less chance of cache hit +during I/O. In other words: one long-time reader can impact performance +of all database until it'll be reopened. + +_libmdbx_ addresses the problem, details below. Illustrations to this +problem can be found in the +[presentation](http://www.slideshare.net/leoyuriev/lmdb). There is also +example of performance increase thanks to +[BBWC](https://en.wikipedia.org/wiki/Disk_buffer#Write_acceleration) +when `LIFO RECLAIM` enabled in _libmdbx_. -5. _LMDB_ is susceptible to DB corruption in `WRITEMAP+MAPASYNC` mode. - _libmdbx_ in `WRITEMAP+MAPASYNC` guarantees DB integrity and consistency of data. - > Additionally there is an alternative: `UTTERLY_NOSYNC` mode. Details below. +#### Data safety in async-write mode +In `WRITEMAP+MAPSYNC` mode dirty pages are written to persistent storage +by kernel. This means that in case of application crash OS kernel will +write all dirty data to disk and nothing will be lost. But in case of +hardware malfunction or OS kernel fatal error only some dirty data might +be synced to disk, and there is high probability that pages with +metadata saved, will point to non-saved, hence non-existent, data pages. +In such situation, DB is completely corrupted and can't be repaired even +if there was full sync before the crash via `mdbx_env_sync(). +_libmdbx_ addresses this by fully reimplementing write path of data: -#### Long-time read transactions problem +* In `WRITEMAP+MAPSYNC` mode meta-data pages aren't updated in place, +instead their shadow copies are used and their updates are synced after +data is flushed to disk. -Garbage collection problem exists in all databases one way or another (e.g. VACUUM in PostgreSQL). -But in _libmdbx_ and LMDB it's even more important because of high performance and deliberate -simplification of internals with emphasis on performance. +* During transaction commit _libmdbx_ marks synchronization points as +steady or weak depending on how much synchronization needed between RAM +and persistent storage, e.g. in `WRITEMAP+MAPSYNC` commited transactions +are marked as weak, but during explicit data synchronization - as +steady. -* Altering data during long read operation may exhaust available space on persistent storage. +* _libmdbx_ maintains three separate meta-pages instead of two. This +allows to commit transaction with steady or weak synchronization point +without losing two previous synchronization points (one of them can be +steady, and second - weak). This allows to order weak and steady +synchronization points in any order without losing consistency in case +of system crash. -* If available space is exhausted then any attempt to update data - results in `MAP_FULL` error until long read operation ends. +* During DB open _libmdbx_ rollbacks to the last steady synchronization +point, this guarantees database integrity. -* Main examples of long readers is hot backup - and debugging of client application which actively uses read transactions. +For data safety pages which form database snapshot with steady +synchronization point must not be updated until next steady +synchronization point. So last steady synchronization point creates +"long-time read" effect. The only difference that in case of memory +exhaustion the problem will be immediately addressed by flushing changes +to persistent storage and forming new steady synchronization point. -* In _LMDB_ this results in degraded performance of all operations - of syncing data to persistent storage. +So in async-write mode _libmdbx_ will always use new pages until memory +is exhausted or `mdbx_env_sync()` is invoked. Total disk usage will be +almost the same as in sync-write mode. -* _libmdbx_ has a mechanism which aborts such operations and `LIFO RECLAIM` - mode which addresses performance degradation. +Current _libmdbx_ gives a choice of safe async-write mode (default) and +`UTTERLY_NOSYNC` mode which may result in full DB corruption during +system crash as with LMDB. -Read operations operate only over snapshot of DB which is consistent on the moment when read transaction started. -This snapshot doesn't change throughout the transaction but this leads to inability to reclaim the pages until -read transaction ends. +Next version of _libmdbx_ will create steady synchronization points +automatically in async-write mode. -In _LMDB_ this leads to a problem that memory pages, allocated for operations during long read, will be used for operations -and won't be reclaimed until DB process terminates. In _LMDB_ they are used in -[FIFO](https://en.wikipedia.org/wiki/FIFO_(computing_and_electronics)) manner, which causes increased page count -and less chance of cache hit during I/O. In other words: one long-time reader can impact performance of all database -until it'll be reopened. +-------------------------------------------------------------------------------- -_libmdbx_ addresses the problem, details below. Illustrations to this problem can be found in the -[presentation](http://www.slideshare.net/leoyuriev/lmdb). There is also example of performance increase thanks to -[BBWC](https://en.wikipedia.org/wiki/Disk_buffer#Write_acceleration) when `LIFO RECLAIM` enabled in _libmdbx_. +Performance comparison +====================== -#### Data safety in async-write mode +All benchmarks were done by [IOArena](https://github.com/pmwkaa/ioarena) +and multiple [scripts](https://github.com/pmwkaa/ioarena/tree/HL%2B%2B2015) +runs on Lenovo Carbon-2 laptop, i7-4600U 2.1 GHz, 8 Gb RAM, +SSD SAMSUNG MZNTD512HAGL-000L1 (DXT23L0Q) 512 Gb. -In `WRITEMAP+MAPSYNC` mode dirty pages are written to persistent storage by kernel. This means that in case of application -crash OS kernel will write all dirty data to disk and nothing will be lost. But in case of hardware malfunction or OS kernel -fatal error only some dirty data might be synced to disk, and there is high probability that pages with metadata saved, -will point to non-saved, hence non-existent, data pages. In such situation, DB is completely corrupted and can't be -repaired even if there was full sync before the crash via `mdbx_env_sync(). +-------------------------------------------------------------------------------- -_libmdbx_ addresses this by fully reimplementing write path of data: +### Integral performance -* In `WRITEMAP+MAPSYNC` mode meta-data pages aren't updated in place, instead their shadow copies are used and their updates - are synced after data is flushed to disk. +Here showed sum of performance metrics in 3 benchmarks: -* During transaction commit _libmdbx_ marks synchronization points as steady or weak depending on how much synchronization - needed between RAM and persistent storage, e.g. in `WRITEMAP+MAPSYNC` commited transactions are marked as weak, - but during explicit data synchronization - as steady. + - Read/Search on 4 CPU cores machine; -* _libmdbx_ maintains three separate meta-pages instead of two. This allows to commit transaction with steady or -weak synchronization point without losing two previous synchronization points (one of them can be steady, and second - weak). -This allows to order weak and steady synchronization points in any order without losing consistency in case of system crash. + - Transactions with [CRUD](https://en.wikipedia.org/wiki/CRUD) + operations in sync-write mode (fdatasync is called after each + transaction); -* During DB open _libmdbx_ rollbacks to the last steady synchronization point, this guarantees database integrity. + - Transactions with [CRUD](https://en.wikipedia.org/wiki/CRUD) + operations in lazy-write mode (moment to sync data to persistent storage + is decided by OS). -For data safety pages which form database snapshot with steady synchronization point must not be updated until next steady -synchronization point. So last steady synchronization point creates "long-time read" effect. The only difference that in case -of memory exhaustion the problem will be immediately addressed by flushing changes to persistent storage and forming new steady -synchronization point. +*Reasons why asynchronous mode isn't benchmarked here:* -So in async-write mode _libmdbx_ will always use new pages until memory is exhausted or `mdbx_env_sync()` is invoked. Total -disk usage will be almost the same as in sync-write mode. + 1. It doesn't make sense as it has to be done with DB engines, oriented + for keeping data in memory e.g. [Tarantool](https://tarantool.io/), + [Redis](https://redis.io/)), etc. -Current _libmdbx_ gives a choice of safe async-write mode (default) and `UTTERLY_NOSYNC` mode which may result in full DB -corruption during system crash as with LMDB. + 2. Performance gap is too high to compare in any meaningful way. -Next version of _libmdbx_ will create steady synchronization points automatically in async-write mode. + -------------------------------------------------------------------------------- -Improvements over LMDB -================================================ - -1. `LIFO RECLAIM` mode: - - The newest pages are picked for reuse instead of the oldest. - This allows to minimize reclaim loop and make it execution time independent of total page count. - - This results in OS kernel cache mechanisms working with maximum efficiency. - In case of using disk controllers or storages with - [BBWC](https://en.wikipedia.org/wiki/Disk_buffer#Write_acceleration) this may greatly improve - write performance. +### Read Scalability -2. `OOM-KICK` callback. +Summary performance with concurrent read/search queries in 1-2-4-8 +threads on 4 CPU cores machine. - `mdbx_env_set_oomfunc()` allows to set a callback, which will be called - in the event of memory exhausting during long-time read transaction. - Callback will be invoked with PID and pthread_id of offending thread as parameters. - Callback can do any of these things to remedy the problem: + - * wait for read transaction to finish normally; +-------------------------------------------------------------------------------- - * kill the offending process (signal 9), if separate process is doing long-time read; +### Sync-write mode - * abort or restart offending read transaction if it's running in sibling thread; + - Linear scale on left and dark rectangles mean arithmetic mean + transactions per second; - * abort current write transaction with returning error code. + - Logarithmic scale on right is in seconds and yellow intervals mean + execution time of transactions. Each interval shows minimal and maximum + execution time, cross marks standard deviation. -3. Guarantee of DB integrity in `WRITEMAP+MAPSYNC` mode: - > Current _libmdbx_ gives a choice of safe async-write mode (default) - > and `UTTERLY_NOSYNC` mode which may result in full - > DB corruption during system crash as with LMDB. For details see - > [Data safety in async-write mode](#data-safety-in-async-write-mode). +**10,000 transactions in sync-write mode**. In case of a crash all data +is consistent and state is right after last successful transaction. +[fdatasync](https://linux.die.net/man/2/fdatasync) syscall is used after +each write transaction in this mode. -4. Automatic creation of synchronization points (flush changes to persistent storage) - when changes reach set threshold (threshold can be set by `mdbx_env_set_syncbytes()`). +In the benchmark each transaction contains combined CRUD operations (2 +inserts, 1 read, 1 update, 1 delete). Benchmark starts on empty database +and after full run the database contains 10,000 small key-value records. -5. Ability to get how far current read-only snapshot is from latest version of the DB by `mdbx_txn_straggler()`. + -6. `mdbx_chk` tool for DB checking and `mdbx_env_pgwalk()` for page-walking all pages in DB. +-------------------------------------------------------------------------------- -7. Control over debugging and receiving of debugging messages via `mdbx_setup_debug()`. +### Lazy-write mode -8. Ability to assign up to 3 markers to commiting transaction with `mdbx_canary_put()` and then get them in read transaction - by `mdbx_canary_get()`. + - Linear scale on left and dark rectangles mean arithmetic mean of + thousands transactions per second; -9. Check if there is a row with data after current cursor position via `mdbx_cursor_eof()`. + - Logarithmic scale on right in seconds and yellow intervals mean + execution time of transactions. Each interval shows minimal and maximum + execution time, cross marks standard deviation. -10. Ability to explicitly request update of present record without creating new record. Implemented as `MDBX_CURRENT` flag - for `mdbx_put()`. +**100,000 transactions in lazy-write mode**. In case of a crash all data +is consistent and state is right after one of last transactions, but +transactions after it will be lost. Other DB engines use +[WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) or transaction +journal for that, which in turn depends on order of operations in +journaled filesystem. _libmdbx_ doesn't use WAL and hands I/O operations +to filesystem and OS kernel (mmap). -11. Ability to update or delete record and get previous value via `mdbx_replace()` Also can update specific multi-value. +In the benchmark each transaction contains combined CRUD operations (2 +inserts, 1 read, 1 update, 1 delete). Benchmark starts on empty database +and after full run the database contains 100,000 small key-value +records. -12. Support for keys and values of zero length, including sorted duplicates. -13. Fixed `mdbx_cursor_count()`, which returns correct count of duplicated for all table types and any cursor position. + -14. Ability to open DB in exclusive mode with `MDBX_EXCLUSIVE` flag, e.g. for integrity check. +-------------------------------------------------------------------------------- -15. Ability to close DB in "dirty" state (without data flush and creation of steady synchronization point) - via `mdbx_env_close_ex()`. +### Async-write mode -16. Ability to get additional info, including number of the oldest snapshot of DB, which is used by one of the readers. - Implemented via `mdbx_env_info()`. + - Linear scale on left and dark rectangles mean arithmetic mean of + thousands transactions per second; -17. `mdbx_del()` doesn't ignore additional argument (specifier) `data` - for tables without duplicates (without flag `MDBX_DUPSORT`), if `data` is not zero then always uses it to verify - record, which is being deleted. + - Logarithmic scale on right in seconds and yellow intervals mean + execution time of transactions. Each interval shows minimal and maximum + execution time, cross marks standard deviation. -18. Ability to open dbi-table with simultaneous setup of comparators for keys and values, via `mdbx_dbi_open_ex()`. +**1,000,000 transactions in async-write mode**. In case of a crash all +data will be consistent and state will be right after one of last +transactions, but lost transaction count is much higher than in +lazy-write mode. All DB engines in this mode do as little writes as +possible on persistent storage. _libmdbx_ uses +[msync(MS_ASYNC)](https://linux.die.net/man/2/msync) in this mode. -19. Ability to find out if key or value is in dirty page. This may be useful to make a decision to avoid - excessive CoW before updates. Implemented via `mdbx_is_dirty()`. +In the benchmark each transaction contains combined CRUD operations (2 +inserts, 1 read, 1 update, 1 delete). Benchmark starts on empty database +and after full run the database contains 10,000 small key-value records. -20. Correct update of current record in `MDBX_CURRENT` mode of `mdbx_cursor_put()`, including sorted duplicated. + -21. All cursors in all read and write transactions can be reused by `mdbx_cursor_renew()` and MUST be freed explicitly. - > ## Caution, please pay attention! - > - > This is the only change of API, which changes semantics of cursor management - > and can lead to memory leaks on misuse. This is a needed change as it eliminates ambiguity - > which helps to avoid such errors as: - > - use-after-free; - > - double-free; - > - memory corruption and segfaults. +-------------------------------------------------------------------------------- -22. Additional error code `MDBX_EMULTIVAL`, which is returned by `mdbx_put()` and - `mdbx_replace()` in case is ambiguous update or delete. +### Cost comparison -23. Ability to get value by key and duplicates count by `mdbx_get_ex()`. +Summary of used resources during lazy-write mode benchmarks: -24. Functions `mdbx_cursor_on_first() and mdbx_cursor_on_last(), which allows to know if cursor is currently on first or - last position respectively. + - Read and write IOPS; -25. If read transaction is aborted via `mdbx_txn_abort()` or `mdbx_txn_reset()` then DBI-handles, which were opened in it, - aren't closed or deleted. This allows to avoid several types of hard-to-debug errors. + - Sum of user CPU time and sys CPU time; -26. Sequence generation via `mdbx_dbi_sequence()`. + - Used space on persistent storage after the test and closed DB, but not + waiting for the end of all internal housekeeping operations (LSM + compactification, etc). -27. Advanced dynamic control over DB size, including ability to choose page size via `mdbx_env_set_geometry()`, - including on Windows. +_ForestDB_ is excluded because benchmark showed it's resource +consumption for each resource (CPU, IOPS) much higher than other engines +which prevents to meaningfully compare it with them. -28. Three meta-pages instead of two, this allows to guarantee consistently update weak sync-points without risking to - corrupt last steady sync-point. +All benchmark data is gathered by +[getrusage()](http://man7.org/linux/man-pages/man2/getrusage.2.html) +syscall and by scanning data directory. -29. Automatic reclaim of freed pages to specific reserved space at the end of database file. This lowers amount of pages, - loaded to memory, used in update/flush loop. In fact _libmdbx_ constantly performs compactification of data, - but doesn't use additional resources for that. Space reclaim of DB and setup of database geometry parameters also decreases - size of the database on disk, including on Windows. + -------------------------------------------------------------------------------- @@ -474,16 +597,3 @@ Idx Name Size VMA LMA File off Algn CONTENTS, ALLOC, LOAD, READONLY, CODE ``` - -``` -$ gcc -v -Using built-in specs. -COLLECT_GCC=gcc -COLLECT_LTO_WRAPPER=/usr/lib/gcc/x86_64-linux-gnu/7/lto-wrapper -OFFLOAD_TARGET_NAMES=nvptx-none -OFFLOAD_TARGET_DEFAULT=1 -Target: x86_64-linux-gnu -Configured with: ../src/configure -v --with-pkgversion='Ubuntu 7.2.0-8ubuntu3' --with-bugurl=file:///usr/share/doc/gcc-7/README.Bugs --enable-languages=c,ada,c++,go,brig,d,fortran,objc,obj-c++ --prefix=/usr --with-gcc-major-version-only --program-suffix=-7 --program-prefix=x86_64-linux-gnu- --enable-shared --enable-linker-build-id --libexecdir=/usr/lib --without-included-gettext --enable-threads=posix --libdir=/usr/lib --enable-nls --with-sysroot=/ --enable-clocale=gnu --enable-libstdcxx-debug --enable-libstdcxx-time=yes --with-default-libstdcxx-abi=new --enable-gnu-unique-object --disable-vtable-verify --enable-libmpx --enable-plugin --enable-default-pie --with-system-zlib --with-target-system-zlib --enable-objc-gc=auto --enable-multiarch --disable-werror --with-arch-32=i686 --with-abi=m64 --with-multilib-list=m32,m64,mx32 --enable-multilib --with-tune=generic --enable-offload-targets=nvptx-none --without-cuda-driver --enable-checking=release --build=x86_64-linux-gnu --host=x86_64-linux-gnu --target=x86_64-linux-gnu -Thread model: posix -gcc version 7.2.0 (Ubuntu 7.2.0-8ubuntu3) -``` diff --git a/libs/libmdbx/src/appveyor.yml b/libs/libmdbx/src/appveyor.yml index d002453fdd..1ee3a467c8 100644 --- a/libs/libmdbx/src/appveyor.yml +++ b/libs/libmdbx/src/appveyor.yml @@ -19,7 +19,7 @@ configuration: platform: - x86 -- x64 +#- x64 #- ARM build_script: diff --git a/libs/libmdbx/src/mdbx.h b/libs/libmdbx/src/mdbx.h index 35faed8488..2d0eeba949 100644 --- a/libs/libmdbx/src/mdbx.h +++ b/libs/libmdbx/src/mdbx.h @@ -493,7 +493,7 @@ typedef struct MDBX_envinfo { uint64_t lower; /* lower limit for datafile size */ uint64_t upper; /* upper limit for datafile size */ uint64_t current; /* current datafile size */ - uint64_t shrink; /* shrink theshold for datafile */ + uint64_t shrink; /* shrink threshold for datafile */ uint64_t grow; /* growth step for datafile */ } mi_geo; uint64_t mi_mapsize; /* Size of the data memory map */ @@ -924,7 +924,6 @@ LIBMDBX_API int mdbx_env_set_maxdbs(MDBX_env *env, MDBX_dbi dbs); * * Returns The maximum size of a key we can write. */ LIBMDBX_API int mdbx_env_get_maxkeysize(MDBX_env *env); -LIBMDBX_API int mdbx_get_maxkeysize(size_t pagesize); /* Set application information associated with the MDBX_env. * @@ -1654,10 +1653,22 @@ typedef void MDBX_debug_func(int type, const char *function, int line, LIBMDBX_API int mdbx_setup_debug(int flags, MDBX_debug_func *logger); -typedef int MDBX_pgvisitor_func(uint64_t pgno, unsigned pgnumber, void *ctx, - const char *dbi, const char *type, - size_t nentries, size_t payload_bytes, - size_t header_bytes, size_t unused_bytes); +typedef enum { + MDBX_page_void, + MDBX_page_meta, + MDBX_page_large, + MDBX_page_branch, + MDBX_page_leaf, + MDBX_page_dupfixed_leaf, + MDBX_subpage_leaf, + MDBX_subpage_dupfixed_leaf +} MDBX_page_type_t; + +typedef int MDBX_pgvisitor_func(uint64_t pgno, unsigned number, void *ctx, + int deep, const char *dbi, size_t page_size, + MDBX_page_type_t type, size_t nentries, + size_t payload_bytes, size_t header_bytes, + size_t unused_bytes); LIBMDBX_API int mdbx_env_pgwalk(MDBX_txn *txn, MDBX_pgvisitor_func *visitor, void *ctx); @@ -1697,6 +1708,13 @@ LIBMDBX_API int mdbx_is_dirty(const MDBX_txn *txn, const void *ptr); LIBMDBX_API int mdbx_dbi_sequence(MDBX_txn *txn, MDBX_dbi dbi, uint64_t *result, uint64_t increment); +LIBMDBX_API int mdbx_limits_pgsize_min(void); +LIBMDBX_API int mdbx_limits_pgsize_max(void); +LIBMDBX_API intptr_t mdbx_limits_dbsize_min(intptr_t pagesize); +LIBMDBX_API intptr_t mdbx_limits_dbsize_max(intptr_t pagesize); +LIBMDBX_API intptr_t mdbx_limits_keysize_max(intptr_t pagesize); +LIBMDBX_API intptr_t mdbx_limits_txnsize_max(intptr_t pagesize); + /*----------------------------------------------------------------------------*/ /* attribute support functions for Nexenta */ typedef uint_fast64_t mdbx_attr_t; diff --git a/libs/libmdbx/src/packages/rpm/CMakeLists.txt b/libs/libmdbx/src/packages/rpm/CMakeLists.txt new file mode 100644 index 0000000000..b664075556 --- /dev/null +++ b/libs/libmdbx/src/packages/rpm/CMakeLists.txt @@ -0,0 +1,193 @@ +cmake_minimum_required(VERSION 2.8.7) +set(TARGET mdbx) +project(${TARGET}) + +message(WARNING " +*************************************************************** + MDBX is under active development, database format and API + aren't stable at least until 2018Q3. New version won't be + backwards compatible. Main focus of the rework is to provide + clear and robust API and new features. +*************************************************************** +") + +set(MDBX_VERSION_MAJOR 0) +set(MDBX_VERSION_MINOR 1) +set(MDBX_VERSION_RELEASE 3) +set(MDBX_VERSION_REVISION 1) + +set(MDBX_VERSION_STRING ${MDBX_VERSION_MAJOR}.${MDBX_VERSION_MINOR}.${MDBX_VERSION_RELEASE}) + +enable_language(C) +enable_language(CXX) + +set(CMAKE_CXX_STANDARD 11) +set(CMAKE_CXX_STANDARD_REQUIRED on) + +add_definitions(-DNDEBUG=1 -DMDBX_DEBUG=0 -DLIBMDBX_EXPORTS=1 -D_GNU_SOURCE=1) + +find_package(Threads REQUIRED) + +get_directory_property(hasParent PARENT_DIRECTORY) +if(hasParent) + set(STANDALONE_BUILD 0) +else() + set(STANDALONE_BUILD 1) + enable_testing() + + if (CMAKE_C_COMPILER_ID MATCHES GNU) + set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -O2") + set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -g3") + set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -Wall") + set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -Werror") + set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -Wextra") + set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -ffunction-sections") + set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -fPIC") + set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -fvisibility=hidden") + set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -std=gnu11") + set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -pthread") + endif() + + if (CMAKE_CXX_COMPILER_ID MATCHES GNU) + set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -W") + set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -Wall") + set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -Werror") + set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -Wpointer-arith") + set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -Wno-sign-compare") + set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -Wformat-security") + set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -Woverloaded-virtual") + set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -Wwrite-strings") + set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fmax-errors=20") + set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fvisibility=hidden") + set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -Wno-unused-parameter -Wunused-function -Wunused-variable -Wunused-value -Wmissing-declarations") + set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -Wno-missing-field-initializers") + set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -Wcast-qual") + set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -ggdb") + set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fno-omit-frame-pointer") + set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -Wno-strict-aliasing") + set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -finline-functions-called-once") + set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -Wno-packed-bitfield-compat") + + set(CMAKE_CXX_FLAGS_DEBUG "-O0 -g3") + set(CMAKE_CXX_FLAGS_RELWITHDEBINFO "-O3 -g3") + endif() + + if (COVERAGE) + if (NOT "${CMAKE_BUILD_TYPE}" STREQUAL "Debug") + message(FATAL_ERROR "Coverage requires -DCMAKE_BUILD_TYPE=Debug Current value=${CMAKE_BUILD_TYPE}") + endif() + + message(STATUS "Setting coverage compiler flags") + set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -g -ggdb3 -O0 --coverage -fprofile-arcs -ftest-coverage") + set(CMAKE_C_FLAGS "${CMAKE_C_FLAGS} -g -ggdb3 -O0 --coverage -fprofile-arcs -ftest-coverage") + add_definitions(-DCOVERAGE_TEST) + endif() + + if (NOT TRAVIS) + set(CMAKE_CXX_FLAGS_DEBUG "${CMAKE_CXX_FLAGS_DEBUG} -fsanitize=address -fsanitize=leak -fstack-protector-strong -static-libasan") + endif() +endif() + +set(${TARGET}_SRC + mdbx.h + src/bits.h + src/defs.h + src/lck-posix.c + src/mdbx.c + src/osal.c + src/osal.h + src/version.c + ) + +add_library(${TARGET}_STATIC STATIC + ${${TARGET}_SRC} + ) + +add_library(${TARGET} ALIAS ${TARGET}_STATIC) + +add_library(${TARGET}_SHARED SHARED + ${${TARGET}_SRC} + ) + +set_target_properties(${TARGET}_SHARED PROPERTIES + VERSION ${MDBX_VERSION_STRING} + SOVERSION ${MDBX_VERSION_MAJOR} + OUTPUT_NAME ${TARGET} + CLEAN_DIRECT_OUTPUT 1 + ) + +set_target_properties(${TARGET}_STATIC PROPERTIES + VERSION ${MDBX_VERSION_STRING} + SOVERSION ${MDBX_VERSION_MAJOR} + OUTPUT_NAME ${TARGET} + CLEAN_DIRECT_OUTPUT 1 + ) + +target_include_directories(${TARGET}_STATIC PUBLIC + ${CMAKE_CURRENT_SOURCE_DIR}) +target_include_directories(${TARGET}_SHARED PUBLIC + ${CMAKE_CURRENT_SOURCE_DIR}) + +target_link_libraries(${TARGET}_STATIC ${CMAKE_THREAD_LIBS_INIT}) +target_link_libraries(${TARGET}_SHARED ${CMAKE_THREAD_LIBS_INIT}) +if(UNIX AND NOT APPLE) + target_link_libraries(${TARGET}_STATIC rt) + target_link_libraries(${TARGET}_SHARED rt) +endif() + +install(TARGETS ${TARGET}_STATIC DESTINATION ${CMAKE_INSTALL_PREFIX}/lib64 COMPONENT mdbx) +install(TARGETS ${TARGET}_SHARED DESTINATION ${CMAKE_INSTALL_PREFIX}/lib64 COMPONENT mdbx) +install(FILES mdbx.h DESTINATION ${CMAKE_INSTALL_PREFIX}/include COMPONENT mdbx-devel) + +add_subdirectory(src/tools) +add_subdirectory(test) +add_subdirectory(test/pcrf) +add_subdirectory(tutorial) + +############################################################################## + +set(CPACK_GENERATOR "RPM") +set(CPACK_RPM_COMPONENT_INSTALL ON) + +# Version +if (NOT "$ENV{BUILD_NUMBER}" STREQUAL "") + set(CPACK_PACKAGE_RELEASE $ENV{BUILD_NUMBER}) +else() + if (NOT "$ENV{CI_PIPELINE_ID}" STREQUAL "") + set(CPACK_PACKAGE_RELEASE $ENV{CI_PIPELINE_ID}) + else() + set(CPACK_PACKAGE_RELEASE 1) + endif() +endif() +set(CPACK_RPM_PACKAGE_RELEASE ${CPACK_PACKAGE_RELEASE}) + +set(CPACK_PACKAGE_VERSION ${MDBX_VERSION_STRING}) +set(CPACK_PACKAGE_VERSION_FULL ${CPACK_PACKAGE_VERSION}-${CPACK_PACKAGE_RELEASE}) + +set(CPACK_RPM_mdbx-devel_PACKAGE_REQUIRES "mdbx = ${CPACK_PACKAGE_VERSION}") + +set(CPACK_RPM_SPEC_INSTALL_POST "/bin/true") +set(CPACK_RPM_mdbx_PACKAGE_NAME mdbx) +set(CPACK_RPM_mdbx-devel_PACKAGE_NAME mdbx-devel) +set(CPACK_PACKAGE_DESCRIPTION_SUMMARY "The revised and extended descendant of Symas LMDB") + +set(CPACK_PACKAGE_VENDOR "???") +set(CPACK_PACKAGE_CONTACT "Vladimir Romanov") +set(CPACK_PACKAGE_RELOCATABLE false) +set(CPACK_RPM_PACKAGE_ARCHITECTURE "x86_64") +set(CPACK_RPM_PACKAGE_REQUIRES "") +set(CPACK_RPM_PACKAGE_GROUP "Applications/Database") + +set(CPACK_RPM_mdbx_FILE_NAME "${CPACK_RPM_mdbx_PACKAGE_NAME}-${CPACK_PACKAGE_VERSION_FULL}.${CPACK_RPM_PACKAGE_ARCHITECTURE}.rpm") +set(CPACK_RPM_mdbx-devel_FILE_NAME "${CPACK_RPM_mdbx-devel_PACKAGE_NAME}-${CPACK_PACKAGE_VERSION_FULL}.${CPACK_RPM_PACKAGE_ARCHITECTURE}.rpm") + +set(CPACK_RPM_EXCLUDE_FROM_AUTO_FILELIST_ADDITION + /usr/local + /usr/local/bin + /usr/local/lib64 + /usr/local/include + /usr/local/man + /usr/local/man/man1 + ) + +include(CPack) diff --git a/libs/libmdbx/src/packages/rpm/build.sh b/libs/libmdbx/src/packages/rpm/build.sh new file mode 100644 index 0000000000..5170882265 --- /dev/null +++ b/libs/libmdbx/src/packages/rpm/build.sh @@ -0,0 +1,18 @@ +#!/bin/bash +set -e +CONFIG=$1 + +if [[ -z "${CONFIG}" ]]; then + CONFIG=Debug +fi +if [[ -r /opt/rh/devtoolset-6/enable ]]; then + source /opt/rh/devtoolset-6/enable +fi +#rm -f -r build || true +mkdir -p cmake-build-${CONFIG} +pushd cmake-build-${CONFIG} &> /dev/null +if [[ ! -r Makefile ]]; then + cmake .. -DCMAKE_BUILD_TYPE=${CONFIG} +fi +make -j8 || exit 1 +popd &> /dev/null diff --git a/libs/libmdbx/src/packages/rpm/package.sh b/libs/libmdbx/src/packages/rpm/package.sh new file mode 100644 index 0000000000..d7f9ab297a --- /dev/null +++ b/libs/libmdbx/src/packages/rpm/package.sh @@ -0,0 +1,25 @@ +#!/bin/bash +set -e + +CONFIG=$1 + +if [[ -z "${CONFIG}" ]]; then + CONFIG=Debug +fi + +DIRNAME=`dirname ${BASH_SOURCE[0]}` +DIRNAME=`readlink --canonicalize ${DIRNAME}` + +if [[ -r /opt/rh/devtoolset-6/enable ]]; then + source /opt/rh/devtoolset-6/enable +fi + +mkdir -p cmake-build-${CONFIG} +pushd cmake-build-${CONFIG} &> /dev/null +if [[ ! -r Makefile ]]; then + cmake .. -DCMAKE_BUILD_TYPE=${CONFIG} +fi +rm -f *.rpm +make -j8 package || exit 1 +rm -f *-Unspecified.rpm +popd &> /dev/null diff --git a/libs/libmdbx/src/src/bits.h b/libs/libmdbx/src/src/bits.h index 955a583264..f3f0bcea97 100644 --- a/libs/libmdbx/src/src/bits.h +++ b/libs/libmdbx/src/src/bits.h @@ -120,6 +120,12 @@ /* *INDENT-ON* */ /* clang-format on */ +#if UINTPTR_MAX > 0xffffFFFFul || ULONG_MAX > 0xffffFFFFul +#define MDBX_WORDBITS 64 +#else +#define MDBX_WORDBITS 32 +#endif /* MDBX_WORDBITS */ + /*----------------------------------------------------------------------------*/ /* Basic constants and types */ @@ -163,7 +169,7 @@ * size up to 2^44 bytes, in case of 4K pages. */ typedef uint32_t pgno_t; #define PRIaPGNO PRIu32 -#define MAX_PAGENO ((pgno_t)UINT64_C(0xffffFFFFffff)) +#define MAX_PAGENO UINT32_C(0x7FFFffff) #define MIN_PAGENO NUM_METAS /* A transaction ID. */ @@ -392,11 +398,13 @@ typedef struct MDBX_page { #else #define MAX_MAPSIZE32 UINT32_C(0x7ff80000) #endif -#define MAX_MAPSIZE64 \ - ((sizeof(pgno_t) > 4) ? UINT64_C(0x7fffFFFFfff80000) \ - : MAX_PAGENO * (uint64_t)MAX_PAGESIZE) +#define MAX_MAPSIZE64 (MAX_PAGENO * (uint64_t)MAX_PAGESIZE) -#define MAX_MAPSIZE ((sizeof(size_t) < 8) ? MAX_MAPSIZE32 : MAX_MAPSIZE64) +#if MDBX_WORDBITS >= 64 +#define MAX_MAPSIZE MAX_MAPSIZE64 +#else +#define MAX_MAPSIZE MAX_MAPSIZE32 +#endif /* MDBX_WORDBITS */ /* The header for the reader table (a memory-mapped lock file). */ typedef struct MDBX_lockinfo { @@ -473,6 +481,10 @@ typedef struct MDBX_lockinfo { #define MDBX_LOCK_MAGIC ((MDBX_MAGIC << 8) + MDBX_LOCK_VERSION) #define MDBX_LOCK_DEBUG ((MDBX_MAGIC << 8) + 255) +#ifndef MDBX_ASSUME_MALLOC_OVERHEAD +#define MDBX_ASSUME_MALLOC_OVERHEAD (sizeof(void *) * 2u) +#endif /* MDBX_ASSUME_MALLOC_OVERHEAD */ + /*----------------------------------------------------------------------------*/ /* Two kind lists of pages (aka PNL) */ @@ -494,35 +506,46 @@ typedef pgno_t *MDBX_PNL; /* List of txnid, only for MDBX_env.mt_lifo_reclaimed */ typedef txnid_t *MDBX_TXL; -/* An ID2 is an ID/pointer pair. */ -typedef struct MDBX_ID2 { - pgno_t mid; /* The ID */ - void *mptr; /* The pointer */ -} MDBX_ID2; - -/* An ID2L is an ID2 List, a sorted array of ID2s. - * The first element's mid member is a count of how many actual - * elements are in the array. The mptr member of the first element is - * unused. The array is sorted in ascending order by mid. */ -typedef MDBX_ID2 *MDBX_ID2L; - -/* PNL sizes - likely should be even bigger - * limiting factors: sizeof(pgno_t), thread stack size */ -#define MDBX_PNL_LOGN 16 /* DB_SIZE is 2^16, UM_SIZE is 2^17 */ -#define MDBX_PNL_DB_SIZE (1 << MDBX_PNL_LOGN) -#define MDBX_PNL_UM_SIZE (1 << (MDBX_PNL_LOGN + 1)) - -#define MDBX_PNL_DB_MAX (MDBX_PNL_DB_SIZE - 1) -#define MDBX_PNL_UM_MAX (MDBX_PNL_UM_SIZE - 1) - -#define MDBX_PNL_SIZEOF(pl) (((pl)[0] + 1) * sizeof(pgno_t)) -#define MDBX_PNL_IS_ZERO(pl) ((pl)[0] == 0) -#define MDBX_PNL_CPY(dst, src) (memcpy(dst, src, MDBX_PNL_SIZEOF(src))) -#define MDBX_PNL_FIRST(pl) ((pl)[1]) -#define MDBX_PNL_LAST(pl) ((pl)[(pl)[0]]) +/* An Dirty-Page list item is an pgno/pointer pair. */ +typedef union MDBX_DP { + struct { + pgno_t pgno; + void *ptr; + }; + struct { + pgno_t unused; + unsigned length; + }; +} MDBX_DP; + +/* An DPL (dirty-page list) is a sorted array of MDBX_DPs. + * The first element's length member is a count of how many actual + * elements are in the array. */ +typedef MDBX_DP *MDBX_DPL; + +/* PNL sizes - likely should be even bigger */ +#define MDBX_PNL_GRANULATE 1024 +#define MDBX_PNL_INITIAL \ + (MDBX_PNL_GRANULATE - 2 - MDBX_ASSUME_MALLOC_OVERHEAD / sizeof(pgno_t)) +#define MDBX_PNL_MAX \ + ((1u << 24) - 2 - MDBX_ASSUME_MALLOC_OVERHEAD / sizeof(pgno_t)) +#define MDBX_DPL_TXNFULL (MDBX_PNL_MAX / 4) + +#define MDBX_TXL_GRANULATE 32 +#define MDBX_TXL_INITIAL \ + (MDBX_TXL_GRANULATE - 2 - MDBX_ASSUME_MALLOC_OVERHEAD / sizeof(txnid_t)) +#define MDBX_TXL_MAX \ + ((1u << 17) - 2 - MDBX_ASSUME_MALLOC_OVERHEAD / sizeof(txnid_t)) -/* Current max length of an mdbx_pnl_alloc()ed PNL */ #define MDBX_PNL_ALLOCLEN(pl) ((pl)[-1]) +#define MDBX_PNL_SIZE(pl) ((pl)[0]) +#define MDBX_PNL_FIRST(pl) ((pl)[1]) +#define MDBX_PNL_LAST(pl) ((pl)[MDBX_PNL_SIZE(pl)]) +#define MDBX_PNL_BEGIN(pl) (&(pl)[1]) +#define MDBX_PNL_END(pl) (&(pl)[MDBX_PNL_SIZE(pl) + 1]) + +#define MDBX_PNL_SIZEOF(pl) ((MDBX_PNL_SIZE(pl) + 1) * sizeof(pgno_t)) +#define MDBX_PNL_IS_EMPTY(pl) (MDBX_PNL_SIZE(pl) == 0) /*----------------------------------------------------------------------------*/ /* Internal structures */ @@ -566,7 +589,7 @@ struct MDBX_txn { MDBX_PNL mt_spill_pages; union { /* For write txns: Modified pages. Sorted when not MDBX_WRITEMAP. */ - MDBX_ID2L mt_rw_dirtylist; + MDBX_DPL mt_rw_dirtylist; /* For read txns: This thread/txn's reader table slot, or NULL. */ MDBX_reader *mt_ro_reader; }; @@ -664,8 +687,9 @@ struct MDBX_cursor { #define C_EOF 0x02 /* No more data */ #define C_SUB 0x04 /* Cursor is a sub-cursor */ #define C_DEL 0x08 /* last op was a cursor_del */ -#define C_UNTRACK 0x40 /* Un-track cursor when closing */ -#define C_RECLAIMING 0x80 /* FreeDB lookup is prohibited */ +#define C_UNTRACK 0x10 /* Un-track cursor when closing */ +#define C_RECLAIMING 0x20 /* FreeDB lookup is prohibited */ +#define C_GCFREEZE 0x40 /* me_reclaimed_pglist must not be updated */ unsigned mc_flags; /* see mdbx_cursor */ MDBX_page *mc_pg[CURSOR_STACK]; /* stack of pushed pages */ indx_t mc_ki[CURSOR_STACK]; /* stack of page indices */ @@ -686,6 +710,11 @@ typedef struct MDBX_xcursor { uint8_t mx_dbflag; } MDBX_xcursor; +typedef struct MDBX_cursor_couple { + MDBX_cursor outer; + MDBX_xcursor inner; +} MDBX_cursor_couple; + /* Check if there is an inited xcursor, so XCURSOR_REFRESH() is proper */ #define XCURSOR_INITED(mc) \ ((mc)->mc_xcursor && ((mc)->mc_xcursor->mx_cursor.mc_flags & C_INITIALIZED)) @@ -757,10 +786,10 @@ struct MDBX_env { MDBX_page *me_dpages; /* list of malloc'd blocks for re-use */ /* PNL of pages that became unused in a write txn */ MDBX_PNL me_free_pgs; - /* ID2L of pages written during a write txn. Length MDBX_PNL_UM_SIZE. */ - MDBX_ID2L me_dirtylist; - /* Max number of freelist items that can fit in a single overflow page */ - unsigned me_maxfree_1pg; + /* MDBX_DP of pages written during a write txn. Length MDBX_DPL_TXNFULL. */ + MDBX_DPL me_dirtylist; + /* Number of freelist items that can fit in a single overflow page */ + unsigned me_maxgc_ov1page; /* Max size of a node on a page */ unsigned me_nodemax; unsigned me_maxkey_limit; /* max size of a key */ @@ -1031,7 +1060,7 @@ static __inline unsigned mdbx_log2(size_t value) { #define NUMKEYS(p) ((unsigned)(p)->mp_lower >> 1) /* The amount of space remaining in the page */ -#define SIZELEFT(p) (indx_t)((p)->mp_upper - (p)->mp_lower) +#define SIZELEFT(p) ((indx_t)((p)->mp_upper - (p)->mp_lower)) /* The percentage of space used in the page, in tenths of a percent. */ #define PAGEFILL(env, p) \ @@ -1042,15 +1071,19 @@ static __inline unsigned mdbx_log2(size_t value) { #define FILL_THRESHOLD 256 /* Test if a page is a leaf page */ -#define IS_LEAF(p) F_ISSET((p)->mp_flags, P_LEAF) +#define IS_LEAF(p) (((p)->mp_flags & P_LEAF) != 0) /* Test if a page is a LEAF2 page */ -#define IS_LEAF2(p) F_ISSET((p)->mp_flags, P_LEAF2) +#define IS_LEAF2(p) unlikely(((p)->mp_flags & P_LEAF2) != 0) /* Test if a page is a branch page */ -#define IS_BRANCH(p) F_ISSET((p)->mp_flags, P_BRANCH) +#define IS_BRANCH(p) (((p)->mp_flags & P_BRANCH) != 0) /* Test if a page is an overflow page */ -#define IS_OVERFLOW(p) unlikely(F_ISSET((p)->mp_flags, P_OVERFLOW)) +#define IS_OVERFLOW(p) unlikely(((p)->mp_flags & P_OVERFLOW) != 0) /* Test if a page is a sub page */ -#define IS_SUBP(p) F_ISSET((p)->mp_flags, P_SUBP) +#define IS_SUBP(p) (((p)->mp_flags & P_SUBP) != 0) +/* Test if a page is dirty */ +#define IS_DIRTY(p) (((p)->mp_flags & P_DIRTY) != 0) + +#define PAGETYPE(p) ((p)->mp_flags & (P_BRANCH | P_LEAF | P_LEAF2 | P_OVERFLOW)) /* The number of overflow pages needed to store the given size. */ #define OVPAGES(env, size) (bytes2pgno(env, PAGEHDRSZ - 1 + (size)) + 1) @@ -1270,3 +1303,26 @@ static __inline size_t pgno_align2os_bytes(const MDBX_env *env, pgno_t pgno) { static __inline pgno_t pgno_align2os_pgno(const MDBX_env *env, pgno_t pgno) { return bytes2pgno(env, pgno_align2os_bytes(env, pgno)); } + +/* Do not spill pages to disk if txn is getting full, may fail instead */ +#define MDBX_NOSPILL 0x8000 + +/* Perform act while tracking temporary cursor mn */ +#define WITH_CURSOR_TRACKING(mn, act) \ + do { \ + mdbx_cassert(&(mn), \ + mn.mc_txn->mt_cursors != NULL /* must be not rdonly txt */); \ + MDBX_cursor mc_dummy, *tracked, \ + **tp = &(mn).mc_txn->mt_cursors[mn.mc_dbi]; \ + if ((mn).mc_flags & C_SUB) { \ + mc_dummy.mc_flags = C_INITIALIZED; \ + mc_dummy.mc_xcursor = (MDBX_xcursor *)&(mn); \ + tracked = &mc_dummy; \ + } else { \ + tracked = &(mn); \ + } \ + tracked->mc_next = *tp; \ + *tp = tracked; \ + { act; } \ + *tp = tracked->mc_next; \ + } while (0) diff --git a/libs/libmdbx/src/src/defs.h b/libs/libmdbx/src/src/defs.h index b6076cc1b3..4b045efc1d 100644 --- a/libs/libmdbx/src/src/defs.h +++ b/libs/libmdbx/src/src/defs.h @@ -327,6 +327,13 @@ # define mdbx_func_ "<mdbx_unknown>" #endif +#if defined(__GNUC__) || __has_attribute(format) +#define __printf_args(format_index, first_arg) \ + __attribute__((format(printf, format_index, first_arg))) +#else +#define __printf_args(format_index, first_arg) +#endif + /*----------------------------------------------------------------------------*/ #if defined(USE_VALGRIND) diff --git a/libs/libmdbx/src/src/lck-posix.c b/libs/libmdbx/src/src/lck-posix.c index 869b98c054..0aa9d85078 100644 --- a/libs/libmdbx/src/src/lck-posix.c +++ b/libs/libmdbx/src/src/lck-posix.c @@ -48,7 +48,7 @@ static __cold __attribute__((destructor)) void mdbx_global_destructor(void) { #endif #define LCK_WHOLE OFF_T_MAX -static int mdbx_lck_op(mdbx_filehandle_t fd, int op, int lck, off_t offset, +static int mdbx_lck_op(mdbx_filehandle_t fd, int op, short lck, off_t offset, off_t len) { for (;;) { int rc; @@ -68,11 +68,19 @@ static int mdbx_lck_op(mdbx_filehandle_t fd, int op, int lck, off_t offset, } } -static __inline int mdbx_lck_exclusive(int lfd) { +static __inline int mdbx_lck_exclusive(int lfd, bool fallback2shared) { assert(lfd != INVALID_HANDLE_VALUE); if (flock(lfd, LOCK_EX | LOCK_NB)) return errno; - return mdbx_lck_op(lfd, F_SETLK, F_WRLCK, 0, 1); + int rc = mdbx_lck_op(lfd, F_SETLK, F_WRLCK, 0, 1); + if (rc != 0 && fallback2shared) { + while (flock(lfd, LOCK_SH)) { + int rc = errno; + if (rc != EINTR) + return rc; + } + } + return rc; } static __inline int mdbx_lck_shared(int lfd) { @@ -90,8 +98,6 @@ int mdbx_lck_downgrade(MDBX_env *env, bool complete) { return complete ? mdbx_lck_shared(env->me_lfd) : MDBX_SUCCESS; } -int mdbx_lck_upgrade(MDBX_env *env) { return mdbx_lck_exclusive(env->me_lfd); } - int mdbx_rpid_set(MDBX_env *env) { assert(env->me_lfd != INVALID_HANDLE_VALUE); return mdbx_lck_op(env->me_lfd, F_SETLK, F_WRLCK, env->me_pid, 1); @@ -150,6 +156,10 @@ int __cold mdbx_lck_init(MDBX_env *env) { goto bailout; #endif /* PTHREAD_PRIO_INHERIT */ + rc = pthread_mutexattr_settype(&ma, PTHREAD_MUTEX_ERRORCHECK); + if (rc) + goto bailout; + rc = pthread_mutex_init(&env->me_lck->mti_rmutex, &ma); if (rc) goto bailout; @@ -163,7 +173,7 @@ bailout: void __cold mdbx_lck_destroy(MDBX_env *env) { if (env->me_lfd != INVALID_HANDLE_VALUE) { /* try get exclusive access */ - if (env->me_lck && mdbx_lck_exclusive(env->me_lfd) == 0) { + if (env->me_lck && mdbx_lck_exclusive(env->me_lfd, false) == 0) { mdbx_info("%s: got exclusive, drown mutexes", mdbx_func_); int rc = pthread_mutex_destroy(&env->me_lck->mti_rmutex); if (rc == 0) @@ -232,7 +242,7 @@ static int __cold internal_seize_lck(int lfd) { assert(lfd != INVALID_HANDLE_VALUE); /* try exclusive access */ - int rc = mdbx_lck_exclusive(lfd); + int rc = mdbx_lck_exclusive(lfd, false); if (rc == 0) /* got exclusive */ return MDBX_RESULT_TRUE; @@ -241,7 +251,7 @@ static int __cold internal_seize_lck(int lfd) { rc = mdbx_lck_shared(lfd); if (rc == 0) { /* got shared, try exclusive again */ - rc = mdbx_lck_exclusive(lfd); + rc = mdbx_lck_exclusive(lfd, true); if (rc == 0) /* now got exclusive */ return MDBX_RESULT_TRUE; diff --git a/libs/libmdbx/src/src/lck-windows.c b/libs/libmdbx/src/src/lck-windows.c index 02b074e9fc..7da0755916 100644 --- a/libs/libmdbx/src/src/lck-windows.c +++ b/libs/libmdbx/src/src/lck-windows.c @@ -457,51 +457,6 @@ int mdbx_lck_downgrade(MDBX_env *env, bool complete) { return MDBX_SUCCESS /* 7) now at S-? (used), done */; } -int mdbx_lck_upgrade(MDBX_env *env) { - /* Transite from locked state (S-E) to exclusive-write (E-E) */ - assert(env->me_fd != INVALID_HANDLE_VALUE); - assert(env->me_lfd != INVALID_HANDLE_VALUE); - assert((env->me_flags & MDBX_EXCLUSIVE) == 0); - - if (env->me_flags & MDBX_EXCLUSIVE) - return MDBX_RESULT_TRUE /* files were must be opened non-shareable */; - - /* 1) must be at S-E (locked), transite to ?_E (middle) */ - if (!funlock(env->me_lfd, LCK_LOWER)) - mdbx_panic("%s(%s) failed: errcode %u", mdbx_func_, - "S-E(locked) >> ?-E(middle)", GetLastError()); - - /* 3) now on ?-E (middle), try E-E (exclusive-write) */ - mdbx_jitter4testing(false); - if (flock(env->me_lfd, LCK_EXCLUSIVE | LCK_DONTWAIT, LCK_LOWER)) - return MDBX_RESULT_TRUE; /* 4) got E-E (exclusive-write), done */ - - /* 5) still on ?-E (middle) */ - int rc = GetLastError(); - mdbx_jitter4testing(false); - if (rc != ERROR_SHARING_VIOLATION && rc != ERROR_LOCK_VIOLATION) { - /* 6) something went wrong, report but continue */ - mdbx_error("%s(%s) failed: errcode %u", mdbx_func_, - "?-E(middle) >> E-E(exclusive-write)", rc); - } - - /* 7) still on ?-E (middle), try restore S-E (locked) */ - mdbx_jitter4testing(false); - rc = flock(env->me_lfd, LCK_SHARED | LCK_DONTWAIT, LCK_LOWER) - ? MDBX_RESULT_FALSE - : GetLastError(); - - mdbx_jitter4testing(false); - if (rc != MDBX_RESULT_FALSE) { - mdbx_fatal("%s(%s) failed: errcode %u", mdbx_func_, - "?-E(middle) >> S-E(locked)", rc); - return rc; - } - - /* 8) now on S-E (locked) */ - return MDBX_RESULT_FALSE; -} - void mdbx_lck_destroy(MDBX_env *env) { int rc; diff --git a/libs/libmdbx/src/src/mdbx.c b/libs/libmdbx/src/src/mdbx.c index 57d6ec1928..3d576eca68 100644 --- a/libs/libmdbx/src/src/mdbx.c +++ b/libs/libmdbx/src/src/mdbx.c @@ -1,4 +1,4 @@ -/* +/* * Copyright 2015-2018 Leonid Yuriev <leo@yuriev.ru> * and other libmdbx authors: please see AUTHORS file. * All rights reserved. @@ -497,63 +497,183 @@ __cold void mdbx_rthc_remove(const mdbx_thread_key_t key) { /*----------------------------------------------------------------------------*/ -/* Allocate an PNL. - * Allocates memory for an PNL of the given size. - * Returns PNL on success, NULL on failure. */ +static __inline size_t pnl2bytes(const size_t size) { + assert(size > 0 && size <= MDBX_PNL_MAX * 2); + size_t bytes = + mdbx_roundup2(MDBX_ASSUME_MALLOC_OVERHEAD + sizeof(pgno_t) * (size + 2), + MDBX_PNL_GRANULATE * sizeof(pgno_t)) - + MDBX_ASSUME_MALLOC_OVERHEAD; + return bytes; +} + +static __inline pgno_t bytes2pnl(const size_t bytes) { + size_t size = bytes / sizeof(pgno_t); + assert(size > 2 && size <= MDBX_PNL_MAX * 2); + return (pgno_t)size - 2; +} + static MDBX_PNL mdbx_pnl_alloc(size_t size) { - MDBX_PNL pl = malloc((size + 2) * sizeof(pgno_t)); + const size_t bytes = pnl2bytes(size); + MDBX_PNL pl = malloc(bytes); if (likely(pl)) { - *pl++ = (pgno_t)size; - *pl = 0; +#if __GLIBC_PREREQ(2, 12) + const size_t bytes = malloc_usable_size(pl); +#endif + pl[0] = bytes2pnl(bytes); + assert(pl[0] >= size); + pl[1] = 0; + pl += 1; } return pl; } -static MDBX_TXL mdbx_txl_alloc(void) { - const size_t malloc_overhead = sizeof(void *) * 2; - const size_t bytes = mdbx_roundup2(malloc_overhead + sizeof(txnid_t) * 61, - MDBX_CACHELINE_SIZE) - - malloc_overhead; - MDBX_TXL ptr = malloc(bytes); - if (likely(ptr)) { - *ptr++ = bytes / sizeof(txnid_t) - 2; - *ptr = 0; - } - return ptr; -} - -/* Free an PNL. - * [in] pl The PNL to free. */ static void mdbx_pnl_free(MDBX_PNL pl) { if (likely(pl)) free(pl - 1); } -static void mdbx_txl_free(MDBX_TXL list) { - if (likely(list)) - free(list - 1); +/* Shrink the PNL to the default size if it has grown larger */ +static void mdbx_pnl_shrink(MDBX_PNL *ppl) { + assert(bytes2pnl(pnl2bytes(MDBX_PNL_INITIAL)) == MDBX_PNL_INITIAL); + assert(MDBX_PNL_SIZE(*ppl) <= MDBX_PNL_MAX && + MDBX_PNL_ALLOCLEN(*ppl) >= MDBX_PNL_SIZE(*ppl)); + MDBX_PNL_SIZE(*ppl) = 0; + if (unlikely(MDBX_PNL_ALLOCLEN(*ppl) > + MDBX_PNL_INITIAL + MDBX_CACHELINE_SIZE / sizeof(pgno_t))) { + const size_t bytes = pnl2bytes(MDBX_PNL_INITIAL); + MDBX_PNL pl = realloc(*ppl - 1, bytes); + if (likely(pl)) { +#if __GLIBC_PREREQ(2, 12) + const size_t bytes = malloc_usable_size(pl); +#endif + *pl = bytes2pnl(bytes); + *ppl = pl + 1; + } + } +} + +/* Grow the PNL to the size growed to at least given size */ +static int mdbx_pnl_reserve(MDBX_PNL *ppl, const size_t wanna) { + const size_t allocated = MDBX_PNL_ALLOCLEN(*ppl); + assert(MDBX_PNL_SIZE(*ppl) <= MDBX_PNL_MAX && + MDBX_PNL_ALLOCLEN(*ppl) >= MDBX_PNL_SIZE(*ppl)); + if (likely(allocated >= wanna)) + return MDBX_SUCCESS; + + if (unlikely(wanna > /* paranoia */ MDBX_PNL_MAX)) + return MDBX_TXN_FULL; + + const size_t size = (wanna + wanna - allocated < MDBX_PNL_MAX) + ? wanna + wanna - allocated + : MDBX_PNL_MAX; + const size_t bytes = pnl2bytes(size); + MDBX_PNL pl = realloc(*ppl - 1, bytes); + if (likely(pl)) { +#if __GLIBC_PREREQ(2, 12) + const size_t bytes = malloc_usable_size(pl); +#endif + *pl = bytes2pnl(bytes); + assert(*pl >= wanna); + *ppl = pl + 1; + return MDBX_SUCCESS; + } + return MDBX_ENOMEM; +} + +/* Make room for num additional elements in an PNL */ +static __inline int __must_check_result mdbx_pnl_need(MDBX_PNL *ppl, + size_t num) { + assert(MDBX_PNL_SIZE(*ppl) <= MDBX_PNL_MAX && + MDBX_PNL_ALLOCLEN(*ppl) >= MDBX_PNL_SIZE(*ppl)); + assert(num <= MDBX_PNL_MAX); + const size_t wanna = MDBX_PNL_SIZE(*ppl) + num; + return likely(MDBX_PNL_ALLOCLEN(*ppl) >= wanna) + ? MDBX_SUCCESS + : mdbx_pnl_reserve(ppl, wanna); } -/* Append ID to PNL. The PNL must be big enough. */ static __inline void mdbx_pnl_xappend(MDBX_PNL pl, pgno_t id) { - assert(pl[0] + (size_t)1 < MDBX_PNL_ALLOCLEN(pl)); - pl[pl[0] += 1] = id; + assert(MDBX_PNL_SIZE(pl) < MDBX_PNL_ALLOCLEN(pl)); + MDBX_PNL_SIZE(pl) += 1; + MDBX_PNL_LAST(pl) = id; } -static bool mdbx_pnl_check(MDBX_PNL pl) { +/* Append an ID onto an PNL */ +static int __must_check_result mdbx_pnl_append(MDBX_PNL *ppl, pgno_t id) { + /* Too big? */ + if (unlikely(MDBX_PNL_SIZE(*ppl) == MDBX_PNL_ALLOCLEN(*ppl))) { + int rc = mdbx_pnl_need(ppl, MDBX_PNL_GRANULATE); + if (unlikely(rc != MDBX_SUCCESS)) + return rc; + } + mdbx_pnl_xappend(*ppl, id); + return MDBX_SUCCESS; +} + +/* Append an PNL onto an PNL */ +static int __must_check_result mdbx_pnl_append_list(MDBX_PNL *ppl, + MDBX_PNL append) { + int rc = mdbx_pnl_need(ppl, MDBX_PNL_SIZE(append)); + if (unlikely(rc != MDBX_SUCCESS)) + return rc; + + memcpy(MDBX_PNL_END(*ppl), MDBX_PNL_BEGIN(append), + MDBX_PNL_SIZE(append) * sizeof(pgno_t)); + MDBX_PNL_SIZE(*ppl) += MDBX_PNL_SIZE(append); + return MDBX_SUCCESS; +} + +/* Append an ID range onto an PNL */ +static int __must_check_result mdbx_pnl_append_range(MDBX_PNL *ppl, pgno_t id, + size_t n) { + int rc = mdbx_pnl_need(ppl, n); + if (unlikely(rc != MDBX_SUCCESS)) + return rc; + + pgno_t *ap = MDBX_PNL_END(*ppl); + MDBX_PNL_SIZE(*ppl) += (unsigned)n; + for (pgno_t *const end = MDBX_PNL_END(*ppl); ap < end;) + *ap++ = id++; + return MDBX_SUCCESS; +} + +static bool mdbx_pnl_check(MDBX_PNL pl, bool allocated) { if (pl) { - for (const pgno_t *ptr = pl + pl[0]; --ptr > pl;) { - assert(MDBX_PNL_ORDERED(ptr[0], ptr[1])); - assert(ptr[0] >= NUM_METAS); - if (unlikely(MDBX_PNL_DISORDERED(ptr[0], ptr[1]) || ptr[0] < NUM_METAS)) + assert(MDBX_PNL_SIZE(pl) <= MDBX_PNL_MAX); + if (allocated) { + assert(MDBX_PNL_ALLOCLEN(pl) >= MDBX_PNL_SIZE(pl)); + } + for (const pgno_t *scan = &MDBX_PNL_LAST(pl); --scan > pl;) { + assert(MDBX_PNL_ORDERED(scan[0], scan[1])); + assert(scan[0] >= NUM_METAS); + if (unlikely(MDBX_PNL_DISORDERED(scan[0], scan[1]) || + scan[0] < NUM_METAS)) return false; } } return true; } -/* Sort an PNL. - * [in,out] pnl The PNL to sort. */ +/* Merge an PNL onto an PNL. The destination PNL must be big enough */ +static void __hot mdbx_pnl_xmerge(MDBX_PNL pnl, MDBX_PNL merge) { + assert(mdbx_pnl_check(pnl, true)); + assert(mdbx_pnl_check(merge, false)); + pgno_t old_id, merge_id, i = MDBX_PNL_SIZE(merge), j = MDBX_PNL_SIZE(pnl), + k = i + j, total = k; + pnl[0] = + MDBX_PNL_ASCENDING ? 0 : ~(pgno_t)0; /* delimiter for pl scan below */ + old_id = pnl[j]; + while (i) { + merge_id = merge[i--]; + for (; MDBX_PNL_ORDERED(merge_id, old_id); old_id = pnl[--j]) + pnl[k--] = old_id; + pnl[k--] = merge_id; + } + MDBX_PNL_SIZE(pnl) = total; + assert(mdbx_pnl_check(pnl, true)); +} + +/* Sort an PNL */ static void __hot mdbx_pnl_sort(MDBX_PNL pnl) { /* Max possible depth of int-indexed tree * 2 items/level */ int istack[sizeof(int) * CHAR_BIT * 2]; @@ -569,7 +689,7 @@ static void __hot mdbx_pnl_sort(MDBX_PNL pnl) { (b) = tmp_pgno; \ } while (0) - ir = (int)pnl[0]; + ir = (int)MDBX_PNL_SIZE(pnl); l = 1; jstack = 0; while (1) { @@ -629,7 +749,7 @@ static void __hot mdbx_pnl_sort(MDBX_PNL pnl) { } #undef PNL_SMALL #undef PNL_SWAP - assert(mdbx_pnl_check(pnl)); + assert(mdbx_pnl_check(pnl, false)); } /* Search for an ID in an PNL. @@ -637,7 +757,7 @@ static void __hot mdbx_pnl_sort(MDBX_PNL pnl) { * [in] id The ID to search for. * Returns The index of the first ID greater than or equal to id. */ static unsigned __hot mdbx_pnl_search(MDBX_PNL pnl, pgno_t id) { - assert(mdbx_pnl_check(pnl)); + assert(mdbx_pnl_check(pnl, true)); /* binary search of id in pl * if found, returns position of id @@ -645,13 +765,13 @@ static unsigned __hot mdbx_pnl_search(MDBX_PNL pnl, pgno_t id) { unsigned base = 0; unsigned cursor = 1; int val = 0; - unsigned n = pnl[0]; + unsigned n = MDBX_PNL_SIZE(pnl); while (n > 0) { unsigned pivot = n >> 1; cursor = base + pivot + 1; - val = MDBX_PNL_ASCENDING ? mdbx_cmp2int(pnl[cursor], id) - : mdbx_cmp2int(id, pnl[cursor]); + val = MDBX_PNL_ASCENDING ? mdbx_cmp2int(id, pnl[cursor]) + : mdbx_cmp2int(pnl[cursor], id); if (val < 0) { n = pivot; @@ -669,189 +789,144 @@ static unsigned __hot mdbx_pnl_search(MDBX_PNL pnl, pgno_t id) { return cursor; } -/* Shrink an PNL. - * Return the PNL to the default size if it has grown larger. - * [in,out] ppl Address of the PNL to shrink. */ -static void mdbx_pnl_shrink(MDBX_PNL *ppl) { - MDBX_PNL pl = *ppl - 1; - if (unlikely(*pl > MDBX_PNL_UM_MAX)) { - /* shrink to MDBX_PNL_UM_MAX */ - pl = realloc(pl, (MDBX_PNL_UM_MAX + 2) * sizeof(pgno_t)); - if (likely(pl)) { - *pl++ = MDBX_PNL_UM_MAX; - *ppl = pl; - } - } -} +/*----------------------------------------------------------------------------*/ -/* Grow an PNL. - * Return the PNL to the size growed by given number. - * [in,out] ppl Address of the PNL to grow. */ -static int mdbx_pnl_grow(MDBX_PNL *ppl, size_t num) { - MDBX_PNL idn = *ppl - 1; - /* grow it */ - idn = realloc(idn, (*idn + num + 2) * sizeof(pgno_t)); - if (unlikely(!idn)) - return MDBX_ENOMEM; - *idn++ += (pgno_t)num; - *ppl = idn; - return 0; +static __inline size_t txl2bytes(const size_t size) { + assert(size > 0 && size <= MDBX_TXL_MAX * 2); + size_t bytes = + mdbx_roundup2(MDBX_ASSUME_MALLOC_OVERHEAD + sizeof(txnid_t) * (size + 2), + MDBX_TXL_GRANULATE * sizeof(txnid_t)) - + MDBX_ASSUME_MALLOC_OVERHEAD; + return bytes; } -static int mdbx_txl_grow(MDBX_TXL *ptr, size_t num) { - MDBX_TXL list = *ptr - 1; - /* grow it */ - list = realloc(list, ((size_t)*list + num + 2) * sizeof(txnid_t)); - if (unlikely(!list)) - return MDBX_ENOMEM; - *list++ += num; - *ptr = list; - return 0; +static __inline size_t bytes2txl(const size_t bytes) { + size_t size = bytes / sizeof(txnid_t); + assert(size > 2 && size <= MDBX_TXL_MAX * 2); + return size - 2; } -/* Make room for num additional elements in an PNL. - * [in,out] ppl Address of the PNL. - * [in] num Number of elements to make room for. - * Returns 0 on success, MDBX_ENOMEM on failure. */ -static int mdbx_pnl_need(MDBX_PNL *ppl, size_t num) { - MDBX_PNL pl = *ppl; - num += pl[0]; - if (unlikely(num > pl[-1])) { - num = (num + num / 4 + (256 + 2)) & -256; - pl = realloc(pl - 1, num * sizeof(pgno_t)); - if (unlikely(!pl)) - return MDBX_ENOMEM; - *pl++ = (pgno_t)num - 2; - *ppl = pl; +static MDBX_TXL mdbx_txl_alloc(void) { + const size_t bytes = txl2bytes(MDBX_TXL_INITIAL); + MDBX_TXL tl = malloc(bytes); + if (likely(tl)) { +#if __GLIBC_PREREQ(2, 12) + const size_t bytes = malloc_usable_size(tl); +#endif + tl[0] = bytes2txl(bytes); + assert(tl[0] >= MDBX_TXL_INITIAL); + tl[1] = 0; + tl += 1; } - return 0; + return tl; } -/* Append an ID onto an PNL. - * [in,out] ppl Address of the PNL to append to. - * [in] id The ID to append. - * Returns 0 on success, MDBX_ENOMEM if the PNL is too large. */ -static int mdbx_pnl_append(MDBX_PNL *ppl, pgno_t id) { - MDBX_PNL pl = *ppl; - /* Too big? */ - if (unlikely(pl[0] >= pl[-1])) { - if (mdbx_pnl_grow(ppl, MDBX_PNL_UM_MAX)) - return MDBX_ENOMEM; - pl = *ppl; - } - pl[0]++; - pl[pl[0]] = id; - return 0; +static void mdbx_txl_free(MDBX_TXL tl) { + if (likely(tl)) + free(tl - 1); } -static int mdbx_txl_append(MDBX_TXL *ptr, txnid_t id) { - MDBX_TXL list = *ptr; - /* Too big? */ - if (unlikely(list[0] >= list[-1])) { - if (mdbx_txl_grow(ptr, (size_t)list[0])) - return MDBX_ENOMEM; - list = *ptr; +static int mdbx_txl_reserve(MDBX_TXL *ptl, const size_t wanna) { + const size_t allocated = (size_t)MDBX_PNL_ALLOCLEN(*ptl); + assert(MDBX_PNL_SIZE(*ptl) <= MDBX_TXL_MAX && + MDBX_PNL_ALLOCLEN(*ptl) >= MDBX_PNL_SIZE(*ptl)); + if (likely(allocated >= wanna)) + return MDBX_SUCCESS; + + if (unlikely(wanna > /* paranoia */ MDBX_TXL_MAX)) + return MDBX_TXN_FULL; + + const size_t size = (wanna + wanna - allocated < MDBX_TXL_MAX) + ? wanna + wanna - allocated + : MDBX_TXL_MAX; + const size_t bytes = txl2bytes(size); + MDBX_TXL tl = realloc(*ptl - 1, bytes); + if (likely(tl)) { +#if __GLIBC_PREREQ(2, 12) + const size_t bytes = malloc_usable_size(tl); +#endif + *tl = bytes2txl(bytes); + assert(*tl >= wanna); + *ptl = tl + 1; + return MDBX_SUCCESS; } - list[0]++; - list[list[0]] = id; - return 0; + return MDBX_ENOMEM; } -/* Append an PNL onto an PNL. - * [in,out] ppl Address of the PNL to append to. - * [in] app The PNL to append. - * Returns 0 on success, MDBX_ENOMEM if the PNL is too large. */ -static int mdbx_pnl_append_list(MDBX_PNL *ppl, MDBX_PNL app) { - MDBX_PNL pnl = *ppl; - /* Too big? */ - if (unlikely(pnl[0] + app[0] >= pnl[-1])) { - if (mdbx_pnl_grow(ppl, app[0])) - return MDBX_ENOMEM; - pnl = *ppl; - } - memcpy(&pnl[pnl[0] + 1], &app[1], app[0] * sizeof(pgno_t)); - pnl[0] += app[0]; - return 0; +static __inline int __must_check_result mdbx_txl_need(MDBX_TXL *ptl, + size_t num) { + assert(MDBX_PNL_SIZE(*ptl) <= MDBX_TXL_MAX && + MDBX_PNL_ALLOCLEN(*ptl) >= MDBX_PNL_SIZE(*ptl)); + assert(num <= MDBX_PNL_MAX); + const size_t wanna = (size_t)MDBX_PNL_SIZE(*ptl) + num; + return likely(MDBX_PNL_ALLOCLEN(*ptl) >= wanna) + ? MDBX_SUCCESS + : mdbx_txl_reserve(ptl, wanna); } -static int mdbx_txl_append_list(MDBX_TXL *ptr, MDBX_TXL append) { - MDBX_TXL list = *ptr; - /* Too big? */ - if (unlikely(list[0] + append[0] >= list[-1])) { - if (mdbx_txl_grow(ptr, (size_t)append[0])) - return MDBX_ENOMEM; - list = *ptr; - } - memcpy(&list[list[0] + 1], &append[1], (size_t)append[0] * sizeof(txnid_t)); - list[0] += append[0]; - return 0; +static __inline void mdbx_txl_xappend(MDBX_TXL tl, txnid_t id) { + assert(MDBX_PNL_SIZE(tl) < MDBX_PNL_ALLOCLEN(tl)); + MDBX_PNL_SIZE(tl) += 1; + MDBX_PNL_LAST(tl) = id; } -/* Append an ID range onto an PNL. - * [in,out] ppl Address of the PNL to append to. - * [in] id The lowest ID to append. - * [in] n Number of IDs to append. - * Returns 0 on success, MDBX_ENOMEM if the PNL is too large. */ -static int mdbx_pnl_append_range(MDBX_PNL *ppl, pgno_t id, size_t n) { - pgno_t *pnl = *ppl, len = pnl[0]; - /* Too big? */ - if (unlikely(len + n > pnl[-1])) { - if (mdbx_pnl_grow(ppl, n | MDBX_PNL_UM_MAX)) - return MDBX_ENOMEM; - pnl = *ppl; - } - pnl[0] = len + (pgno_t)n; - pnl += len; - while (n) - pnl[n--] = id++; - return 0; +static int mdbx_txl_cmp(const void *pa, const void *pb) { + const txnid_t a = *(MDBX_TXL)pa; + const txnid_t b = *(MDBX_TXL)pb; + return mdbx_cmp2int(b, a); } -/* Merge an PNL onto an PNL. The destination PNL must be big enough. - * [in] pl The PNL to merge into. - * [in] merge The PNL to merge. */ -static void __hot mdbx_pnl_xmerge(MDBX_PNL pnl, MDBX_PNL merge) { - assert(mdbx_pnl_check(pnl)); - assert(mdbx_pnl_check(merge)); - pgno_t old_id, merge_id, i = merge[0], j = pnl[0], k = i + j, total = k; - pnl[0] = - MDBX_PNL_ASCENDING ? 0 : ~(pgno_t)0; /* delimiter for pl scan below */ - old_id = pnl[j]; - while (i) { - merge_id = merge[i--]; - for (; MDBX_PNL_ORDERED(merge_id, old_id); old_id = pnl[--j]) - pnl[k--] = old_id; - pnl[k--] = merge_id; +static void mdbx_txl_sort(MDBX_TXL ptr) { + /* LY: temporary */ + qsort(ptr + 1, (size_t)ptr[0], sizeof(*ptr), mdbx_txl_cmp); +} + +static int __must_check_result mdbx_txl_append(MDBX_TXL *ptl, txnid_t id) { + if (unlikely(MDBX_PNL_SIZE(*ptl) == MDBX_PNL_ALLOCLEN(*ptl))) { + int rc = mdbx_txl_need(ptl, MDBX_TXL_GRANULATE); + if (unlikely(rc != MDBX_SUCCESS)) + return rc; } - pnl[0] = total; - assert(mdbx_pnl_check(pnl)); + mdbx_txl_xappend(*ptl, id); + return MDBX_SUCCESS; } -/* Search for an ID in an ID2L. - * [in] pnl The ID2L to search. - * [in] id The ID to search for. - * Returns The index of the first ID2 whose mid member is greater than - * or equal to id. */ -static unsigned __hot mdbx_mid2l_search(MDBX_ID2L pnl, pgno_t id) { - /* binary search of id in pnl +static int __must_check_result mdbx_txl_append_list(MDBX_TXL *ptl, + MDBX_TXL append) { + int rc = mdbx_txl_need(ptl, (size_t)MDBX_PNL_SIZE(append)); + if (unlikely(rc != MDBX_SUCCESS)) + return rc; + + memcpy(MDBX_PNL_END(*ptl), MDBX_PNL_BEGIN(append), + (size_t)MDBX_PNL_SIZE(append) * sizeof(txnid_t)); + MDBX_PNL_SIZE(*ptl) += MDBX_PNL_SIZE(append); + return MDBX_SUCCESS; +} + +/*----------------------------------------------------------------------------*/ + +/* Returns the index of the first dirty-page whose pgno + * member is greater than or equal to id. */ +static unsigned __hot mdbx_dpl_search(MDBX_DPL dl, pgno_t id) { + /* binary search of id in array * if found, returns position of id * if not found, returns first position greater than id */ unsigned base = 0; unsigned cursor = 1; int val = 0; - unsigned n = (unsigned)pnl[0].mid; + unsigned n = dl->length; #if MDBX_DEBUG - for (const MDBX_ID2 *ptr = pnl + pnl[0].mid; --ptr > pnl;) { - assert(ptr[0].mid < ptr[1].mid); - assert(ptr[0].mid >= NUM_METAS); + for (const MDBX_DP *ptr = dl + dl->length; --ptr > dl;) { + assert(ptr[0].pgno < ptr[1].pgno); + assert(ptr[0].pgno >= NUM_METAS); } #endif while (n > 0) { unsigned pivot = n >> 1; cursor = base + pivot + 1; - val = mdbx_cmp2int(id, pnl[cursor].mid); + val = mdbx_cmp2int(id, dl[cursor].pgno); if (val < 0) { n = pivot; @@ -869,49 +944,57 @@ static unsigned __hot mdbx_mid2l_search(MDBX_ID2L pnl, pgno_t id) { return cursor; } -/* Insert an ID2 into a ID2L. - * [in,out] pnl The ID2L to insert into. - * [in] id The ID2 to insert. - * Returns 0 on success, -1 if the ID was already present in the ID2L. */ -static int mdbx_mid2l_insert(MDBX_ID2L pnl, MDBX_ID2 *id) { - unsigned x = mdbx_mid2l_search(pnl, id->mid); - if (unlikely(x < 1)) - return /* internal error */ -2; +static int mdbx_dpl_cmp(const void *pa, const void *pb) { + const MDBX_DP a = *(MDBX_DPL)pa; + const MDBX_DP b = *(MDBX_DPL)pb; + return mdbx_cmp2int(a.pgno, b.pgno); +} - if (x <= pnl[0].mid && pnl[x].mid == id->mid) - return /* duplicate */ -1; +static void mdbx_dpl_sort(MDBX_DPL dl) { + assert(dl->length <= MDBX_DPL_TXNFULL); + /* LY: temporary */ + qsort(dl + 1, dl->length, sizeof(*dl), mdbx_dpl_cmp); +} - if (unlikely(pnl[0].mid >= MDBX_PNL_UM_MAX)) - return /* too big */ -2; +static int __must_check_result mdbx_dpl_insert(MDBX_DPL dl, pgno_t pgno, + MDBX_page *page) { + assert(dl->length <= MDBX_DPL_TXNFULL); + unsigned x = mdbx_dpl_search(dl, pgno); + assert((int)x > 0); + if (unlikely(dl[x].pgno == pgno && x <= dl->length)) + return /* duplicate */ MDBX_PROBLEM; - /* insert id */ - pnl[0].mid++; - for (unsigned i = (unsigned)pnl[0].mid; i > x; i--) - pnl[i] = pnl[i - 1]; - pnl[x] = *id; - return 0; + if (unlikely(dl->length == MDBX_DPL_TXNFULL)) + return MDBX_TXN_FULL; + + /* insert page */ + for (unsigned i = dl->length += 1; i > x; --i) + dl[i] = dl[i - 1]; + + dl[x].pgno = pgno; + dl[x].ptr = page; + return MDBX_SUCCESS; } -/* Append an ID2 into a ID2L. - * [in,out] pnl The ID2L to append into. - * [in] id The ID2 to append. - * Returns 0 on success, -2 if the ID2L is too big. */ -static int mdbx_mid2l_append(MDBX_ID2L pnl, MDBX_ID2 *id) { +static int __must_check_result mdbx_dpl_append(MDBX_DPL dl, pgno_t pgno, + MDBX_page *page) { + assert(dl->length <= MDBX_DPL_TXNFULL); #if MDBX_DEBUG - for (unsigned i = pnl[0].mid; i > 0; --i) { - assert(pnl[i].mid != id->mid); - if (unlikely(pnl[i].mid == id->mid)) - return -1; + for (unsigned i = dl->length; i > 0; --i) { + assert(dl[i].pgno != pgno); + if (unlikely(dl[i].pgno == pgno)) + return MDBX_PROBLEM; } #endif - /* Too big? */ - if (unlikely(pnl[0].mid >= MDBX_PNL_UM_MAX)) - return -2; + if (unlikely(dl->length == MDBX_DPL_TXNFULL)) + return MDBX_TXN_FULL; - pnl[0].mid++; - pnl[pnl[0].mid] = *id; - return 0; + /* append page */ + const unsigned i = dl->length += 1; + dl[i].pgno = pgno; + dl[i].ptr = page; + return MDBX_SUCCESS; } /*----------------------------------------------------------------------------*/ @@ -978,7 +1061,7 @@ static int __must_check_result mdbx_page_merge(MDBX_cursor *csrc, #define MDBX_SPLIT_REPLACE MDBX_APPENDDUP /* newkey is not new */ static int __must_check_result mdbx_page_split(MDBX_cursor *mc, - MDBX_val *newkey, + const MDBX_val *newkey, MDBX_val *newdata, pgno_t newpgno, unsigned nflags); @@ -989,24 +1072,38 @@ static int __must_check_result mdbx_sync_locked(MDBX_env *env, unsigned flags, static void mdbx_env_close0(MDBX_env *env); static MDBX_node *mdbx_node_search(MDBX_cursor *mc, MDBX_val *key, int *exactp); -static int __must_check_result mdbx_node_add(MDBX_cursor *mc, unsigned indx, - MDBX_val *key, MDBX_val *data, - pgno_t pgno, unsigned flags); + +static int __must_check_result mdbx_node_add_branch(MDBX_cursor *mc, + unsigned indx, + const MDBX_val *key, + pgno_t pgno); +static int __must_check_result mdbx_node_add_leaf(MDBX_cursor *mc, + unsigned indx, + const MDBX_val *key, + MDBX_val *data, + unsigned flags); +static int __must_check_result mdbx_node_add_leaf2(MDBX_cursor *mc, + unsigned indx, + const MDBX_val *key); + static void mdbx_node_del(MDBX_cursor *mc, size_t ksize); static void mdbx_node_shrink(MDBX_page *mp, unsigned indx); static int __must_check_result mdbx_node_move(MDBX_cursor *csrc, MDBX_cursor *cdst, int fromleft); static int __must_check_result mdbx_node_read(MDBX_cursor *mc, MDBX_node *leaf, MDBX_val *data); -static size_t mdbx_leaf_size(MDBX_env *env, MDBX_val *key, MDBX_val *data); -static size_t mdbx_branch_size(MDBX_env *env, MDBX_val *key); +static size_t mdbx_leaf_size(MDBX_env *env, const MDBX_val *key, + const MDBX_val *data); +static size_t mdbx_branch_size(MDBX_env *env, const MDBX_val *key); static int __must_check_result mdbx_rebalance(MDBX_cursor *mc); -static int __must_check_result mdbx_update_key(MDBX_cursor *mc, MDBX_val *key); +static int __must_check_result mdbx_update_key(MDBX_cursor *mc, + const MDBX_val *key); static void mdbx_cursor_pop(MDBX_cursor *mc); static int __must_check_result mdbx_cursor_push(MDBX_cursor *mc, MDBX_page *mp); +static int __must_check_result mdbx_cursor_check(MDBX_cursor *mc, bool pending); static int __must_check_result mdbx_cursor_del0(MDBX_cursor *mc); static int __must_check_result mdbx_del0(MDBX_txn *txn, MDBX_dbi dbi, MDBX_val *key, MDBX_val *data, @@ -1028,7 +1125,7 @@ static int __must_check_result mdbx_cursor_last(MDBX_cursor *mc, MDBX_val *key, MDBX_val *data); static int __must_check_result mdbx_cursor_init(MDBX_cursor *mc, MDBX_txn *txn, - MDBX_dbi dbi, MDBX_xcursor *mx); + MDBX_dbi dbi); static int __must_check_result mdbx_xcursor_init0(MDBX_cursor *mc); static int __must_check_result mdbx_xcursor_init1(MDBX_cursor *mc, MDBX_node *node); @@ -1230,7 +1327,7 @@ static const char *mdbx_leafnode_type(MDBX_node *n) { /* Display all the keys in the page. */ static void mdbx_page_list(MDBX_page *mp) { pgno_t pgno = mp->mp_pgno; - const char *type, *state = (mp->mp_flags & P_DIRTY) ? ", dirty" : ""; + const char *type, *state = IS_DIRTY(mp) ? ", dirty" : ""; MDBX_node *node; unsigned i, nkeys, nsize, total = 0; MDBX_val key; @@ -1245,13 +1342,13 @@ static void mdbx_page_list(MDBX_page *mp) { type = "Leaf page"; break; case P_LEAF | P_SUBP: - type = "Sub-page"; + type = "Leaf sub-page"; break; case P_LEAF | P_LEAF2: - type = "LEAF2 page"; + type = "Leaf2 page"; break; case P_LEAF | P_LEAF2 | P_SUBP: - type = "LEAF2 sub-page"; + type = "Leaf2 sub-page"; break; case P_OVERFLOW: mdbx_print("Overflow page %" PRIu64 " pages %u%s\n", pgno, mp->mp_pages, @@ -1327,61 +1424,6 @@ static void mdbx_cursor_chk(MDBX_cursor *mc) { } #endif /* 0 */ -/* Count all the pages in each DB and in the freelist and make sure - * it matches the actual number of pages being used. - * All named DBs must be open for a correct count. */ -static int mdbx_audit(MDBX_txn *txn) { - MDBX_cursor mc; - MDBX_val key, data; - int rc; - - pgno_t freecount = 0; - rc = mdbx_cursor_init(&mc, txn, FREE_DBI, NULL); - if (unlikely(rc != MDBX_SUCCESS)) - return rc; - while ((rc = mdbx_cursor_get(&mc, &key, &data, MDBX_NEXT)) == 0) - freecount += *(pgno_t *)data.iov_base; - mdbx_tassert(txn, rc == MDBX_NOTFOUND); - - pgno_t count = 0; - for (MDBX_dbi i = 0; i < txn->mt_numdbs; i++) { - MDBX_xcursor mx; - if (!(txn->mt_dbflags[i] & DB_VALID)) - continue; - rc = mdbx_cursor_init(&mc, txn, i, &mx); - if (unlikely(rc != MDBX_SUCCESS)) - return rc; - if (txn->mt_dbs[i].md_root == P_INVALID) - continue; - count += txn->mt_dbs[i].md_branch_pages + txn->mt_dbs[i].md_leaf_pages + - txn->mt_dbs[i].md_overflow_pages; - if (txn->mt_dbs[i].md_flags & MDBX_DUPSORT) { - rc = mdbx_page_search(&mc, NULL, MDBX_PS_FIRST); - for (; rc == MDBX_SUCCESS; rc = mdbx_cursor_sibling(&mc, 1)) { - MDBX_page *mp = mc.mc_pg[mc.mc_top]; - for (unsigned j = 0; j < NUMKEYS(mp); j++) { - MDBX_node *leaf = NODEPTR(mp, j); - if (leaf->mn_flags & F_SUBDATA) { - MDBX_db db; - memcpy(&db, NODEDATA(leaf), sizeof(db)); - count += - db.md_branch_pages + db.md_leaf_pages + db.md_overflow_pages; - } - } - } - mdbx_tassert(txn, rc == MDBX_NOTFOUND); - } - } - if (freecount + count + NUM_METAS != txn->mt_next_pgno) { - mdbx_print("audit: %" PRIaTXN " freecount: %" PRIaPGNO " count: %" PRIaPGNO - " total: %" PRIaPGNO " next_pgno: %" PRIaPGNO "\n", - txn->mt_txnid, freecount, count + NUM_METAS, - freecount + count + NUM_METAS, txn->mt_next_pgno); - return MDBX_CORRUPTED; - } - return MDBX_SUCCESS; -} - int mdbx_cmp(MDBX_txn *txn, MDBX_dbi dbi, const MDBX_val *a, const MDBX_val *b) { mdbx_assert(NULL, txn->mt_signature == MDBX_MT_SIGNATURE); @@ -1434,22 +1476,15 @@ static MDBX_page *mdbx_page_malloc(MDBX_txn *txn, unsigned num) { return np; } -/* Free a single page. - * Saves single pages to a list, for future reuse. - * (This is not used for multi-page overflow pages.) */ -static __inline void mdbx_page_free(MDBX_env *env, MDBX_page *mp) { +/* Free a dirty page */ +static void mdbx_dpage_free(MDBX_env *env, MDBX_page *dp, unsigned pages) { #if MDBX_DEBUG - mp->mp_pgno = MAX_PAGENO; + dp->mp_pgno = MAX_PAGENO; #endif - mp->mp_next = env->me_dpages; - VALGRIND_MEMPOOL_FREE(env, mp); - env->me_dpages = mp; -} - -/* Free a dirty page */ -static void mdbx_dpage_free(MDBX_env *env, MDBX_page *dp) { - if (!IS_OVERFLOW(dp) || dp->mp_pages == 1) { - mdbx_page_free(env, dp); + if (pages == 1) { + dp->mp_next = env->me_dpages; + VALGRIND_MEMPOOL_FREE(env, dp); + env->me_dpages = dp; } else { /* large pages just get freed directly */ VALGRIND_MEMPOOL_FREE(env, dp); @@ -1460,34 +1495,58 @@ static void mdbx_dpage_free(MDBX_env *env, MDBX_page *dp) { /* Return all dirty pages to dpage list */ static void mdbx_dlist_free(MDBX_txn *txn) { MDBX_env *env = txn->mt_env; - MDBX_ID2L dl = txn->mt_rw_dirtylist; - size_t i, n = dl[0].mid; + MDBX_DPL dl = txn->mt_rw_dirtylist; + size_t i, n = dl->length; - for (i = 1; i <= n; i++) - mdbx_dpage_free(env, dl[i].mptr); + for (i = 1; i <= n; i++) { + MDBX_page *dp = dl[i].ptr; + mdbx_dpage_free(env, dp, IS_OVERFLOW(dp) ? dp->mp_pages : 1); + } - dl[0].mid = 0; + dl->length = 0; } static size_t bytes_align2os_bytes(const MDBX_env *env, size_t bytes) { return mdbx_roundup2(mdbx_roundup2(bytes, env->me_psize), env->me_os_psize); } -static void __cold mdbx_kill_page(MDBX_env *env, pgno_t pgno) { - const size_t offs = pgno2bytes(env, pgno); - const size_t shift = offsetof(MDBX_page, mp_pages); +static void __cold mdbx_kill_page(MDBX_env *env, MDBX_page *mp) { + const size_t len = env->me_psize - PAGEHDRSZ; + void *ptr = (env->me_flags & MDBX_WRITEMAP) ? &mp->mp_data : alloca(len); + memset(ptr, 0x6F /* 'o', 111 */, len); + if (ptr != &mp->mp_data) + (void)mdbx_pwrite(env->me_fd, ptr, len, + pgno2bytes(env, mp->mp_pgno) + PAGEHDRSZ); - if (env->me_flags & MDBX_WRITEMAP) { - MDBX_page *mp = (MDBX_page *)(env->me_map + offs); - memset(&mp->mp_pages, 0x6F /* 'o', 111 */, env->me_psize - shift); - VALGRIND_MAKE_MEM_NOACCESS(&mp->mp_pages, env->me_psize - shift); - ASAN_POISON_MEMORY_REGION(&mp->mp_pages, env->me_psize - shift); + VALGRIND_MAKE_MEM_NOACCESS(&mp->mp_data, len); + ASAN_POISON_MEMORY_REGION(&mp->mp_data, len); +} + +static __inline MDBX_db *mdbx_outer_db(MDBX_cursor *mc) { + mdbx_cassert(mc, (mc->mc_flags & C_SUB) != 0); + MDBX_xcursor *mx = container_of(mc->mc_db, MDBX_xcursor, mx_db); + MDBX_cursor_couple *couple = container_of(mx, MDBX_cursor_couple, inner); + mdbx_cassert(mc, mc->mc_db == &couple->outer.mc_xcursor->mx_db); + mdbx_cassert(mc, mc->mc_dbx == &couple->outer.mc_xcursor->mx_dbx); + return couple->outer.mc_db; +} + +static int mdbx_page_befree(MDBX_cursor *mc, MDBX_page *mp) { + MDBX_txn *txn = mc->mc_txn; + + mdbx_cassert(mc, (mc->mc_flags & C_SUB) == 0); + if (IS_BRANCH(mp)) { + mc->mc_db->md_branch_pages--; + } else if (IS_LEAF(mp)) { + mc->mc_db->md_leaf_pages--; } else { - intptr_t len = env->me_psize - shift; - void *buf = alloca(len); - memset(buf, 0x6F /* 'o', 111 */, len); - (void)mdbx_pwrite(env->me_fd, buf, len, offs + shift); + mdbx_cassert(mc, IS_OVERFLOW(mp)); + mc->mc_db->md_overflow_pages -= mp->mp_pages; + return mdbx_pnl_append_range(&txn->mt_befree_pages, mp->mp_pgno, + mp->mp_pages); } + + return mdbx_pnl_append(&txn->mt_befree_pages, mp->mp_pgno); } /* Loosen or free a single page. @@ -1505,19 +1564,37 @@ static int mdbx_page_loose(MDBX_cursor *mc, MDBX_page *mp) { const pgno_t pgno = mp->mp_pgno; MDBX_txn *txn = mc->mc_txn; - if ((mp->mp_flags & P_DIRTY) && mc->mc_dbi != FREE_DBI) { + if (unlikely(mc->mc_flags & C_SUB)) { + MDBX_db *outer = mdbx_outer_db(mc); + if (IS_BRANCH(mp)) + outer->md_branch_pages--; + else { + mdbx_cassert(mc, IS_LEAF(mp)); + outer->md_leaf_pages--; + } + } + + if (IS_BRANCH(mp)) + mc->mc_db->md_branch_pages--; + else { + mdbx_cassert(mc, IS_LEAF(mp)); + mc->mc_db->md_leaf_pages--; + } + + if (IS_DIRTY(mp)) { if (txn->mt_parent) { + /* LY: TODO: use dedicated flag for tracking parent's dirty pages */ mdbx_cassert(mc, (txn->mt_env->me_flags & MDBX_WRITEMAP) == 0); - MDBX_ID2 *dl = txn->mt_rw_dirtylist; + MDBX_DP *dl = txn->mt_rw_dirtylist; /* If txn has a parent, * make sure the page is in our dirty list. */ - if (dl[0].mid) { - unsigned x = mdbx_mid2l_search(dl, pgno); - if (x <= dl[0].mid && dl[x].mid == pgno) { - if (unlikely(mp != dl[x].mptr)) { /* bad cursor? */ + if (dl->length) { + unsigned x = mdbx_dpl_search(dl, pgno); + if (x <= dl->length && dl[x].pgno == pgno) { + if (unlikely(mp != dl[x].ptr)) { /* bad cursor? */ mdbx_error("wrong page 0x%p #%" PRIaPGNO " in the dirtylist[%d], expecting %p", - dl[x].mptr, pgno, x, mp); + dl[x].ptr, pgno, x, mp); mc->mc_flags &= ~(C_INITIALIZED | C_EOF); txn->mt_flags |= MDBX_TXN_ERROR; return MDBX_PROBLEM; @@ -1531,21 +1608,22 @@ static int mdbx_page_loose(MDBX_cursor *mc, MDBX_page *mp) { loose = 1; } } + if (loose) { mdbx_debug("loosen db %d page %" PRIaPGNO, DDBI(mc), mp->mp_pgno); MDBX_page **link = &NEXT_LOOSE_PAGE(mp); - if (unlikely(txn->mt_env->me_flags & MDBX_PAGEPERTURB)) { - mdbx_kill_page(txn->mt_env, pgno); - VALGRIND_MAKE_MEM_UNDEFINED(link, sizeof(MDBX_page *)); - ASAN_UNPOISON_MEMORY_REGION(link, sizeof(MDBX_page *)); - } + if (unlikely(txn->mt_env->me_flags & MDBX_PAGEPERTURB)) + mdbx_kill_page(txn->mt_env, mp); + mp->mp_flags = P_LOOSE | P_DIRTY; + VALGRIND_MAKE_MEM_UNDEFINED(mp, PAGEHDRSZ); + VALGRIND_MAKE_MEM_DEFINED(&mp->mp_pgno, sizeof(pgno_t)); *link = txn->mt_loose_pages; txn->mt_loose_pages = mp; txn->mt_loose_count++; - mp->mp_flags |= P_LOOSE; } else { int rc = mdbx_pnl_append(&txn->mt_befree_pages, pgno); - if (unlikely(rc)) + mdbx_tassert(txn, rc == MDBX_SUCCESS); + if (unlikely(rc != MDBX_SUCCESS)) return rc; } @@ -1585,7 +1663,7 @@ static int mdbx_pages_xkeep(MDBX_cursor *mc, unsigned pflags, bool all) { /* Proceed to mx if it is at a sub-database */ if (!(mx && (mx->mx_cursor.mc_flags & C_INITIALIZED))) break; - if (!(mp && (mp->mp_flags & P_LEAF))) + if (!(mp && IS_LEAF(mp))) break; leaf = NODEPTR(mp, m3->mc_ki[j - 1]); if (!(leaf->mn_flags & F_SUBDATA)) @@ -1656,7 +1734,7 @@ static int mdbx_page_flush(MDBX_txn *txn, pgno_t keep); * Returns 0 on success, non-zero on failure. */ static int mdbx_page_spill(MDBX_cursor *m0, MDBX_val *key, MDBX_val *data) { MDBX_txn *txn = m0->mc_txn; - MDBX_ID2L dl = txn->mt_rw_dirtylist; + MDBX_DPL dl = txn->mt_rw_dirtylist; if (m0->mc_flags & C_SUB) return MDBX_SUCCESS; @@ -1676,18 +1754,18 @@ static int mdbx_page_spill(MDBX_cursor *m0, MDBX_val *key, MDBX_val *data) { return MDBX_SUCCESS; if (!txn->mt_spill_pages) { - txn->mt_spill_pages = mdbx_pnl_alloc(MDBX_PNL_UM_MAX); + txn->mt_spill_pages = mdbx_pnl_alloc(MDBX_DPL_TXNFULL); if (unlikely(!txn->mt_spill_pages)) return MDBX_ENOMEM; } else { /* purge deleted slots */ MDBX_PNL sl = txn->mt_spill_pages; - pgno_t num = sl[0], j = 0; + pgno_t num = MDBX_PNL_SIZE(sl), j = 0; for (i = 1; i <= num; i++) { - if (!(sl[i] & 1)) + if ((sl[i] & 1) == 0) sl[++j] = sl[i]; } - sl[0] = j; + MDBX_PNL_SIZE(sl) = j; } /* Preserve pages which may soon be dirtied again */ @@ -1701,14 +1779,14 @@ static int mdbx_page_spill(MDBX_cursor *m0, MDBX_val *key, MDBX_val *data) { * of those pages will need to be used again. So now we spill only 1/8th * of the dirty pages. Testing revealed this to be a good tradeoff, * better than 1/2, 1/4, or 1/10. */ - if (need < MDBX_PNL_UM_MAX / 8) - need = MDBX_PNL_UM_MAX / 8; + if (need < MDBX_DPL_TXNFULL / 8) + need = MDBX_DPL_TXNFULL / 8; /* Save the page IDs of all the pages we're flushing */ /* flush from the tail forward, this saves a lot of shifting later on. */ - for (i = dl[0].mid; i && need; i--) { - pgno_t pn = dl[i].mid << 1; - MDBX_page *dp = dl[i].mptr; + for (i = dl->length; i && need; i--) { + pgno_t pn = dl[i].pgno << 1; + MDBX_page *dp = dl[i].ptr; if (dp->mp_flags & (P_LOOSE | P_KEEP)) continue; /* Can't spill twice, @@ -1718,7 +1796,8 @@ static int mdbx_page_spill(MDBX_cursor *m0, MDBX_val *key, MDBX_val *data) { for (tx2 = txn->mt_parent; tx2; tx2 = tx2->mt_parent) { if (tx2->mt_spill_pages) { unsigned j = mdbx_pnl_search(tx2->mt_spill_pages, pn); - if (j <= tx2->mt_spill_pages[0] && tx2->mt_spill_pages[j] == pn) { + if (j <= MDBX_PNL_SIZE(tx2->mt_spill_pages) && + tx2->mt_spill_pages[j] == pn) { dp->mp_flags |= P_KEEP; break; } @@ -1974,20 +2053,16 @@ static txnid_t mdbx_find_oldest(MDBX_txn *txn) { } /* Add a page to the txn's dirty list */ -static void mdbx_page_dirty(MDBX_txn *txn, MDBX_page *mp) { - MDBX_ID2 mid; - int rc, (*insert)(MDBX_ID2L, MDBX_ID2 *); - - if (txn->mt_flags & MDBX_TXN_WRITEMAP) { - insert = mdbx_mid2l_append; - } else { - insert = mdbx_mid2l_insert; +static int __must_check_result mdbx_page_dirty(MDBX_txn *txn, MDBX_page *mp) { + int (*const adder)(MDBX_DPL, pgno_t pgno, MDBX_page * page) = + (txn->mt_flags & MDBX_TXN_WRITEMAP) ? mdbx_dpl_append : mdbx_dpl_insert; + const int rc = adder(txn->mt_rw_dirtylist, mp->mp_pgno, mp); + if (unlikely(rc != MDBX_SUCCESS)) { + txn->mt_flags |= MDBX_TXN_ERROR; + return rc; } - mid.mid = mp->mp_pgno; - mid.mptr = mp; - rc = insert(txn->mt_rw_dirtylist, &mid); - mdbx_tassert(txn, rc == 0); txn->mt_dirtyroom--; + return MDBX_SUCCESS; } static int mdbx_mapresize(MDBX_env *env, const pgno_t size_pgno, @@ -2144,7 +2219,7 @@ static int mdbx_page_alloc(MDBX_cursor *mc, unsigned num, MDBX_page **mp, if (likely(flags & MDBX_ALLOC_GC)) { flags |= env->me_flags & (MDBX_COALESCE | MDBX_LIFORECLAIM); if (unlikely(mc->mc_flags & C_RECLAIMING)) { - /* If mc is updating the freeDB, then the freelist cannot play + /* If mc is updating the freeDB, then the befree-list cannot play * catch-up with itself by growing while trying to save it. */ flags &= ~(MDBX_ALLOC_GC | MDBX_ALLOC_KICK | MDBX_COALESCE | MDBX_LIFORECLAIM); @@ -2171,9 +2246,9 @@ static int mdbx_page_alloc(MDBX_cursor *mc, unsigned num, MDBX_page **mp, } } - mdbx_tassert(txn, mdbx_pnl_check(env->me_reclaimed_pglist)); + mdbx_tassert(txn, mdbx_pnl_check(env->me_reclaimed_pglist, true)); pgno_t pgno, *repg_list = env->me_reclaimed_pglist; - unsigned repg_pos = 0, repg_len = repg_list ? repg_list[0] : 0; + unsigned repg_pos = 0, repg_len = repg_list ? MDBX_PNL_SIZE(repg_list) : 0; txnid_t oldest = 0, last = 0; const unsigned wanna_range = num - 1; @@ -2191,7 +2266,7 @@ static int mdbx_page_alloc(MDBX_cursor *mc, unsigned num, MDBX_page **mp, /* Seek a big enough contiguous page range. * Prefer pages with lower pgno. */ - mdbx_tassert(txn, mdbx_pnl_check(env->me_reclaimed_pglist)); + mdbx_tassert(txn, mdbx_pnl_check(env->me_reclaimed_pglist, true)); if (likely(flags & MDBX_ALLOC_CACHE) && repg_len > wanna_range && (!(flags & MDBX_COALESCE) || op == MDBX_FIRST)) { #if MDBX_PNL_ASCENDING @@ -2217,8 +2292,8 @@ static int mdbx_page_alloc(MDBX_cursor *mc, unsigned num, MDBX_page **mp, /* Prepare to fetch more and coalesce */ oldest = (flags & MDBX_LIFORECLAIM) ? mdbx_find_oldest(txn) - : env->me_oldest[0]; - rc = mdbx_cursor_init(&recur, txn, FREE_DBI, NULL); + : *env->me_oldest; + rc = mdbx_cursor_init(&recur, txn, FREE_DBI); if (unlikely(rc != MDBX_SUCCESS)) goto fail; if (flags & MDBX_LIFORECLAIM) { @@ -2279,7 +2354,7 @@ static int mdbx_page_alloc(MDBX_cursor *mc, unsigned num, MDBX_page **mp, /* skip IDs of records that already reclaimed */ if (txn->mt_lifo_reclaimed) { unsigned i; - for (i = (unsigned)txn->mt_lifo_reclaimed[0]; i > 0; --i) + for (i = (unsigned)MDBX_PNL_SIZE(txn->mt_lifo_reclaimed); i > 0; --i) if (txn->mt_lifo_reclaimed[i] == last) break; if (i) @@ -2302,11 +2377,11 @@ static int mdbx_page_alloc(MDBX_cursor *mc, unsigned num, MDBX_page **mp, } /* Append PNL from FreeDB record to me_reclaimed_pglist */ + mdbx_cassert(mc, (mc->mc_flags & C_GCFREEZE) == 0); pgno_t *re_pnl = (pgno_t *)data.iov_base; - mdbx_tassert(txn, re_pnl[0] == 0 || - data.iov_len == (re_pnl[0] + 1) * sizeof(pgno_t)); - mdbx_tassert(txn, mdbx_pnl_check(re_pnl)); - repg_pos = re_pnl[0]; + mdbx_tassert(txn, data.iov_len >= MDBX_PNL_SIZEOF(re_pnl)); + mdbx_tassert(txn, mdbx_pnl_check(re_pnl, false)); + repg_pos = MDBX_PNL_SIZE(re_pnl); if (!repg_list) { if (unlikely(!(env->me_reclaimed_pglist = repg_list = mdbx_pnl_alloc(repg_pos)))) { @@ -2339,7 +2414,7 @@ static int mdbx_page_alloc(MDBX_cursor *mc, unsigned num, MDBX_page **mp, /* Merge in descending sorted order */ mdbx_pnl_xmerge(repg_list, re_pnl); - repg_len = repg_list[0]; + repg_len = MDBX_PNL_SIZE(repg_list); if (unlikely((flags & MDBX_ALLOC_CACHE) == 0)) { /* Done for a kick-reclaim mode, actually no page needed */ return MDBX_SUCCESS; @@ -2371,22 +2446,20 @@ static int mdbx_page_alloc(MDBX_cursor *mc, unsigned num, MDBX_page **mp, for (pgno_t *move = begin; higest < end; ++move, ++higest) *move = *higest; #endif /* MDBX_PNL sort-order */ - repg_list[0] = repg_len; + MDBX_PNL_SIZE(repg_list) = repg_len; mdbx_info("refunded %" PRIaPGNO " pages: %" PRIaPGNO " -> %" PRIaPGNO, tail - txn->mt_next_pgno, tail, txn->mt_next_pgno); txn->mt_next_pgno = tail; - mdbx_tassert(txn, mdbx_pnl_check(env->me_reclaimed_pglist)); + mdbx_tassert(txn, mdbx_pnl_check(env->me_reclaimed_pglist, true)); } } /* Don't try to coalesce too much. */ - if (repg_len > MDBX_PNL_UM_SIZE / 2) + if (unlikely(repg_len > MDBX_DPL_TXNFULL / 4)) break; - if (flags & MDBX_COALESCE) { - if (repg_len /* current size */ >= env->me_maxfree_1pg / 2 || - repg_pos /* prev size */ >= env->me_maxfree_1pg / 4) - flags &= ~MDBX_COALESCE; - } + if (repg_len /* current size */ >= env->me_maxgc_ov1page || + repg_pos /* prev size */ >= env->me_maxgc_ov1page / 2) + flags &= ~MDBX_COALESCE; } if ((flags & (MDBX_COALESCE | MDBX_ALLOC_CACHE)) == @@ -2485,7 +2558,7 @@ static int mdbx_page_alloc(MDBX_cursor *mc, unsigned num, MDBX_page **mp, } fail: - mdbx_tassert(txn, mdbx_pnl_check(env->me_reclaimed_pglist)); + mdbx_tassert(txn, mdbx_pnl_check(env->me_reclaimed_pglist, true)); if (mp) { *mp = NULL; txn->mt_flags |= MDBX_TXN_ERROR; @@ -2510,13 +2583,14 @@ done: } if (repg_pos) { + mdbx_cassert(mc, (mc->mc_flags & C_GCFREEZE) == 0); mdbx_tassert(txn, pgno < txn->mt_next_pgno); mdbx_tassert(txn, pgno == repg_list[repg_pos]); /* Cutoff allocated pages from me_reclaimed_pglist */ - repg_list[0] = repg_len -= num; + MDBX_PNL_SIZE(repg_list) = repg_len -= num; for (unsigned i = repg_pos - num; i < repg_len;) repg_list[++i] = repg_list[++repg_pos]; - mdbx_tassert(txn, mdbx_pnl_check(env->me_reclaimed_pglist)); + mdbx_tassert(txn, mdbx_pnl_check(env->me_reclaimed_pglist, true)); } else { txn->mt_next_pgno = pgno + num; mdbx_assert(env, txn->mt_next_pgno <= txn->mt_end_pgno); @@ -2530,10 +2604,12 @@ done: np->mp_leaf2_ksize = 0; np->mp_flags = 0; np->mp_pages = num; - mdbx_page_dirty(txn, np); + rc = mdbx_page_dirty(txn, np); + if (unlikely(rc != MDBX_SUCCESS)) + goto fail; *mp = np; - mdbx_tassert(txn, mdbx_pnl_check(env->me_reclaimed_pglist)); + mdbx_tassert(txn, mdbx_pnl_check(env->me_reclaimed_pglist, true)); return MDBX_SUCCESS; } @@ -2568,7 +2644,8 @@ static void mdbx_page_copy(MDBX_page *dst, MDBX_page *src, unsigned psize) { * [in] mp the page being referenced. It must not be dirty. * [out] ret the writable page, if any. * ret is unchanged if mp wasn't spilled. */ -static int mdbx_page_unspill(MDBX_txn *txn, MDBX_page *mp, MDBX_page **ret) { +static int __must_check_result mdbx_page_unspill(MDBX_txn *txn, MDBX_page *mp, + MDBX_page **ret) { MDBX_env *env = txn->mt_env; const MDBX_txn *tx2; unsigned x; @@ -2578,7 +2655,8 @@ static int mdbx_page_unspill(MDBX_txn *txn, MDBX_page *mp, MDBX_page **ret) { if (!tx2->mt_spill_pages) continue; x = mdbx_pnl_search(tx2->mt_spill_pages, pn); - if (x <= tx2->mt_spill_pages[0] && tx2->mt_spill_pages[x] == pn) { + if (x <= MDBX_PNL_SIZE(tx2->mt_spill_pages) && + tx2->mt_spill_pages[x] == pn) { MDBX_page *np; int num; if (txn->mt_dirtyroom == 0) @@ -2600,14 +2678,17 @@ static int mdbx_page_unspill(MDBX_txn *txn, MDBX_page *mp, MDBX_page **ret) { /* If in current txn, this page is no longer spilled. * If it happens to be the last page, truncate the spill list. * Otherwise mark it as deleted by setting the LSB. */ - if (x == txn->mt_spill_pages[0]) - txn->mt_spill_pages[0]--; + if (x == MDBX_PNL_SIZE(txn->mt_spill_pages)) + MDBX_PNL_SIZE(txn->mt_spill_pages)--; else txn->mt_spill_pages[x] |= 1; } /* otherwise, if belonging to a parent txn, the * page remains spilled until child commits */ - mdbx_page_dirty(txn, np); + int rc = mdbx_page_dirty(txn, np); + if (unlikely(rc != MDBX_SUCCESS)) + return rc; + np->mp_flags |= P_DIRTY; *ret = np; break; @@ -2658,34 +2739,37 @@ static int mdbx_page_touch(MDBX_cursor *mc) { } } else if (txn->mt_parent && !IS_SUBP(mp)) { mdbx_tassert(txn, (txn->mt_env->me_flags & MDBX_WRITEMAP) == 0); - MDBX_ID2 mid, *dl = txn->mt_rw_dirtylist; + MDBX_DP *dl = txn->mt_rw_dirtylist; pgno = mp->mp_pgno; /* If txn has a parent, make sure the page is in our dirty list. */ - if (dl[0].mid) { - unsigned x = mdbx_mid2l_search(dl, pgno); - if (x <= dl[0].mid && dl[x].mid == pgno) { - if (unlikely(mp != dl[x].mptr)) { /* bad cursor? */ + if (dl->length) { + unsigned x = mdbx_dpl_search(dl, pgno); + if (x <= dl->length && dl[x].pgno == pgno) { + if (unlikely(mp != dl[x].ptr)) { /* bad cursor? */ mdbx_error("wrong page 0x%p #%" PRIaPGNO " in the dirtylist[%d], expecting %p", - dl[x].mptr, pgno, x, mp); + dl[x].ptr, pgno, x, mp); mc->mc_flags &= ~(C_INITIALIZED | C_EOF); - txn->mt_flags |= MDBX_TXN_ERROR; - return MDBX_PROBLEM; + rc = MDBX_PROBLEM; + goto fail; } return MDBX_SUCCESS; } } mdbx_debug("clone db %d page %" PRIaPGNO, DDBI(mc), mp->mp_pgno); - mdbx_cassert(mc, dl[0].mid < MDBX_PNL_UM_MAX); + mdbx_cassert(mc, dl->length <= MDBX_DPL_TXNFULL); /* No - copy it */ np = mdbx_page_malloc(txn, 1); - if (unlikely(!np)) - return MDBX_ENOMEM; - mid.mid = pgno; - mid.mptr = np; - rc = mdbx_mid2l_insert(dl, &mid); - mdbx_cassert(mc, rc == 0); + if (unlikely(!np)) { + rc = MDBX_ENOMEM; + goto fail; + } + rc = mdbx_dpl_insert(dl, pgno, np); + if (unlikely(rc)) { + mdbx_dpage_free(txn->mt_env, np, 1); + goto fail; + } } else { return MDBX_SUCCESS; } @@ -2921,7 +3005,6 @@ static int mdbx_txn_renew0(MDBX_txn *txn, unsigned flags) { return MDBX_BAD_RSLOT; } else if (env->me_lck) { unsigned slot, nreaders; - const mdbx_pid_t pid = env->me_pid; const mdbx_tid_t tid = mdbx_thread_self(); mdbx_assert(env, env->me_lck->mti_magic_and_version == MDBX_LOCK_MAGIC); mdbx_assert(env, env->me_lck->mti_os_and_format == MDBX_LOCK_FORMAT); @@ -2931,13 +3014,13 @@ static int mdbx_txn_renew0(MDBX_txn *txn, unsigned flags) { return rc; rc = MDBX_SUCCESS; - if (unlikely(env->me_live_reader != pid)) { + if (unlikely(env->me_live_reader != env->me_pid)) { rc = mdbx_rpid_set(env); if (unlikely(rc != MDBX_SUCCESS)) { mdbx_rdt_unlock(env); return rc; } - env->me_live_reader = pid; + env->me_live_reader = env->me_pid; } while (1) { @@ -2970,11 +3053,13 @@ static int mdbx_txn_renew0(MDBX_txn *txn, unsigned flags) { env->me_lck->mti_numreaders = ++nreaders; if (env->me_close_readers < nreaders) env->me_close_readers = nreaders; - r->mr_pid = pid; + r->mr_pid = env->me_pid; mdbx_rdt_unlock(env); - if (likely(env->me_flags & MDBX_ENV_TXKEY)) + if (likely(env->me_flags & MDBX_ENV_TXKEY)) { + assert(env->me_live_reader == env->me_pid); mdbx_thread_rthc_set(env->me_txkey, r); + } } while (1) { @@ -3042,14 +3127,14 @@ static int mdbx_txn_renew0(MDBX_txn *txn, unsigned flags) { txn->mt_child = NULL; txn->mt_loose_pages = NULL; txn->mt_loose_count = 0; - txn->mt_dirtyroom = MDBX_PNL_UM_MAX; + txn->mt_dirtyroom = MDBX_DPL_TXNFULL; txn->mt_rw_dirtylist = env->me_dirtylist; - txn->mt_rw_dirtylist[0].mid = 0; + txn->mt_rw_dirtylist->length = 0; txn->mt_befree_pages = env->me_free_pgs; - txn->mt_befree_pages[0] = 0; + MDBX_PNL_SIZE(txn->mt_befree_pages) = 0; txn->mt_spill_pages = NULL; if (txn->mt_lifo_reclaimed) - txn->mt_lifo_reclaimed[0] = 0; + MDBX_PNL_SIZE(txn->mt_lifo_reclaimed) = 0; env->me_txn = txn; memcpy(txn->mt_dbiseqs, env->me_dbiseqs, env->me_maxdbs * sizeof(unsigned)); /* Copy the DB info and flags */ @@ -3195,16 +3280,16 @@ int mdbx_txn_begin(MDBX_env *env, MDBX_txn *parent, unsigned flags, unsigned i; txn->mt_cursors = (MDBX_cursor **)(txn->mt_dbs + env->me_maxdbs); txn->mt_dbiseqs = parent->mt_dbiseqs; - txn->mt_rw_dirtylist = malloc(sizeof(MDBX_ID2) * MDBX_PNL_UM_SIZE); + txn->mt_rw_dirtylist = malloc(sizeof(MDBX_DP) * (MDBX_DPL_TXNFULL + 1)); if (!txn->mt_rw_dirtylist || - !(txn->mt_befree_pages = mdbx_pnl_alloc(MDBX_PNL_UM_MAX))) { + !(txn->mt_befree_pages = mdbx_pnl_alloc(MDBX_PNL_INITIAL))) { free(txn->mt_rw_dirtylist); free(txn); return MDBX_ENOMEM; } txn->mt_txnid = parent->mt_txnid; txn->mt_dirtyroom = parent->mt_dirtyroom; - txn->mt_rw_dirtylist[0].mid = 0; + txn->mt_rw_dirtylist->length = 0; txn->mt_spill_pages = NULL; txn->mt_next_pgno = parent->mt_next_pgno; txn->mt_end_pgno = parent->mt_end_pgno; @@ -3222,7 +3307,8 @@ int mdbx_txn_begin(MDBX_env *env, MDBX_txn *parent, unsigned flags, env->me_pgstate; /* save parent me_reclaimed_pglist & co */ if (env->me_reclaimed_pglist) { size = MDBX_PNL_SIZEOF(env->me_reclaimed_pglist); - env->me_reclaimed_pglist = mdbx_pnl_alloc(env->me_reclaimed_pglist[0]); + env->me_reclaimed_pglist = + mdbx_pnl_alloc(MDBX_PNL_SIZE(env->me_reclaimed_pglist)); if (likely(env->me_reclaimed_pglist)) memcpy(env->me_reclaimed_pglist, ntxn->mnt_pgstate.mf_reclaimed_pglist, size); @@ -3361,7 +3447,7 @@ static int mdbx_txn_end(MDBX_txn *txn, unsigned mode) { } if (txn->mt_lifo_reclaimed) { - txn->mt_lifo_reclaimed[0] = 0; + MDBX_PNL_SIZE(txn->mt_lifo_reclaimed) = 0; if (txn != env->me_txn0) { mdbx_txl_free(txn->mt_lifo_reclaimed); txn->mt_lifo_reclaimed = NULL; @@ -3448,10 +3534,12 @@ int mdbx_txn_abort(MDBX_txn *txn) { } static __inline int mdbx_backlog_size(MDBX_txn *txn) { - int reclaimed = txn->mt_env->me_reclaimed_pglist - ? txn->mt_env->me_reclaimed_pglist[0] - : 0; - return reclaimed + txn->mt_loose_count + txn->mt_end_pgno - txn->mt_next_pgno; + int reclaimed_and_loose = + txn->mt_env->me_reclaimed_pglist + ? MDBX_PNL_SIZE(txn->mt_env->me_reclaimed_pglist) + + txn->mt_loose_count + : 0; + return reclaimed_and_loose + txn->mt_end_pgno - txn->mt_next_pgno; } static __inline int mdbx_backlog_extragap(MDBX_env *env) { @@ -3485,139 +3573,292 @@ static int mdbx_prep_backlog(MDBX_txn *txn, MDBX_cursor *mc) { return MDBX_SUCCESS; } -/* Save the freelist as of this transaction to the freeDB. - * This changes the freelist. Keep trying until it stabilizes. */ -static int mdbx_freelist_save(MDBX_txn *txn) { +/* Count all the pages in each DB and in the freelist and make sure + * it matches the actual number of pages being used. + * All named DBs must be open for a correct count. */ +static int mdbx_audit(MDBX_txn *txn, unsigned befree_stored) { + MDBX_val key, data; + + const pgno_t pending = + (txn->mt_flags & MDBX_RDONLY) + ? 0 + : txn->mt_loose_count + + (txn->mt_env->me_reclaimed_pglist + ? MDBX_PNL_SIZE(txn->mt_env->me_reclaimed_pglist) + : 0) + + (txn->mt_befree_pages + ? MDBX_PNL_SIZE(txn->mt_befree_pages) - befree_stored + : 0); + + MDBX_cursor_couple cx; + int rc = mdbx_cursor_init(&cx.outer, txn, FREE_DBI); + if (unlikely(rc != MDBX_SUCCESS)) + return rc; + + pgno_t freecount = 0; + while ((rc = mdbx_cursor_get(&cx.outer, &key, &data, MDBX_NEXT)) == 0) + freecount += *(pgno_t *)data.iov_base; + mdbx_tassert(txn, rc == MDBX_NOTFOUND); + + pgno_t count = 0; + for (MDBX_dbi i = FREE_DBI; i <= MAIN_DBI; i++) { + if (!(txn->mt_dbflags[i] & DB_VALID)) + continue; + rc = mdbx_cursor_init(&cx.outer, txn, i); + if (unlikely(rc != MDBX_SUCCESS)) + return rc; + if (txn->mt_dbs[i].md_root == P_INVALID) + continue; + count += txn->mt_dbs[i].md_branch_pages + txn->mt_dbs[i].md_leaf_pages + + txn->mt_dbs[i].md_overflow_pages; + + rc = mdbx_page_search(&cx.outer, NULL, MDBX_PS_FIRST); + while (rc == MDBX_SUCCESS) { + MDBX_page *mp = cx.outer.mc_pg[cx.outer.mc_top]; + for (unsigned j = 0; j < NUMKEYS(mp); j++) { + MDBX_node *leaf = NODEPTR(mp, j); + if ((leaf->mn_flags & (F_DUPDATA | F_SUBDATA)) == F_SUBDATA) { + MDBX_db db_copy, *db; + memcpy(db = &db_copy, NODEDATA(leaf), sizeof(db_copy)); + if ((txn->mt_flags & MDBX_RDONLY) == 0) { + for (MDBX_dbi k = txn->mt_numdbs; --k > MAIN_DBI;) { + if ((txn->mt_dbflags[k] & MDBX_TBL_DIRTY) && + /* txn->mt_dbxs[k].md_name.iov_len > 0 && */ + NODEKSZ(leaf) == txn->mt_dbxs[k].md_name.iov_len && + memcmp(NODEKEY(leaf), txn->mt_dbxs[k].md_name.iov_base, + NODEKSZ(leaf)) == 0) { + db = txn->mt_dbs + k; + break; + } + } + } + count += + db->md_branch_pages + db->md_leaf_pages + db->md_overflow_pages; + } + } + rc = mdbx_cursor_sibling(&cx.outer, 1); + } + mdbx_tassert(txn, rc == MDBX_NOTFOUND); + } + + if (pending + freecount + count + NUM_METAS == txn->mt_next_pgno) + return MDBX_SUCCESS; + + if ((txn->mt_flags & MDBX_RDONLY) == 0) + mdbx_error("audit @%" PRIaTXN ": %u(pending) = %u(loose-count) + " + "%u(reclaimed-list) + %u(befree-pending) - %u(befree-stored)", + txn->mt_txnid, pending, txn->mt_loose_count, + txn->mt_env->me_reclaimed_pglist + ? MDBX_PNL_SIZE(txn->mt_env->me_reclaimed_pglist) + : 0, + txn->mt_befree_pages ? MDBX_PNL_SIZE(txn->mt_befree_pages) : 0, + befree_stored); + mdbx_error("audit @%" PRIaTXN ": %" PRIaPGNO "(pending) + %" PRIaPGNO + "(free) + %" PRIaPGNO "(count) = %" PRIaPGNO + "(total) <> %" PRIaPGNO "(next-pgno)", + txn->mt_txnid, pending, freecount, count + NUM_METAS, + pending + freecount + count + NUM_METAS, txn->mt_next_pgno); + return MDBX_PROBLEM; +} + +/* Cleanup reclaimed GC records, than save the befree-list as of this + * transaction to GC (aka freeDB). This recursive changes the reclaimed-list + * loose-list and befree-list. Keep trying until it stabilizes. */ +static int mdbx_update_gc(MDBX_txn *txn) { /* env->me_reclaimed_pglist[] can grow and shrink during this call. - * env->me_last_reclaimed and txn->mt_free_pages[] can only grow. - * Page numbers cannot disappear from txn->mt_free_pages[]. */ - MDBX_cursor mc; - MDBX_env *env = txn->mt_env; - int rc, more = 1; - txnid_t cleanup_reclaimed_id = 0, head_id = 0; - pgno_t befree_count = 0; - intptr_t head_room = 0, total_room = 0; - unsigned cleanup_reclaimed_pos = 0, refill_reclaimed_pos = 0; + * env->me_last_reclaimed and txn->mt_befree_pages[] can only grow. + * Page numbers cannot disappear from txn->mt_befree_pages[]. */ + MDBX_env *const env = txn->mt_env; const bool lifo = (env->me_flags & MDBX_LIFORECLAIM) != 0; + const char *dbg_prefix_mode = lifo ? " lifo" : " fifo"; + (void)dbg_prefix_mode; + mdbx_trace("\n>>> @%" PRIaTXN, txn->mt_txnid); - rc = mdbx_cursor_init(&mc, txn, FREE_DBI, NULL); + MDBX_cursor mc; + int rc = mdbx_cursor_init(&mc, txn, FREE_DBI); if (unlikely(rc != MDBX_SUCCESS)) return rc; - /* MDBX_RESERVE cancels meminit in ovpage malloc (when no WRITEMAP) */ - const intptr_t clean_limit = - (env->me_flags & (MDBX_NOMEMINIT | MDBX_WRITEMAP)) ? SSIZE_MAX - : env->me_maxfree_1pg; + unsigned befree_stored = 0, loop = 0; + +retry: + mdbx_trace(" >> restart"); + mdbx_tassert(txn, mdbx_pnl_check(env->me_reclaimed_pglist, true)); + unsigned settled = 0, cleaned_gc_slot = 0, reused_gc_slots = 0, + filled_gc_slot = ~0u; + txnid_t cleaned_gc_id = 0, head_gc_id = env->me_last_reclaimed + ? env->me_last_reclaimed + : ~(txnid_t)0; + + if (unlikely(/* paranoia */ ++loop > 42)) { + mdbx_error("too more loops %u, bailout", loop); + rc = MDBX_PROBLEM; + goto bailout; + } - mdbx_tassert(txn, mdbx_pnl_check(env->me_reclaimed_pglist)); -again_on_freelist_change: - mdbx_tassert(txn, mdbx_pnl_check(env->me_reclaimed_pglist)); while (1) { - /* Come back here after each Put() in case freelist changed */ + /* Come back here after each Put() in case befree-list changed */ MDBX_val key, data; + mdbx_trace(" >> continue"); - mdbx_tassert(txn, mdbx_pnl_check(env->me_reclaimed_pglist)); - if (!lifo) { + mdbx_tassert(txn, mdbx_pnl_check(env->me_reclaimed_pglist, true)); + if (txn->mt_lifo_reclaimed) { + if (cleaned_gc_slot < MDBX_PNL_SIZE(txn->mt_lifo_reclaimed)) { + settled = 0; + cleaned_gc_slot = 0; + reused_gc_slots = 0; + filled_gc_slot = ~0u; + /* LY: cleanup reclaimed records. */ + do { + cleaned_gc_id = txn->mt_lifo_reclaimed[++cleaned_gc_slot]; + assert(cleaned_gc_slot > 0 && cleaned_gc_id < *env->me_oldest); + head_gc_id = + (head_gc_id > cleaned_gc_id) ? cleaned_gc_id : head_gc_id; + key.iov_base = &cleaned_gc_id; + key.iov_len = sizeof(cleaned_gc_id); + rc = mdbx_cursor_get(&mc, &key, NULL, MDBX_SET); + if (rc == MDBX_NOTFOUND) + continue; + if (unlikely(rc != MDBX_SUCCESS)) + goto bailout; + rc = mdbx_prep_backlog(txn, &mc); + if (unlikely(rc != MDBX_SUCCESS)) + goto bailout; + mdbx_tassert(txn, cleaned_gc_id < *env->me_oldest); + mdbx_trace("%s.cleanup-reclaimed-id [%u]%" PRIaTXN, dbg_prefix_mode, + cleaned_gc_slot, cleaned_gc_id); + mc.mc_flags |= C_RECLAIMING; + WITH_CURSOR_TRACKING(mc, rc = mdbx_cursor_del(&mc, 0)); + mc.mc_flags ^= C_RECLAIMING; + if (unlikely(rc != MDBX_SUCCESS)) + goto bailout; + } while (cleaned_gc_slot < MDBX_PNL_SIZE(txn->mt_lifo_reclaimed)); + mdbx_txl_sort(txn->mt_lifo_reclaimed); + assert(MDBX_PNL_LAST(txn->mt_lifo_reclaimed) == head_gc_id); + } + } else { /* If using records from freeDB which we have not yet deleted, * now delete them and any we reserved for me_reclaimed_pglist. */ - while (cleanup_reclaimed_id < env->me_last_reclaimed) { + while (cleaned_gc_id < env->me_last_reclaimed) { rc = mdbx_cursor_first(&mc, &key, NULL); - if (unlikely(rc)) + if (unlikely(rc != MDBX_SUCCESS)) goto bailout; rc = mdbx_prep_backlog(txn, &mc); - if (unlikely(rc)) + if (unlikely(rc != MDBX_SUCCESS)) goto bailout; - cleanup_reclaimed_id = head_id = *(txnid_t *)key.iov_base; - total_room = head_room = 0; - more = 1; - mdbx_tassert(txn, cleanup_reclaimed_id <= env->me_last_reclaimed); + cleaned_gc_id = head_gc_id = *(txnid_t *)key.iov_base; + mdbx_tassert(txn, cleaned_gc_id < *env->me_oldest); + mdbx_tassert(txn, cleaned_gc_id <= env->me_last_reclaimed); + mdbx_trace("%s.cleanup-reclaimed-id %" PRIaTXN, dbg_prefix_mode, + cleaned_gc_id); mc.mc_flags |= C_RECLAIMING; - rc = mdbx_cursor_del(&mc, 0); + WITH_CURSOR_TRACKING(mc, rc = mdbx_cursor_del(&mc, 0)); mc.mc_flags ^= C_RECLAIMING; - if (unlikely(rc)) + if (unlikely(rc != MDBX_SUCCESS)) goto bailout; - } - } else if (txn->mt_lifo_reclaimed) { - /* LY: cleanup reclaimed records. */ - while (cleanup_reclaimed_pos < txn->mt_lifo_reclaimed[0]) { - cleanup_reclaimed_id = txn->mt_lifo_reclaimed[++cleanup_reclaimed_pos]; - key.iov_base = &cleanup_reclaimed_id; - key.iov_len = sizeof(cleanup_reclaimed_id); - rc = mdbx_cursor_get(&mc, &key, NULL, MDBX_SET); - if (likely(rc != MDBX_NOTFOUND)) { - if (unlikely(rc)) - goto bailout; - rc = mdbx_prep_backlog(txn, &mc); - if (unlikely(rc)) - goto bailout; - mc.mc_flags |= C_RECLAIMING; - rc = mdbx_cursor_del(&mc, 0); - mc.mc_flags ^= C_RECLAIMING; - if (unlikely(rc)) - goto bailout; - } + settled = 0; } } - mdbx_tassert(txn, mdbx_pnl_check(env->me_reclaimed_pglist)); + // handle loose pages - put ones into the reclaimed- or befree-list + mdbx_tassert(txn, mdbx_pnl_check(env->me_reclaimed_pglist, true)); if (txn->mt_loose_pages) { /* Return loose page numbers to me_reclaimed_pglist, * though usually none are left at this point. * The pages themselves remain in dirtylist. */ - if (unlikely(!env->me_reclaimed_pglist) && - !(lifo && env->me_last_reclaimed > 1)) { - /* Put loose page numbers in mt_free_pages, + if (unlikely(!env->me_reclaimed_pglist) && !txn->mt_lifo_reclaimed && + env->me_last_reclaimed < 1) { + /* Put loose page numbers in mt_befree_pages, * since unable to return them to me_reclaimed_pglist. */ if (unlikely((rc = mdbx_pnl_need(&txn->mt_befree_pages, txn->mt_loose_count)) != 0)) return rc; for (MDBX_page *mp = txn->mt_loose_pages; mp; mp = NEXT_LOOSE_PAGE(mp)) mdbx_pnl_xappend(txn->mt_befree_pages, mp->mp_pgno); + mdbx_trace("%s: append %u loose-pages to befree-pages", dbg_prefix_mode, + txn->mt_loose_count); } else { /* Room for loose pages + temp PNL with same */ - if ((rc = mdbx_pnl_need(&env->me_reclaimed_pglist, - 2 * txn->mt_loose_count + 1)) != 0) - goto bailout; - MDBX_PNL loose = env->me_reclaimed_pglist + - MDBX_PNL_ALLOCLEN(env->me_reclaimed_pglist) - - txn->mt_loose_count; - unsigned count = 0; - for (MDBX_page *mp = txn->mt_loose_pages; mp; mp = NEXT_LOOSE_PAGE(mp)) - loose[++count] = mp->mp_pgno; - loose[0] = count; - mdbx_pnl_sort(loose); - mdbx_pnl_xmerge(env->me_reclaimed_pglist, loose); + if (likely(env->me_reclaimed_pglist != NULL)) { + rc = mdbx_pnl_need(&env->me_reclaimed_pglist, + 2 * txn->mt_loose_count + 2); + if (unlikely(rc != MDBX_SUCCESS)) + goto bailout; + MDBX_PNL loose = env->me_reclaimed_pglist + + MDBX_PNL_ALLOCLEN(env->me_reclaimed_pglist) - + txn->mt_loose_count - 1; + unsigned count = 0; + for (MDBX_page *mp = txn->mt_loose_pages; mp; + mp = NEXT_LOOSE_PAGE(mp)) + loose[++count] = mp->mp_pgno; + MDBX_PNL_SIZE(loose) = count; + mdbx_pnl_sort(loose); + mdbx_pnl_xmerge(env->me_reclaimed_pglist, loose); + } else { + env->me_reclaimed_pglist = mdbx_pnl_alloc(txn->mt_loose_count); + if (unlikely(env->me_reclaimed_pglist == NULL)) { + rc = MDBX_ENOMEM; + goto bailout; + } + for (MDBX_page *mp = txn->mt_loose_pages; mp; + mp = NEXT_LOOSE_PAGE(mp)) + mdbx_pnl_xappend(env->me_reclaimed_pglist, mp->mp_pgno); + mdbx_pnl_sort(env->me_reclaimed_pglist); + } + mdbx_trace("%s: append %u loose-pages to reclaimed-pages", + dbg_prefix_mode, txn->mt_loose_count); } - MDBX_ID2L dl = txn->mt_rw_dirtylist; + // filter-out list of dirty-pages from loose-pages + MDBX_DPL dl = txn->mt_rw_dirtylist; + mdbx_dpl_sort(dl); + unsigned left = dl->length; for (MDBX_page *mp = txn->mt_loose_pages; mp;) { mdbx_tassert(txn, mp->mp_pgno < txn->mt_next_pgno); mdbx_ensure(env, mp->mp_pgno >= NUM_METAS); - unsigned s, d; - for (s = d = 0; ++s <= dl[0].mid;) - if (dl[s].mid != mp->mp_pgno) - dl[++d] = dl[s]; - - dl[0].mid -= 1; - mdbx_tassert(txn, dl[0].mid == d); + if (left > 0) { + const unsigned i = mdbx_dpl_search(dl, mp->mp_pgno); + if (i <= dl->length && dl[i].pgno == mp->mp_pgno) { + mdbx_tassert(txn, i > 0 && dl[i].ptr != dl); + dl[i].ptr = dl /* mark for deletion */; + } + left -= 1; + } MDBX_page *dp = mp; mp = NEXT_LOOSE_PAGE(mp); if ((env->me_flags & MDBX_WRITEMAP) == 0) - mdbx_dpage_free(env, dp); + mdbx_dpage_free(env, dp, 1); } + if (left > 0) { + MDBX_DPL r, w, end = dl + dl->length; + for (r = w = dl + 1; r <= end; r++) { + if (r->ptr != dl) { + if (r != w) + *w = *r; + ++w; + } + } + mdbx_tassert(txn, w - dl == (int)left + 1); + } + + if (left != dl->length) + mdbx_trace("%s: filtered-out loose-pages from %u -> %u dirty-pages", + dbg_prefix_mode, dl->length, left); + dl->length = left; + txn->mt_loose_pages = NULL; txn->mt_loose_count = 0; } - mdbx_tassert(txn, mdbx_pnl_check(env->me_reclaimed_pglist)); + // handle reclaimed pages - return suitable into unallocated space + mdbx_tassert(txn, mdbx_pnl_check(env->me_reclaimed_pglist, true)); if (env->me_reclaimed_pglist) { - /* Refund suitable pages into "unallocated" space */ pgno_t tail = txn->mt_next_pgno; - pgno_t *const begin = env->me_reclaimed_pglist + 1; - pgno_t *const end = begin + env->me_reclaimed_pglist[0]; + pgno_t *const begin = MDBX_PNL_BEGIN(env->me_reclaimed_pglist); + pgno_t *const end = MDBX_PNL_END(env->me_reclaimed_pglist); pgno_t *higest; #if MDBX_PNL_ASCENDING for (higest = end; --higest >= begin;) { @@ -3631,250 +3872,387 @@ again_on_freelist_change: } if (tail != txn->mt_next_pgno) { #if MDBX_PNL_ASCENDING - env->me_reclaimed_pglist[0] = (unsigned)(higest + 1 - begin); + MDBX_PNL_SIZE(env->me_reclaimed_pglist) = + (unsigned)(higest + 1 - begin); #else - env->me_reclaimed_pglist[0] -= (unsigned)(higest - begin); + MDBX_PNL_SIZE(env->me_reclaimed_pglist) -= (unsigned)(higest - begin); for (pgno_t *move = begin; higest < end; ++move, ++higest) *move = *higest; #endif /* MDBX_PNL sort-order */ - mdbx_info("refunded %" PRIaPGNO " pages: %" PRIaPGNO " -> %" PRIaPGNO, - tail - txn->mt_next_pgno, tail, txn->mt_next_pgno); + mdbx_info( + "%s.refunded %" PRIaPGNO " pages: %" PRIaPGNO " -> %" PRIaPGNO, + dbg_prefix_mode, txn->mt_next_pgno - tail, tail, txn->mt_next_pgno); txn->mt_next_pgno = tail; - mdbx_tassert(txn, mdbx_pnl_check(env->me_reclaimed_pglist)); + mdbx_tassert(txn, mdbx_pnl_check(env->me_reclaimed_pglist, true)); } } - /* Save the PNL of pages freed by this txn, to a single record */ - if (befree_count < txn->mt_befree_pages[0]) { - if (unlikely(!befree_count)) { - /* Make sure last page of freeDB is touched and on freelist */ + // handle befree-list - store ones into singe gc-record + if (befree_stored < MDBX_PNL_SIZE(txn->mt_befree_pages)) { + if (unlikely(!befree_stored)) { + /* Make sure last page of freeDB is touched and on befree-list */ rc = mdbx_page_search(&mc, NULL, MDBX_PS_LAST | MDBX_PS_MODIFY); - if (unlikely(rc && rc != MDBX_NOTFOUND)) + if (unlikely(rc != MDBX_SUCCESS && rc != MDBX_NOTFOUND)) goto bailout; } - pgno_t *befree_pages = txn->mt_befree_pages; /* Write to last page of freeDB */ key.iov_len = sizeof(txn->mt_txnid); key.iov_base = &txn->mt_txnid; do { - befree_count = befree_pages[0]; - data.iov_len = MDBX_PNL_SIZEOF(befree_pages); - rc = mdbx_cursor_put(&mc, &key, &data, MDBX_RESERVE); - if (unlikely(rc)) + data.iov_len = MDBX_PNL_SIZEOF(txn->mt_befree_pages); + WITH_CURSOR_TRACKING( + mc, rc = mdbx_cursor_put(&mc, &key, &data, MDBX_RESERVE)); + if (unlikely(rc != MDBX_SUCCESS)) goto bailout; - /* Retry if mt_free_pages[] grew during the Put() */ - befree_pages = txn->mt_befree_pages; - } while (befree_count < befree_pages[0]); + /* Retry if mt_befree_pages[] grew during the Put() */ + } while (data.iov_len < MDBX_PNL_SIZEOF(txn->mt_befree_pages)); + + befree_stored = (unsigned)MDBX_PNL_SIZE(txn->mt_befree_pages); + mdbx_pnl_sort(txn->mt_befree_pages); + memcpy(data.iov_base, txn->mt_befree_pages, data.iov_len); - mdbx_pnl_sort(befree_pages); - memcpy(data.iov_base, befree_pages, data.iov_len); + mdbx_trace("%s.put-befree #%u @ %" PRIaTXN, dbg_prefix_mode, + befree_stored, txn->mt_txnid); if (mdbx_debug_enabled(MDBX_DBG_EXTRA)) { - unsigned i = (unsigned)befree_pages[0]; + unsigned i = befree_stored; mdbx_debug_extra("PNL write txn %" PRIaTXN " root %" PRIaPGNO " num %u, PNL", txn->mt_txnid, txn->mt_dbs[FREE_DBI].md_root, i); for (; i; i--) - mdbx_debug_extra_print(" %" PRIaPGNO "", befree_pages[i]); + mdbx_debug_extra_print(" %" PRIaPGNO "", txn->mt_befree_pages[i]); mdbx_debug_extra_print("\n"); } continue; } - mdbx_tassert(txn, mdbx_pnl_check(env->me_reclaimed_pglist)); - const intptr_t rpl_len = - (env->me_reclaimed_pglist ? env->me_reclaimed_pglist[0] : 0) + - txn->mt_loose_count; - if (rpl_len && refill_reclaimed_pos == 0) - refill_reclaimed_pos = 1; - - /* Reserve records for me_reclaimed_pglist[]. Split it if multi-page, - * to avoid searching freeDB for a page range. Use keys in - * range [1,me_last_reclaimed]: Smaller than txnid of oldest reader. */ - if (total_room >= rpl_len) { - if (total_room == rpl_len || --more < 0) - break; - } else if (head_room >= (intptr_t)env->me_maxfree_1pg && head_id > 1) { - /* Keep current record (overflow page), add a new one */ - head_id--; - refill_reclaimed_pos++; - head_room = 0; - } + // handle reclaimed and loost pages - merge and store both into gc + mdbx_tassert(txn, mdbx_pnl_check(env->me_reclaimed_pglist, true)); + mdbx_tassert(txn, txn->mt_loose_count == 0); + + mdbx_trace(" >> reserving"); + const unsigned amount = + env->me_reclaimed_pglist ? MDBX_PNL_SIZE(env->me_reclaimed_pglist) : 0; + const unsigned left = amount - settled; + mdbx_trace("%s: amount %u, settled %d, left %d, lifo-reclaimed-slots %u, " + "reused-gc-slots %u", + dbg_prefix_mode, amount, settled, (int)left, + txn->mt_lifo_reclaimed + ? (unsigned)MDBX_PNL_SIZE(txn->mt_lifo_reclaimed) + : 0, + reused_gc_slots); + if (0 >= (int)left) + break; + const unsigned max_spread = 10; + txnid_t reservation_gc_id; if (lifo) { - if (refill_reclaimed_pos > - (txn->mt_lifo_reclaimed ? txn->mt_lifo_reclaimed[0] : 0)) { + assert(txn->mt_lifo_reclaimed != NULL); + if (unlikely(!txn->mt_lifo_reclaimed)) { + txn->mt_lifo_reclaimed = mdbx_txl_alloc(); + if (unlikely(!txn->mt_lifo_reclaimed)) { + rc = MDBX_ENOMEM; + goto bailout; + } + } + + if (head_gc_id > 1 && + MDBX_PNL_SIZE(txn->mt_lifo_reclaimed) < max_spread && + left > ((unsigned)MDBX_PNL_SIZE(txn->mt_lifo_reclaimed) - + reused_gc_slots) * + env->me_maxgc_ov1page) { /* LY: need just a txn-id for save page list. */ rc = mdbx_page_alloc(&mc, 0, NULL, MDBX_ALLOC_GC | MDBX_ALLOC_KICK); - if (likely(rc == 0)) + if (likely(rc == MDBX_SUCCESS)) { /* LY: ok, reclaimed from freedb. */ + mdbx_trace("%s: took @%" PRIaTXN " from GC, continue", + dbg_prefix_mode, MDBX_PNL_LAST(txn->mt_lifo_reclaimed)); continue; + } if (unlikely(rc != MDBX_NOTFOUND)) /* LY: other troubles... */ goto bailout; /* LY: freedb is empty, will look any free txn-id in high2low order. */ - if (unlikely(env->me_last_reclaimed < 1)) { - /* LY: not any txn in the past of freedb. */ - rc = MDBX_MAP_FULL; - goto bailout; - } - - if (unlikely(!txn->mt_lifo_reclaimed)) { - txn->mt_lifo_reclaimed = mdbx_txl_alloc(); - if (unlikely(!txn->mt_lifo_reclaimed)) { - rc = MDBX_ENOMEM; + do { + --head_gc_id; + assert(MDBX_PNL_LAST(txn->mt_lifo_reclaimed) > head_gc_id); + rc = mdbx_txl_append(&txn->mt_lifo_reclaimed, head_gc_id); + if (unlikely(rc != MDBX_SUCCESS)) goto bailout; + cleaned_gc_slot += 1 /* mark GC cleanup is not needed. */; + + mdbx_trace("%s: append @%" PRIaTXN + " to lifo-reclaimed, cleaned-gc-slot = %u", + dbg_prefix_mode, head_gc_id, cleaned_gc_slot); + } while (head_gc_id > 1 && + MDBX_PNL_SIZE(txn->mt_lifo_reclaimed) < max_spread && + left > ((unsigned)MDBX_PNL_SIZE(txn->mt_lifo_reclaimed) - + reused_gc_slots) * + env->me_maxgc_ov1page); + } + + if ((unsigned)MDBX_PNL_SIZE(txn->mt_lifo_reclaimed) <= reused_gc_slots) { + mdbx_notice("** restart: reserve depleted (reused_gc_slot %u >= " + "lifo_reclaimed %u" PRIaTXN, + reused_gc_slots, + (unsigned)MDBX_PNL_SIZE(txn->mt_lifo_reclaimed)); + goto retry; + } + const unsigned i = + (unsigned)MDBX_PNL_SIZE(txn->mt_lifo_reclaimed) - reused_gc_slots; + assert(i > 0 && i <= MDBX_PNL_SIZE(txn->mt_lifo_reclaimed)); + reservation_gc_id = txn->mt_lifo_reclaimed[i]; + mdbx_trace("%s: take @%" PRIaTXN " from lifo-reclaimed[%u]", + dbg_prefix_mode, reservation_gc_id, i); + } else { + mdbx_tassert(txn, txn->mt_lifo_reclaimed == NULL); + reservation_gc_id = head_gc_id--; + mdbx_trace("%s: take @%" PRIaTXN " from head-gc-id", dbg_prefix_mode, + reservation_gc_id); + } + + ++reused_gc_slots; + assert(txn->mt_lifo_reclaimed == NULL || + MDBX_PNL_SIZE(txn->mt_lifo_reclaimed) <= INT16_MAX); + unsigned chunk = left; + if (unlikely(chunk > env->me_maxgc_ov1page)) { + const unsigned avail_gs_slots = + txn->mt_lifo_reclaimed + ? (unsigned)MDBX_PNL_SIZE(txn->mt_lifo_reclaimed) - + reused_gc_slots + 1 + : (head_gc_id < INT16_MAX) ? (unsigned)head_gc_id : INT16_MAX; + if (avail_gs_slots > 1) { + if (chunk < env->me_maxgc_ov1page * 2) + chunk /= 2; + else { + const unsigned threshold = env->me_maxgc_ov1page * avail_gs_slots; + if (left < threshold) + chunk = env->me_maxgc_ov1page; + else { + const unsigned tail = left - threshold + env->me_maxgc_ov1page + 1; + unsigned span = 1; + unsigned avail = (unsigned)((pgno2bytes(env, span) - PAGEHDRSZ) / + sizeof(pgno_t)) /*- 1 + span */; + if (tail > avail) { + for (unsigned i = amount - span; i > 0; --i) { + if (MDBX_PNL_ASCENDING + ? (env->me_reclaimed_pglist[i] + span) + : (env->me_reclaimed_pglist[i] - span) == + env->me_reclaimed_pglist[i + span]) { + span += 1; + avail = (unsigned)((pgno2bytes(env, span) - PAGEHDRSZ) / + sizeof(pgno_t)) - + 1 + span; + if (avail >= tail) + break; + } + } + } + + chunk = (avail >= tail) ? tail - span + : (avail_gs_slots > 3 && + reused_gc_slots < max_spread - 3) + ? avail - span + : tail; } } - /* LY: append the list. */ - rc = mdbx_txl_append(&txn->mt_lifo_reclaimed, - env->me_last_reclaimed - 1); - if (unlikely(rc)) - goto bailout; - --env->me_last_reclaimed; - /* LY: note that freeDB cleanup is not needed. */ - ++cleanup_reclaimed_pos; } - mdbx_tassert(txn, txn->mt_lifo_reclaimed != NULL); - head_id = txn->mt_lifo_reclaimed[refill_reclaimed_pos]; - } else { - mdbx_tassert(txn, txn->mt_lifo_reclaimed == NULL); } + assert(chunk > 0); - /* (Re)write {key = head_id, PNL length = head_room} */ - total_room -= head_room; - head_room = rpl_len - total_room; - if (head_room > (intptr_t)env->me_maxfree_1pg && head_id > 1) { - /* Overflow multi-page for part of me_reclaimed_pglist */ - head_room /= (head_id < INT16_MAX) ? (pgno_t)head_id - : INT16_MAX; /* amortize page sizes */ - head_room += env->me_maxfree_1pg - head_room % (env->me_maxfree_1pg + 1); - } else if (head_room < 0) { - /* Rare case, not bothering to delete this record */ - head_room = 0; - continue; + mdbx_trace("%s: head_gc_id %" PRIaTXN ", reused_gc_slot %u, reservation-id " + "%" PRIaTXN, + dbg_prefix_mode, head_gc_id, reused_gc_slots, reservation_gc_id); + + mdbx_trace("%s: chunk %u, gc-per-ovpage %u", dbg_prefix_mode, chunk, + env->me_maxgc_ov1page); + + mdbx_tassert(txn, reservation_gc_id < *env->me_oldest); + if (unlikely(reservation_gc_id < 1 || + reservation_gc_id >= *env->me_oldest)) { + /* LY: not any txn in the past of freedb. */ + rc = MDBX_PROBLEM; + goto bailout; } - key.iov_len = sizeof(head_id); - key.iov_base = &head_id; - data.iov_len = (head_room + 1) * sizeof(pgno_t); - rc = mdbx_cursor_put(&mc, &key, &data, MDBX_RESERVE); - mdbx_tassert(txn, mdbx_pnl_check(env->me_reclaimed_pglist)); - if (unlikely(rc)) + + key.iov_len = sizeof(reservation_gc_id); + key.iov_base = &reservation_gc_id; + data.iov_len = (chunk + 1) * sizeof(pgno_t); + mdbx_trace("%s.reserve: %u [%u...%u] @%" PRIaTXN, dbg_prefix_mode, chunk, + settled + 1, settled + chunk + 1, reservation_gc_id); + WITH_CURSOR_TRACKING(mc, + rc = mdbx_cursor_put(&mc, &key, &data, + MDBX_RESERVE | MDBX_NOOVERWRITE)); + mdbx_tassert(txn, mdbx_pnl_check(env->me_reclaimed_pglist, true)); + if (unlikely(rc != MDBX_SUCCESS)) goto bailout; /* PNL is initially empty, zero out at least the length */ - pgno_t *pgs = (pgno_t *)data.iov_base; - intptr_t i = head_room > clean_limit ? head_room : 0; - do { - pgs[i] = 0; - } while (--i >= 0); - total_room += head_room; + memset(data.iov_base, 0, sizeof(pgno_t)); + settled += chunk; + mdbx_trace("%s.settled %u (+%u), continue", dbg_prefix_mode, settled, + chunk); continue; } - mdbx_tassert(txn, - cleanup_reclaimed_pos == - (txn->mt_lifo_reclaimed ? txn->mt_lifo_reclaimed[0] : 0)); + mdbx_tassert( + txn, + cleaned_gc_slot == + (txn->mt_lifo_reclaimed ? MDBX_PNL_SIZE(txn->mt_lifo_reclaimed) : 0)); - /* Fill in the reserved me_reclaimed_pglist records */ + mdbx_trace(" >> filling"); + /* Fill in the reserved records */ + filled_gc_slot = + txn->mt_lifo_reclaimed + ? (unsigned)MDBX_PNL_SIZE(txn->mt_lifo_reclaimed) - reused_gc_slots + : reused_gc_slots; rc = MDBX_SUCCESS; - mdbx_tassert(txn, mdbx_pnl_check(env->me_reclaimed_pglist)); - if (env->me_reclaimed_pglist && env->me_reclaimed_pglist[0]) { + mdbx_tassert(txn, mdbx_pnl_check(env->me_reclaimed_pglist, true)); + if (env->me_reclaimed_pglist && MDBX_PNL_SIZE(env->me_reclaimed_pglist)) { MDBX_val key, data; key.iov_len = data.iov_len = 0; /* avoid MSVC warning */ key.iov_base = data.iov_base = NULL; - size_t rpl_left = env->me_reclaimed_pglist[0]; - pgno_t *rpl_end = env->me_reclaimed_pglist + rpl_left; - if (txn->mt_lifo_reclaimed == 0) { + const unsigned amount = MDBX_PNL_SIZE(env->me_reclaimed_pglist); + unsigned left = amount; + if (txn->mt_lifo_reclaimed == nullptr) { mdbx_tassert(txn, lifo == 0); rc = mdbx_cursor_first(&mc, &key, &data); - if (unlikely(rc)) + if (unlikely(rc != MDBX_SUCCESS)) goto bailout; } else { mdbx_tassert(txn, lifo != 0); } while (1) { - txnid_t id; - if (txn->mt_lifo_reclaimed == 0) { + txnid_t fill_gc_id; + mdbx_trace("%s: left %u of %u", dbg_prefix_mode, left, + (unsigned)MDBX_PNL_SIZE(env->me_reclaimed_pglist)); + if (txn->mt_lifo_reclaimed == nullptr) { mdbx_tassert(txn, lifo == 0); - id = *(txnid_t *)key.iov_base; - mdbx_tassert(txn, id <= env->me_last_reclaimed); + fill_gc_id = *(txnid_t *)key.iov_base; + if (filled_gc_slot-- == 0 || fill_gc_id > env->me_last_reclaimed) { + mdbx_notice( + "** restart: reserve depleted (filled_slot %u, fill_id %" PRIaTXN + " > last_reclaimed %" PRIaTXN, + filled_gc_slot, fill_gc_id, env->me_last_reclaimed); + goto retry; + } } else { mdbx_tassert(txn, lifo != 0); - mdbx_tassert(txn, - refill_reclaimed_pos > 0 && - refill_reclaimed_pos <= txn->mt_lifo_reclaimed[0]); - id = txn->mt_lifo_reclaimed[refill_reclaimed_pos--]; - key.iov_base = &id; - key.iov_len = sizeof(id); - rc = mdbx_cursor_get(&mc, &key, &data, MDBX_SET); - if (unlikely(rc)) + if (++filled_gc_slot > + (unsigned)MDBX_PNL_SIZE(txn->mt_lifo_reclaimed)) { + mdbx_notice("** restart: reserve depleted (filled_gc_slot %u > " + "lifo_reclaimed %u" PRIaTXN, + filled_gc_slot, + (unsigned)MDBX_PNL_SIZE(txn->mt_lifo_reclaimed)); + goto retry; + } + fill_gc_id = txn->mt_lifo_reclaimed[filled_gc_slot]; + mdbx_trace("%s.seek-reservation @%" PRIaTXN " at lifo_reclaimed[%u]", + dbg_prefix_mode, fill_gc_id, filled_gc_slot); + key.iov_base = &fill_gc_id; + key.iov_len = sizeof(fill_gc_id); + rc = mdbx_cursor_get(&mc, &key, &data, MDBX_SET_KEY); + if (unlikely(rc != MDBX_SUCCESS)) goto bailout; } - mdbx_tassert( - txn, cleanup_reclaimed_pos == - (txn->mt_lifo_reclaimed ? txn->mt_lifo_reclaimed[0] : 0)); + mdbx_tassert(txn, cleaned_gc_slot == + (txn->mt_lifo_reclaimed + ? MDBX_PNL_SIZE(txn->mt_lifo_reclaimed) + : 0)); + mdbx_tassert(txn, fill_gc_id > 0 && fill_gc_id < *env->me_oldest); + key.iov_base = &fill_gc_id; + key.iov_len = sizeof(fill_gc_id); mdbx_tassert(txn, data.iov_len >= sizeof(pgno_t) * 2); - size_t chunk_len = (data.iov_len / sizeof(pgno_t)) - 1; - if (chunk_len > rpl_left) - chunk_len = rpl_left; - data.iov_len = (chunk_len + 1) * sizeof(pgno_t); - key.iov_base = &id; - key.iov_len = sizeof(id); - - rpl_end -= chunk_len; - data.iov_base = rpl_end; - pgno_t save = rpl_end[0]; - rpl_end[0] = (pgno_t)chunk_len; - mdbx_tassert(txn, mdbx_pnl_check(rpl_end)); - mc.mc_flags |= C_RECLAIMING; - rc = mdbx_cursor_put(&mc, &key, &data, MDBX_CURRENT); - mc.mc_flags ^= C_RECLAIMING; - mdbx_tassert(txn, mdbx_pnl_check(rpl_end)); - mdbx_tassert( - txn, cleanup_reclaimed_pos == - (txn->mt_lifo_reclaimed ? txn->mt_lifo_reclaimed[0] : 0)); - rpl_end[0] = save; - if (unlikely(rc)) + mc.mc_flags |= C_RECLAIMING | C_GCFREEZE; + unsigned chunk = (unsigned)(data.iov_len / sizeof(pgno_t)) - 1; + if (unlikely(chunk > left)) { + mdbx_trace("%s: chunk %u > left %u, @%" PRIaTXN, dbg_prefix_mode, chunk, + left, fill_gc_id); + chunk = left; + if (loop < 3) { + mc.mc_flags ^= C_GCFREEZE; + data.iov_len = (left + 1) * sizeof(pgno_t); + } + } + WITH_CURSOR_TRACKING( + mc, + rc = mdbx_cursor_put(&mc, &key, &data, MDBX_CURRENT | MDBX_RESERVE)); + mc.mc_flags &= ~(C_RECLAIMING | C_GCFREEZE); + if (unlikely(rc != MDBX_SUCCESS)) goto bailout; - rpl_left -= chunk_len; - if (rpl_left == 0) + if (unlikely(txn->mt_loose_count || + amount != MDBX_PNL_SIZE(env->me_reclaimed_pglist))) { + memset(data.iov_base, 0, sizeof(pgno_t)); + mdbx_notice("** restart: reclaimed-list changed (%u -> %u, %u)", amount, + MDBX_PNL_SIZE(env->me_reclaimed_pglist), + txn->mt_loose_count); + goto retry; + } + if (unlikely(txn->mt_lifo_reclaimed + ? cleaned_gc_slot < MDBX_PNL_SIZE(txn->mt_lifo_reclaimed) + : cleaned_gc_id < env->me_last_reclaimed)) { + memset(data.iov_base, 0, sizeof(pgno_t)); + mdbx_notice("** restart: reclaimed-slots changed"); + goto retry; + } + + pgno_t *dst = data.iov_base; + *dst++ = chunk; + pgno_t *src = MDBX_PNL_BEGIN(env->me_reclaimed_pglist) + left - chunk; + memcpy(dst, src, chunk * sizeof(pgno_t)); + pgno_t *from = src, *to = src + chunk; + mdbx_trace("%s.fill: %u [ %u:%" PRIaPGNO "...%u:%" PRIaPGNO + "] @%" PRIaTXN, + dbg_prefix_mode, chunk, + (unsigned)(from - env->me_reclaimed_pglist), from[0], + (unsigned)(to - env->me_reclaimed_pglist), to[-1], fill_gc_id); + + left -= chunk; + if (left == 0) { + rc = MDBX_SUCCESS; break; + } - if (!lifo) { + if (txn->mt_lifo_reclaimed == nullptr) { + mdbx_tassert(txn, lifo == 0); rc = mdbx_cursor_next(&mc, &key, &data, MDBX_NEXT); - if (unlikely(rc)) + if (unlikely(rc != MDBX_SUCCESS)) goto bailout; + } else { + mdbx_tassert(txn, lifo != 0); } } } + mdbx_tassert(txn, rc == MDBX_SUCCESS); + if (unlikely(txn->mt_loose_count != 0 || + filled_gc_slot != + (txn->mt_lifo_reclaimed + ? (unsigned)MDBX_PNL_SIZE(txn->mt_lifo_reclaimed) + : 0))) { + mdbx_notice("** restart: reserve excess (filled-slot %u, loose-count %u)", + filled_gc_slot, txn->mt_loose_count); + goto retry; + } + bailout: if (txn->mt_lifo_reclaimed) { - mdbx_tassert(txn, rc || cleanup_reclaimed_pos == txn->mt_lifo_reclaimed[0]); - if (rc == MDBX_SUCCESS && - cleanup_reclaimed_pos != txn->mt_lifo_reclaimed[0]) { - mdbx_tassert(txn, cleanup_reclaimed_pos < txn->mt_lifo_reclaimed[0]); - /* LY: zeroed cleanup_idx to force cleanup - * and refill created freeDB records. */ - cleanup_reclaimed_pos = 0; - /* LY: restart filling */ - total_room = head_room = refill_reclaimed_pos = 0; - more = 1; - goto again_on_freelist_change; - } - txn->mt_lifo_reclaimed[0] = 0; + mdbx_tassert(txn, + rc != MDBX_SUCCESS || + cleaned_gc_slot == MDBX_PNL_SIZE(txn->mt_lifo_reclaimed)); + MDBX_PNL_SIZE(txn->mt_lifo_reclaimed) = 0; if (txn != env->me_txn0) { mdbx_txl_free(txn->mt_lifo_reclaimed); txn->mt_lifo_reclaimed = NULL; } } + mdbx_trace("<<< %u loops, rc = %d", loop, rc); return rc; } @@ -3884,8 +4262,8 @@ bailout: * Returns 0 on success, non-zero on failure. */ static int mdbx_page_flush(MDBX_txn *txn, pgno_t keep) { MDBX_env *env = txn->mt_env; - MDBX_ID2L dl = txn->mt_rw_dirtylist; - unsigned i, j, pagecount = dl[0].mid; + MDBX_DPL dl = txn->mt_rw_dirtylist; + unsigned i, j, pagecount = dl->length; int rc; size_t size = 0, pos = 0; pgno_t pgno = 0; @@ -3900,7 +4278,7 @@ static int mdbx_page_flush(MDBX_txn *txn, pgno_t keep) { if (env->me_flags & MDBX_WRITEMAP) { /* Clear dirty flags */ while (++i <= pagecount) { - dp = dl[i].mptr; + dp = dl[i].ptr; /* Don't flush this page yet */ if (dp->mp_flags & (P_LOOSE | P_KEEP)) { dp->mp_flags &= ~P_KEEP; @@ -3918,14 +4296,15 @@ static int mdbx_page_flush(MDBX_txn *txn, pgno_t keep) { /* Write the pages */ for (;;) { if (++i <= pagecount) { - dp = dl[i].mptr; + dp = dl[i].ptr; /* Don't flush this page yet */ if (dp->mp_flags & (P_LOOSE | P_KEEP)) { dp->mp_flags &= ~P_KEEP; - dl[i].mid = 0; + dl[i].pgno = 0; continue; } - pgno = dl[i].mid; + pgno = dl[i].pgno; + assert(pgno >= MIN_PAGENO); /* clear dirty flag */ dp->mp_flags &= ~P_DIRTY; dp->mp_validator = 0 /* TODO */; @@ -3960,20 +4339,20 @@ static int mdbx_page_flush(MDBX_txn *txn, pgno_t keep) { mdbx_invalidate_cache(env->me_map, pgno2bytes(env, txn->mt_next_pgno)); for (i = keep; ++i <= pagecount;) { - dp = dl[i].mptr; + dp = dl[i].ptr; /* This is a page we skipped above */ - if (!dl[i].mid) { + if (!dl[i].pgno) { dl[++j] = dl[i]; - dl[j].mid = dp->mp_pgno; + dl[j].pgno = dp->mp_pgno; continue; } - mdbx_dpage_free(env, dp); + mdbx_dpage_free(env, dp, IS_OVERFLOW(dp) ? dp->mp_pages : 1); } done: i--; txn->mt_dirtyroom += i - j; - dl[0].mid = j; + dl->length = j; return MDBX_SUCCESS; } @@ -3997,7 +4376,7 @@ static __cold bool mdbx_txn_import_dbi(MDBX_txn *txn, MDBX_dbi dbi) { (env->me_dbflags[i] & MDBX_VALID)) { txn->mt_dbs[i].md_flags = env->me_dbflags[i] & PERSISTENT_FLAGS; txn->mt_dbflags[i] = DB_VALID | DB_USRVALID | DB_STALE; - assert(txn->mt_dbxs[i].md_cmp != NULL); + mdbx_tassert(txn, txn->mt_dbxs[i].md_cmp != NULL); } } txn->mt_numdbs = snap_numdbs; @@ -4057,7 +4436,7 @@ int mdbx_txn_commit(MDBX_txn *txn) { if (txn->mt_parent) { MDBX_txn *parent = txn->mt_parent; MDBX_page **lp; - MDBX_ID2L dst, src; + MDBX_DPL dst, src; MDBX_PNL pspill; unsigned i, x, y, len, ps_len; @@ -4103,12 +4482,12 @@ int mdbx_txn_commit(MDBX_txn *txn) { dst = parent->mt_rw_dirtylist; src = txn->mt_rw_dirtylist; /* Remove anything in our dirty list from parent's spill list */ - if ((pspill = parent->mt_spill_pages) && (ps_len = pspill[0])) { + if ((pspill = parent->mt_spill_pages) && (ps_len = MDBX_PNL_SIZE(pspill))) { x = y = ps_len; - pspill[0] = (pgno_t)-1; + MDBX_PNL_SIZE(pspill) = ~(pgno_t)0; /* Mark our dirty pages as deleted in parent spill list */ - for (i = 0, len = src[0].mid; ++i <= len;) { - pgno_t pn = src[i].mid << 1; + for (i = 0, len = src->length; ++i <= len;) { + pgno_t pn = src[i].pgno << 1; while (pn > pspill[x]) x--; if (pn == pspill[x]) { @@ -4118,59 +4497,59 @@ int mdbx_txn_commit(MDBX_txn *txn) { } /* Squash deleted pagenums if we deleted any */ for (x = y; ++x <= ps_len;) - if (!(pspill[x] & 1)) + if ((pspill[x] & 1) == 0) pspill[++y] = pspill[x]; - pspill[0] = y; + MDBX_PNL_SIZE(pspill) = y; } /* Remove anything in our spill list from parent's dirty list */ - if (txn->mt_spill_pages && txn->mt_spill_pages[0]) { - for (i = 1; i <= txn->mt_spill_pages[0]; i++) { + if (txn->mt_spill_pages && MDBX_PNL_SIZE(txn->mt_spill_pages)) { + for (i = 1; i <= MDBX_PNL_SIZE(txn->mt_spill_pages); i++) { pgno_t pn = txn->mt_spill_pages[i]; if (pn & 1) continue; /* deleted spillpg */ pn >>= 1; - y = mdbx_mid2l_search(dst, pn); - if (y <= dst[0].mid && dst[y].mid == pn) { - free(dst[y].mptr); - while (y < dst[0].mid) { + y = mdbx_dpl_search(dst, pn); + if (y <= dst->length && dst[y].pgno == pn) { + free(dst[y].ptr); + while (y < dst->length) { dst[y] = dst[y + 1]; y++; } - dst[0].mid--; + dst->length--; } } } /* Find len = length of merging our dirty list with parent's */ - x = dst[0].mid; - dst[0].mid = 0; /* simplify loops */ + x = dst->length; + dst->length = 0; /* simplify loops */ if (parent->mt_parent) { - len = x + src[0].mid; - y = mdbx_mid2l_search(src, dst[x].mid + 1) - 1; + len = x + src->length; + y = mdbx_dpl_search(src, dst[x].pgno + 1) - 1; for (i = x; y && i; y--) { - pgno_t yp = src[y].mid; - while (yp < dst[i].mid) + pgno_t yp = src[y].pgno; + while (yp < dst[i].pgno) i--; - if (yp == dst[i].mid) { + if (yp == dst[i].pgno) { i--; len--; } } } else { /* Simplify the above for single-ancestor case */ - len = MDBX_PNL_UM_MAX - txn->mt_dirtyroom; + len = MDBX_DPL_TXNFULL - txn->mt_dirtyroom; } /* Merge our dirty list with parent's */ - y = src[0].mid; + y = src->length; for (i = len; y; dst[i--] = src[y--]) { - pgno_t yp = src[y].mid; - while (yp < dst[x].mid) + pgno_t yp = src[y].pgno; + while (yp < dst[x].pgno) dst[i--] = dst[x--]; - if (yp == dst[x].mid) - free(dst[x--].mptr); + if (yp == dst[x].pgno) + free(dst[x--].ptr); } mdbx_tassert(txn, i == x); - dst[0].mid = len; + dst->length = len; free(txn->mt_rw_dirtylist); parent->mt_dirtyroom = txn->mt_dirtyroom; if (txn->mt_spill_pages) { @@ -4208,7 +4587,7 @@ int mdbx_txn_commit(MDBX_txn *txn) { mdbx_cursors_eot(txn, 0); end_mode |= MDBX_END_EOTDONE; - if (!txn->mt_rw_dirtylist[0].mid && + if (txn->mt_rw_dirtylist->length == 0 && !(txn->mt_flags & (MDBX_TXN_DIRTY | MDBX_TXN_SPILLS))) goto done; @@ -4224,7 +4603,7 @@ int mdbx_txn_commit(MDBX_txn *txn) { MDBX_val data; data.iov_len = sizeof(MDBX_db); - rc = mdbx_cursor_init(&mc, txn, MAIN_DBI, NULL); + rc = mdbx_cursor_init(&mc, txn, MAIN_DBI); if (unlikely(rc != MDBX_SUCCESS)) goto fail; for (i = CORE_DBS; i < txn->mt_numdbs; i++) { @@ -4234,14 +4613,16 @@ int mdbx_txn_commit(MDBX_txn *txn) { goto fail; } data.iov_base = &txn->mt_dbs[i]; - rc = mdbx_cursor_put(&mc, &txn->mt_dbxs[i].md_name, &data, F_SUBDATA); + WITH_CURSOR_TRACKING(mc, + rc = mdbx_cursor_put(&mc, &txn->mt_dbxs[i].md_name, + &data, F_SUBDATA)); if (unlikely(rc != MDBX_SUCCESS)) goto fail; } } } - rc = mdbx_freelist_save(txn); + rc = mdbx_update_gc(txn); if (unlikely(rc != MDBX_SUCCESS)) goto fail; @@ -4249,8 +4630,11 @@ int mdbx_txn_commit(MDBX_txn *txn) { env->me_reclaimed_pglist = NULL; mdbx_pnl_shrink(&txn->mt_befree_pages); - if (mdbx_audit_enabled()) - mdbx_audit(txn); + if (mdbx_audit_enabled()) { + rc = mdbx_audit(txn, 0); + if (unlikely(rc != MDBX_SUCCESS)) + goto fail; + } rc = mdbx_page_flush(txn, 0); if (likely(rc == MDBX_SUCCESS)) { @@ -4318,6 +4702,8 @@ static int __cold mdbx_read_header(MDBX_env *env, MDBX_meta *meta, unsigned retryleft = 42; while (1) { + mdbx_trace("reading meta[%d]: offset %u, bytes %u, retry-left %u", + meta_number, offset, (unsigned)sizeof(page), retryleft); int err = mdbx_pread(env->me_fd, &page, sizeof(page), offset); if (err != MDBX_SUCCESS) { mdbx_error("read meta[%u,%u]: %i, %s", offset, (unsigned)sizeof(page), @@ -4339,9 +4725,12 @@ static int __cold mdbx_read_header(MDBX_env *env, MDBX_meta *meta, mdbx_info("meta[%u] was updated, re-read it", meta_number); } - if (!retryleft) { - mdbx_error("meta[%u] is too volatile, skip it", meta_number); - continue; + if (page.mp_meta.mm_magic_and_version != MDBX_DATA_MAGIC && page.mp_meta.mm_magic_and_version != MDBX_DATA_DEBUG) { + mdbx_error("meta[%u] has invalid magic/version %" PRIx64, meta_number, + page.mp_meta.mm_magic_and_version); + return ((page.mp_meta.mm_magic_and_version >> 8) != MDBX_MAGIC) + ? MDBX_INVALID + : MDBX_VERSION_MISMATCH; } if (page.mp_pgno != meta_number) { @@ -4350,17 +4739,31 @@ static int __cold mdbx_read_header(MDBX_env *env, MDBX_meta *meta, return MDBX_INVALID; } - if (!F_ISSET(page.mp_flags, P_META)) { + if (page.mp_flags != P_META) { mdbx_error("page #%u not a meta-page", meta_number); return MDBX_INVALID; } - if (page.mp_meta.mm_magic_and_version != MDBX_DATA_MAGIC && page.mp_meta.mm_magic_and_version != MDBX_DATA_DEBUG) { - mdbx_error("meta[%u] has invalid magic/version %" PRIx64, meta_number, - page.mp_meta.mm_magic_and_version); - return ((page.mp_meta.mm_magic_and_version >> 8) != MDBX_MAGIC) - ? MDBX_INVALID - : MDBX_VERSION_MISMATCH; + if (!retryleft) { + mdbx_error("meta[%u] is too volatile, skip it", meta_number); + continue; + } + + /* LY: check pagesize */ + if (!mdbx_is_power2(page.mp_meta.mm_psize) || + page.mp_meta.mm_psize < MIN_PAGESIZE || + page.mp_meta.mm_psize > MAX_PAGESIZE) { + mdbx_notice("meta[%u] has invalid pagesize (%u), skip it", meta_number, + page.mp_meta.mm_psize); + rc = mdbx_is_power2(page.mp_meta.mm_psize) ? MDBX_VERSION_MISMATCH + : MDBX_INVALID; + continue; + } + + if (meta_number == 0 && guess_pagesize != page.mp_meta.mm_psize) { + meta->mm_psize = page.mp_meta.mm_psize; + mdbx_info("meta[%u] took pagesize %u", meta_number, + page.mp_meta.mm_psize); } if (page.mp_meta.mm_txnid_a != page.mp_meta.mm_txnid_b) { @@ -4378,16 +4781,6 @@ static int __cold mdbx_read_header(MDBX_env *env, MDBX_meta *meta, continue; } - /* LY: check pagesize */ - if (!mdbx_is_power2(page.mp_meta.mm_psize) || - page.mp_meta.mm_psize < MIN_PAGESIZE || - page.mp_meta.mm_psize > MAX_PAGESIZE) { - mdbx_notice("meta[%u] has invalid pagesize (%u), skip it", meta_number, - page.mp_meta.mm_psize); - rc = MDBX_VERSION_MISMATCH; - continue; - } - mdbx_debug("read meta%" PRIaPGNO " = root %" PRIaPGNO "/%" PRIaPGNO ", geo %" PRIaPGNO "/%" PRIaPGNO "-%" PRIaPGNO "/%" PRIaPGNO " +%u -%u, txn_id %" PRIaTXN ", %s", @@ -4439,11 +4832,16 @@ static int __cold mdbx_read_header(MDBX_env *env, MDBX_meta *meta, const uint64_t used_bytes = page.mp_meta.mm_geo.next * (uint64_t)page.mp_meta.mm_psize; if (used_bytes > *filesize) { - mdbx_notice("meta[%u] used-bytes (%" PRIu64 ") beyond filesize (%" PRIu64 - "), skip it", - meta_number, used_bytes, *filesize); - rc = MDBX_CORRUPTED; - continue; + rc = mdbx_filesize(env->me_fd, filesize); + if (unlikely(rc != MDBX_SUCCESS)) + return rc; + if (used_bytes > *filesize) { + mdbx_notice("meta[%u] used-bytes (%" PRIu64 + ") beyond filesize (%" PRIu64 "), skip it", + meta_number, used_bytes, *filesize); + rc = MDBX_CORRUPTED; + continue; + } } /* LY: check mapsize limits */ @@ -4750,9 +5148,11 @@ static int mdbx_sync_locked(MDBX_env *env, unsigned flags, target->mm_datasync_sign = MDBX_DATASIGN_WEAK; mdbx_meta_update_begin(env, target, pending->mm_txnid_a); #ifndef NDEBUG - /* debug: provoke failure to catch a violators */ - memset(target->mm_dbs, 0xCC, - sizeof(target->mm_dbs) + sizeof(target->mm_canary)); + /* debug: provoke failure to catch a violators, but don't touch mm_psize + * and mm_flags to allow readers catch actual pagesize. */ + uint8_t *provoke_begin = (uint8_t *)&target->mm_dbs[FREE_DBI].md_root; + uint8_t *provoke_end = (uint8_t *)&target->mm_datasync_sign; + memset(provoke_begin, 0xCC, provoke_end - provoke_begin); mdbx_jitter4testing(false); #endif @@ -4843,23 +5243,12 @@ int __cold mdbx_env_get_maxkeysize(MDBX_env *env) { } #define mdbx_nodemax(pagesize) \ - (((((pagesize)-PAGEHDRSZ) / MDBX_MINKEYS) & -(intptr_t)2) - sizeof(indx_t)) - -#define mdbx_maxkey(nodemax) ((nodemax) - (NODESIZE + sizeof(MDBX_db))) + (((((pagesize)-PAGEHDRSZ) / MDBX_MINKEYS) & ~(uintptr_t)1) - sizeof(indx_t)) -#define mdbx_maxfree1pg(pagesize) (((pagesize)-PAGEHDRSZ) / sizeof(pgno_t) - 1) +#define mdbx_maxkey(nodemax) (((nodemax)-NODESIZE - sizeof(MDBX_db)) / 2) -int mdbx_get_maxkeysize(size_t pagesize) { - if (pagesize == 0) - pagesize = mdbx_syspagesize(); - - intptr_t nodemax = mdbx_nodemax(pagesize); - if (nodemax < 0) - return -MDBX_EINVAL; - - intptr_t maxkey = mdbx_maxkey(nodemax); - return (maxkey > 0 && maxkey < INT_MAX) ? (int)maxkey : -MDBX_EINVAL; -} +#define mdbx_maxgc_ov1page(pagesize) \ + (((pagesize)-PAGEHDRSZ) / sizeof(pgno_t) - 1) static void __cold mdbx_setup_pagesize(MDBX_env *env, const size_t pagesize) { STATIC_ASSERT(SSIZE_MAX > MAX_MAPSIZE); @@ -4869,16 +5258,17 @@ static void __cold mdbx_setup_pagesize(MDBX_env *env, const size_t pagesize) { mdbx_ensure(env, pagesize <= MAX_PAGESIZE); env->me_psize = (unsigned)pagesize; - STATIC_ASSERT(mdbx_maxfree1pg(MIN_PAGESIZE) > 42); - STATIC_ASSERT(mdbx_maxfree1pg(MAX_PAGESIZE) < MDBX_PNL_DB_MAX); - const intptr_t maxfree_1pg = (pagesize - PAGEHDRSZ) / sizeof(pgno_t) - 1; - mdbx_ensure(env, maxfree_1pg > 42 && maxfree_1pg < MDBX_PNL_DB_MAX); - env->me_maxfree_1pg = (unsigned)maxfree_1pg; + STATIC_ASSERT(mdbx_maxgc_ov1page(MIN_PAGESIZE) > 42); + STATIC_ASSERT(mdbx_maxgc_ov1page(MAX_PAGESIZE) < MDBX_DPL_TXNFULL); + const intptr_t maxgc_ov1page = (pagesize - PAGEHDRSZ) / sizeof(pgno_t) - 1; + mdbx_ensure(env, + maxgc_ov1page > 42 && maxgc_ov1page < (intptr_t)MDBX_DPL_TXNFULL); + env->me_maxgc_ov1page = (unsigned)maxgc_ov1page; STATIC_ASSERT(mdbx_nodemax(MIN_PAGESIZE) > 42); STATIC_ASSERT(mdbx_nodemax(MAX_PAGESIZE) < UINT16_MAX); const intptr_t nodemax = mdbx_nodemax(pagesize); - mdbx_ensure(env, nodemax > 42 && nodemax < UINT16_MAX); + mdbx_ensure(env, nodemax > 42 && nodemax < UINT16_MAX && nodemax % 2 == 0); env->me_nodemax = (unsigned)nodemax; STATIC_ASSERT(mdbx_maxkey(MIN_PAGESIZE) > 42); @@ -4886,7 +5276,8 @@ static void __cold mdbx_setup_pagesize(MDBX_env *env, const size_t pagesize) { STATIC_ASSERT(mdbx_maxkey(MAX_PAGESIZE) > 42); STATIC_ASSERT(mdbx_maxkey(MAX_PAGESIZE) < MAX_PAGESIZE); const intptr_t maxkey_limit = mdbx_maxkey(env->me_nodemax); - mdbx_ensure(env, maxkey_limit > 42 && (size_t)maxkey_limit < pagesize); + mdbx_ensure(env, maxkey_limit > 42 && (size_t)maxkey_limit < pagesize && + maxkey_limit % 2 == 0); env->me_maxkey_limit = (unsigned)maxkey_limit; env->me_psize2log = mdbx_log2(pagesize); @@ -5349,7 +5740,7 @@ static int __cold mdbx_setup_dxb(MDBX_env *env, int lck_rc) { /* apply preconfigured params, but only if substantial changes: * - upper or lower limit changes - * - shrink theshold or growth step + * - shrink threshold or growth step * But ignore just chagne just a 'now/current' size. */ if (bytes_align2os_bytes(env, env->me_dbgeo.upper) != pgno_align2os_bytes(env, meta.mm_geo.upper) || @@ -5785,8 +6176,8 @@ int __cold mdbx_env_open(MDBX_env *env, const char *path, unsigned flags, flags &= ~(MDBX_WRITEMAP | MDBX_MAPASYNC | MDBX_NOSYNC | MDBX_NOMETASYNC | MDBX_COALESCE | MDBX_LIFORECLAIM | MDBX_NOMEMINIT); } else { - if (!((env->me_free_pgs = mdbx_pnl_alloc(MDBX_PNL_UM_MAX)) && - (env->me_dirtylist = calloc(MDBX_PNL_UM_SIZE, sizeof(MDBX_ID2))))) + if (!((env->me_free_pgs = mdbx_pnl_alloc(MDBX_PNL_INITIAL)) && + (env->me_dirtylist = calloc(MDBX_DPL_TXNFULL + 1, sizeof(MDBX_DP))))) rc = MDBX_ENOMEM; } @@ -5945,6 +6336,8 @@ static void __cold mdbx_env_close0(MDBX_env *env) { if (env->me_flags & MDBX_ENV_TXKEY) mdbx_rthc_remove(env->me_txkey); + if (env->me_live_reader) + (void)mdbx_rpid_clear(env); if (env->me_map) { mdbx_munmap(&env->me_dxb_mmap); @@ -6173,7 +6566,6 @@ static int __hot mdbx_cmp_memnr(const MDBX_val *a, const MDBX_val *b) { * If no entry larger or equal to the key is found, returns NULL. */ static MDBX_node *__hot mdbx_node_search(MDBX_cursor *mc, MDBX_val *key, int *exactp) { - unsigned i = 0, nkeys; int low, high; int rc = 0; MDBX_page *mp = mc->mc_pg[mc->mc_top]; @@ -6182,7 +6574,7 @@ static MDBX_node *__hot mdbx_node_search(MDBX_cursor *mc, MDBX_val *key, MDBX_cmp_func *cmp; DKBUF; - nkeys = NUMKEYS(mp); + const unsigned nkeys = NUMKEYS(mp); mdbx_debug("searching %u keys in %s %spage %" PRIaPGNO "", nkeys, IS_LEAF(mp) ? "leaf" : "branch", IS_SUBP(mp) ? "sub-" : "", @@ -6198,6 +6590,7 @@ static MDBX_node *__hot mdbx_node_search(MDBX_cursor *mc, MDBX_val *key, if (cmp == mdbx_cmp_int_a2 && IS_BRANCH(mp)) cmp = mdbx_cmp_int_ai; + unsigned i = 0; if (IS_LEAF2(mp)) { nodekey.iov_len = mc->mc_db->md_xsize; node = NODEPTR(mp, 0); /* fake */ @@ -6320,22 +6713,22 @@ static int mdbx_page_get(MDBX_cursor *mc, pgno_t pgno, MDBX_page **ret, MDBX_txn *tx2 = txn; level = 1; do { - MDBX_ID2L dl = tx2->mt_rw_dirtylist; - unsigned x; + MDBX_DPL dl = tx2->mt_rw_dirtylist; /* Spilled pages were dirtied in this txn and flushed * because the dirty list got full. Bring this page * back in from the map (but don't unspill it here, * leave that unless page_touch happens again). */ if (tx2->mt_spill_pages) { pgno_t pn = pgno << 1; - x = mdbx_pnl_search(tx2->mt_spill_pages, pn); - if (x <= tx2->mt_spill_pages[0] && tx2->mt_spill_pages[x] == pn) + unsigned x = mdbx_pnl_search(tx2->mt_spill_pages, pn); + if (x <= MDBX_PNL_SIZE(tx2->mt_spill_pages) && + tx2->mt_spill_pages[x] == pn) goto mapped; } - if (dl[0].mid) { - unsigned y = mdbx_mid2l_search(dl, pgno); - if (y <= dl[0].mid && dl[y].mid == pgno) { - p = dl[y].mptr; + if (dl->length) { + unsigned y = mdbx_dpl_search(dl, pgno); + if (y <= dl->length && dl[y].pgno == pgno) { + p = dl[y].ptr; goto done; } } @@ -6352,9 +6745,17 @@ static int mdbx_page_get(MDBX_cursor *mc, pgno_t pgno, MDBX_page **ret, mapped: p = pgno2page(env, pgno); - /* TODO: check p->mp_validator here */ done: + if (unlikely(p->mp_pgno != pgno)) + return MDBX_CORRUPTED; + + if (unlikely(p->mp_upper < p->mp_lower || + PAGEHDRSZ + p->mp_upper > env->me_psize) && + !IS_OVERFLOW(p)) + return MDBX_CORRUPTED; + /* TODO: more checks here, including p->mp_validator */ + *ret = p; if (lvl) *lvl = level; @@ -6448,6 +6849,7 @@ static int mdbx_page_search_root(MDBX_cursor *mc, MDBX_val *key, int flags) { * be underfilled. */ static int mdbx_page_search_lowest(MDBX_cursor *mc) { MDBX_page *mp = mc->mc_pg[mc->mc_top]; + mdbx_cassert(mc, IS_BRANCH(mp)); MDBX_node *node = NODEPTR(mp, 0); int rc; @@ -6485,13 +6887,13 @@ static int mdbx_page_search(MDBX_cursor *mc, MDBX_val *key, int flags) { return MDBX_BAD_TXN; } - mdbx_cassert(mc, mc->mc_txn->mt_txnid >= mc->mc_txn->mt_env->me_oldest[0]); + mdbx_cassert(mc, mc->mc_txn->mt_txnid >= *mc->mc_txn->mt_env->me_oldest); /* Make sure we're using an up-to-date root */ if (unlikely(*mc->mc_dbflag & DB_STALE)) { MDBX_cursor mc2; if (unlikely(TXN_DBI_CHANGED(mc->mc_txn, mc->mc_dbi))) return MDBX_BAD_DBI; - rc = mdbx_cursor_init(&mc2, mc->mc_txn, MAIN_DBI, NULL); + rc = mdbx_cursor_init(&mc2, mc->mc_txn, MAIN_DBI); if (unlikely(rc != MDBX_SUCCESS)) return rc; rc = mdbx_page_search(&mc2, &mc->mc_dbx->md_name, 0); @@ -6527,7 +6929,7 @@ static int mdbx_page_search(MDBX_cursor *mc, MDBX_val *key, int flags) { return MDBX_NOTFOUND; } - mdbx_cassert(mc, mc->mc_txn->mt_txnid >= mc->mc_txn->mt_env->me_oldest[0]); + mdbx_cassert(mc, mc->mc_txn->mt_txnid >= *mc->mc_txn->mt_env->me_oldest); mdbx_cassert(mc, root >= NUM_METAS); if (!mc->mc_pg[0] || mc->mc_pg[0]->mp_pgno != root) if (unlikely((rc = mdbx_page_get(mc, root, &mc->mc_pg[0], NULL)) != 0)) @@ -6559,7 +6961,28 @@ static int mdbx_ovpage_free(MDBX_cursor *mc, MDBX_page *mp) { pgno_t pn = pg << 1; int rc; + mdbx_cassert(mc, (mc->mc_flags & C_GCFREEZE) == 0); + mdbx_cassert(mc, IS_OVERFLOW(mp)); mdbx_debug("free ov page %" PRIaPGNO " (%u)", pg, ovpages); + + if (mdbx_audit_enabled() && env->me_reclaimed_pglist) { + mdbx_cassert(mc, mdbx_pnl_check(env->me_reclaimed_pglist, true)); + const unsigned a = mdbx_pnl_search(env->me_reclaimed_pglist, pg); + mdbx_cassert(mc, a > MDBX_PNL_SIZE(env->me_reclaimed_pglist) || + env->me_reclaimed_pglist[a] != pg); + if (a <= MDBX_PNL_SIZE(env->me_reclaimed_pglist) && + env->me_reclaimed_pglist[a] == pg) + return MDBX_PROBLEM; + + if (ovpages > 1) { + const unsigned b = + mdbx_pnl_search(env->me_reclaimed_pglist, pg + ovpages - 1); + mdbx_cassert(mc, a == b); + if (a != b) + return MDBX_PROBLEM; + } + } + /* If the page is dirty or on the spill list we just acquired it, * so we should give it back to our current free list, if any. * Otherwise put it onto the list of pages we freed in this txn. @@ -6569,26 +6992,28 @@ static int mdbx_ovpage_free(MDBX_cursor *mc, MDBX_page *mp) { * Unsupported in nested txns: They would need to hide the page * range in ancestor txns' dirty and spilled lists. */ if (env->me_reclaimed_pglist && !txn->mt_parent && - ((mp->mp_flags & P_DIRTY) || - (sl && (x = mdbx_pnl_search(sl, pn)) <= sl[0] && sl[x] == pn))) { + (IS_DIRTY(mp) || + (sl && (x = mdbx_pnl_search(sl, pn)) <= MDBX_PNL_SIZE(sl) && + sl[x] == pn))) { unsigned i, j; pgno_t *mop; - MDBX_ID2 *dl, ix, iy; + MDBX_DP *dl, ix, iy; rc = mdbx_pnl_need(&env->me_reclaimed_pglist, ovpages); if (unlikely(rc)) return rc; - if (!(mp->mp_flags & P_DIRTY)) { + + if (!IS_DIRTY(mp)) { /* This page is no longer spilled */ - if (x == sl[0]) - sl[0]--; + if (x == MDBX_PNL_SIZE(sl)) + MDBX_PNL_SIZE(sl)--; else sl[x] |= 1; goto release; } /* Remove from dirty list */ dl = txn->mt_rw_dirtylist; - x = dl[0].mid--; - for (ix = dl[x]; ix.mptr != mp; ix = iy) { + x = dl->length--; + for (ix = dl[x]; ix.ptr != mp; ix = iy) { if (likely(x > 1)) { x--; iy = dl[x]; @@ -6597,7 +7022,7 @@ static int mdbx_ovpage_free(MDBX_cursor *mc, MDBX_page *mp) { mdbx_cassert(mc, x > 1); mdbx_error("not found page 0x%p #%" PRIaPGNO " in the dirtylist", mp, mp->mp_pgno); - j = ++(dl[0].mid); + j = dl->length += 1; dl[j] = ix; /* Unsorted. OK when MDBX_TXN_ERROR. */ txn->mt_flags |= MDBX_TXN_ERROR; return MDBX_PROBLEM; @@ -6605,22 +7030,30 @@ static int mdbx_ovpage_free(MDBX_cursor *mc, MDBX_page *mp) { } txn->mt_dirtyroom++; if (!(env->me_flags & MDBX_WRITEMAP)) - mdbx_dpage_free(env, mp); + mdbx_dpage_free(env, mp, IS_OVERFLOW(mp) ? mp->mp_pages : 1); release: /* Insert in me_reclaimed_pglist */ mop = env->me_reclaimed_pglist; - j = mop[0] + ovpages; - for (i = mop[0]; i && mop[i] < pg; i--) - mop[j--] = mop[i]; + j = MDBX_PNL_SIZE(mop) + ovpages; + for (i = MDBX_PNL_SIZE(mop); i && MDBX_PNL_DISORDERED(mop[i], pg);) + mop[j--] = mop[i--]; + MDBX_PNL_SIZE(mop) += ovpages; + + pgno_t n = MDBX_PNL_ASCENDING ? pg + ovpages : pg; while (j > i) - mop[j--] = pg++; - mop[0] += ovpages; + mop[j--] = MDBX_PNL_ASCENDING ? --n : n++; + mdbx_tassert(txn, mdbx_pnl_check(env->me_reclaimed_pglist, true)); } else { rc = mdbx_pnl_append_range(&txn->mt_befree_pages, pg, ovpages); if (unlikely(rc)) return rc; } + mc->mc_db->md_overflow_pages -= ovpages; + if (unlikely(mc->mc_flags & C_SUB)) { + MDBX_db *outer = mdbx_outer_db(mc); + outer->md_overflow_pages -= ovpages; + } return 0; } @@ -6637,7 +7070,7 @@ static __inline int mdbx_node_read(MDBX_cursor *mc, MDBX_node *leaf, pgno_t pgno; int rc; - mdbx_cassert(mc, mc->mc_txn->mt_txnid >= mc->mc_txn->mt_env->me_oldest[0]); + mdbx_cassert(mc, mc->mc_txn->mt_txnid >= *mc->mc_txn->mt_env->me_oldest); if (!F_ISSET(leaf->mn_flags, F_BIGDATA)) { data->iov_len = NODEDSZ(leaf); data->iov_base = NODEDATA(leaf); @@ -6657,8 +7090,6 @@ static __inline int mdbx_node_read(MDBX_cursor *mc, MDBX_node *leaf, } int mdbx_get(MDBX_txn *txn, MDBX_dbi dbi, MDBX_val *key, MDBX_val *data) { - MDBX_cursor mc; - MDBX_xcursor mx; int exact = 0; DKBUF; @@ -6679,10 +7110,11 @@ int mdbx_get(MDBX_txn *txn, MDBX_dbi dbi, MDBX_val *key, MDBX_val *data) { if (unlikely(txn->mt_flags & MDBX_TXN_BLOCKED)) return MDBX_BAD_TXN; - int rc = mdbx_cursor_init(&mc, txn, dbi, &mx); + MDBX_cursor_couple cx; + int rc = mdbx_cursor_init(&cx.outer, txn, dbi); if (unlikely(rc != MDBX_SUCCESS)) return rc; - return mdbx_cursor_set(&mc, key, data, MDBX_SET, &exact); + return mdbx_cursor_set(&cx.outer, key, data, MDBX_SET, &exact); } /* Find a sibling for a page. @@ -6699,7 +7131,7 @@ static int mdbx_cursor_sibling(MDBX_cursor *mc, int move_right) { MDBX_node *indx; MDBX_page *mp; - mdbx_cassert(mc, mc->mc_txn->mt_txnid >= mc->mc_txn->mt_env->me_oldest[0]); + mdbx_cassert(mc, mc->mc_txn->mt_txnid >= *mc->mc_txn->mt_env->me_oldest); if (unlikely(mc->mc_snum < 2)) { return MDBX_NOTFOUND; /* root has no siblings */ } @@ -6935,7 +7367,7 @@ static int mdbx_cursor_set(MDBX_cursor *mc, MDBX_val *key, MDBX_val *data, MDBX_node *leaf = NULL; DKBUF; - mdbx_cassert(mc, mc->mc_txn->mt_txnid >= mc->mc_txn->mt_env->me_oldest[0]); + mdbx_cassert(mc, mc->mc_txn->mt_txnid >= *mc->mc_txn->mt_env->me_oldest); if ((mc->mc_db->md_flags & MDBX_INTEGERKEY) && unlikely(key->iov_len != sizeof(uint32_t) && key->iov_len != sizeof(uint64_t))) { @@ -6950,12 +7382,13 @@ static int mdbx_cursor_set(MDBX_cursor *mc, MDBX_val *key, MDBX_val *data, if (mc->mc_flags & C_INITIALIZED) { MDBX_val nodekey; + mdbx_cassert(mc, IS_LEAF(mc->mc_pg[mc->mc_top])); mp = mc->mc_pg[mc->mc_top]; if (!NUMKEYS(mp)) { mc->mc_ki[mc->mc_top] = 0; return MDBX_NOTFOUND; } - if (mp->mp_flags & P_LEAF2) { + if (IS_LEAF2(mp)) { nodekey.iov_len = mc->mc_db->md_xsize; nodekey.iov_base = LEAF2KEY(mp, 0, nodekey.iov_len); } else { @@ -6963,20 +7396,19 @@ static int mdbx_cursor_set(MDBX_cursor *mc, MDBX_val *key, MDBX_val *data, MDBX_GET_KEY2(leaf, nodekey); } rc = mc->mc_dbx->md_cmp(key, &nodekey); - if (rc == 0) { + if (unlikely(rc == 0)) { /* Probably happens rarely, but first node on the page - * was the one we wanted. - */ + * was the one we wanted. */ mc->mc_ki[mc->mc_top] = 0; if (exactp) *exactp = 1; goto set1; } if (rc > 0) { + const unsigned nkeys = NUMKEYS(mp); unsigned i; - unsigned nkeys = NUMKEYS(mp); if (nkeys > 1) { - if (mp->mp_flags & P_LEAF2) { + if (IS_LEAF2(mp)) { nodekey.iov_base = LEAF2KEY(mp, nkeys - 1, nodekey.iov_len); } else { leaf = NODEPTR(mp, nkeys - 1); @@ -6994,7 +7426,7 @@ static int mdbx_cursor_set(MDBX_cursor *mc, MDBX_val *key, MDBX_val *data, if (rc < 0) { if (mc->mc_ki[mc->mc_top] < NUMKEYS(mp)) { /* This is definitely the right page, skip search_page */ - if (mp->mp_flags & P_LEAF2) { + if (IS_LEAF2(mp)) { nodekey.iov_base = LEAF2KEY(mp, mc->mc_ki[mc->mc_top], nodekey.iov_len); } else { @@ -7102,9 +7534,11 @@ set1: MDBX_val olddata; if (unlikely((rc = mdbx_node_read(mc, leaf, &olddata)) != MDBX_SUCCESS)) return rc; + if (unlikely(mc->mc_dbx->md_dcmp == NULL)) + return MDBX_EINVAL; rc = mc->mc_dbx->md_dcmp(data, &olddata); if (rc) { - if (op == MDBX_GET_BOTH || rc > 0) + if (op != MDBX_GET_BOTH_RANGE || rc > 0) return MDBX_NOTFOUND; rc = 0; } @@ -7230,13 +7664,13 @@ int mdbx_cursor_get(MDBX_cursor *mc, MDBX_val *key, MDBX_val *data, if (unlikely(mc->mc_txn->mt_flags & MDBX_TXN_BLOCKED)) return MDBX_BAD_TXN; - mdbx_cassert(mc, mc->mc_txn->mt_txnid >= mc->mc_txn->mt_env->me_oldest[0]); + mdbx_cassert(mc, mc->mc_txn->mt_txnid >= *mc->mc_txn->mt_env->me_oldest); switch (op) { case MDBX_GET_CURRENT: { if (unlikely(!(mc->mc_flags & C_INITIALIZED))) return MDBX_EINVAL; MDBX_page *mp = mc->mc_pg[mc->mc_top]; - unsigned nkeys = NUMKEYS(mp); + const unsigned nkeys = NUMKEYS(mp); if (mc->mc_ki[mc->mc_top] >= nkeys) { mdbx_cassert(mc, nkeys <= UINT16_MAX); mc->mc_ki[mc->mc_top] = (uint16_t)nkeys; @@ -7280,6 +7714,9 @@ int mdbx_cursor_get(MDBX_cursor *mc, MDBX_val *key, MDBX_val *data, return MDBX_INCOMPATIBLE; /* FALLTHRU */ case MDBX_SET: + if (op == MDBX_SET && unlikely(data != NULL)) + return MDBX_EINVAL; + /* FALLTHRU */ case MDBX_SET_KEY: case MDBX_SET_RANGE: if (unlikely(key == NULL)) @@ -7394,15 +7831,15 @@ static int mdbx_cursor_touch(MDBX_cursor *mc) { if (mc->mc_dbi >= CORE_DBS && (*mc->mc_dbflag & (DB_DIRTY | DB_DUPDATA)) == 0) { + mdbx_cassert(mc, (mc->mc_flags & C_RECLAIMING) == 0); /* Touch DB record of named DB */ - MDBX_cursor mc2; - MDBX_xcursor mcx; + MDBX_cursor_couple cx; if (TXN_DBI_CHANGED(mc->mc_txn, mc->mc_dbi)) return MDBX_BAD_DBI; - rc = mdbx_cursor_init(&mc2, mc->mc_txn, MAIN_DBI, &mcx); + rc = mdbx_cursor_init(&cx.outer, mc->mc_txn, MAIN_DBI); if (unlikely(rc != MDBX_SUCCESS)) return rc; - rc = mdbx_page_search(&mc2, &mc->mc_dbx->md_name, MDBX_PS_MODIFY); + rc = mdbx_page_search(&cx.outer, &mc->mc_dbx->md_name, MDBX_PS_MODIFY); if (unlikely(rc)) return rc; *mc->mc_dbflag |= DB_DIRTY; @@ -7417,9 +7854,6 @@ static int mdbx_cursor_touch(MDBX_cursor *mc) { return rc; } -/* Do not spill pages to disk if txn is getting full, may fail instead */ -#define MDBX_NOSPILL 0x8000 - int mdbx_cursor_put(MDBX_cursor *mc, MDBX_val *key, MDBX_val *data, unsigned flags) { MDBX_env *env; @@ -7492,7 +7926,7 @@ int mdbx_cursor_put(MDBX_cursor *mc, MDBX_val *key, MDBX_val *data, DVAL((flags & MDBX_RESERVE) ? nullptr : data), data->iov_len); int dupdata_flag = 0; - if (flags & MDBX_CURRENT) { + if ((flags & MDBX_CURRENT) != 0 && (mc->mc_flags & C_SUB) == 0) { /* Опция MDBX_CURRENT означает, что запрошено обновление текущей записи, * на которой сейчас стоит курсор. Проверяем что переданный ключ совпадает * со значением в текущей позиции курсора. @@ -7581,7 +8015,6 @@ int mdbx_cursor_put(MDBX_cursor *mc, MDBX_val *key, MDBX_val *data, if (unlikely(rc2 = mdbx_page_new(mc, P_LEAF, 1, &np))) { return rc2; } - assert(np->mp_flags & P_LEAF); rc2 = mdbx_cursor_push(mc, np); if (unlikely(rc2 != MDBX_SUCCESS)) return rc2; @@ -7643,6 +8076,12 @@ int mdbx_cursor_put(MDBX_cursor *mc, MDBX_val *key, MDBX_val *data, if (rc2) return rc2; } + + if (mdbx_audit_enabled()) { + int err = mdbx_cursor_check(mc, false); + if (unlikely(err != MDBX_SUCCESS)) + return err; + } return MDBX_SUCCESS; } @@ -7713,7 +8152,7 @@ int mdbx_cursor_put(MDBX_cursor *mc, MDBX_val *key, MDBX_val *data, offset *= 4; /* space for 4 more */ break; } - /* FALLTHRU: Big enough MDBX_DUPFIXaED sub-page */ + /* FALLTHRU: Big enough MDBX_DUPFIXED sub-page */ __fallthrough; case MDBX_CURRENT | MDBX_NODUPDATA: case MDBX_CURRENT: @@ -7749,6 +8188,7 @@ int mdbx_cursor_put(MDBX_cursor *mc, MDBX_val *key, MDBX_val *data, xdata.iov_base = &dummy; if ((rc = mdbx_page_alloc(mc, 1, &mp, MDBX_ALLOC_ALL))) return rc; + mc->mc_db->md_leaf_pages += 1; mdbx_cassert(mc, env->me_psize > olddata.iov_len); offset = env->me_psize - (unsigned)olddata.iov_len; flags |= F_DUPDATA | F_SUBDATA; @@ -7762,7 +8202,7 @@ int mdbx_cursor_put(MDBX_cursor *mc, MDBX_val *key, MDBX_val *data, mp->mp_lower = fp->mp_lower; mdbx_cassert(mc, fp->mp_upper + offset <= UINT16_MAX); mp->mp_upper = (indx_t)(fp->mp_upper + offset); - if (fp_flags & P_LEAF2) { + if (unlikely(fp_flags & P_LEAF2)) { memcpy(PAGEDATA(mp), PAGEDATA(fp), NUMKEYS(fp) * fp->mp_leaf2_ksize); } else { memcpy((char *)mp + mp->mp_upper + PAGEHDRSZ, @@ -7792,7 +8232,10 @@ int mdbx_cursor_put(MDBX_cursor *mc, MDBX_val *key, MDBX_val *data, if (F_ISSET(leaf->mn_flags, F_BIGDATA)) { MDBX_page *omp; pgno_t pg; - int level, ovpages, dpages = OVPAGES(env, data->iov_len); + int level, ovpages, + dpages = (LEAFSIZE(key, data) > env->me_nodemax) + ? OVPAGES(env, data->iov_len) + : 0; memcpy(&pg, olddata.iov_base, sizeof(pg)); if (unlikely((rc2 = mdbx_page_get(mc, pg, &omp, &level)) != 0)) @@ -7800,30 +8243,34 @@ int mdbx_cursor_put(MDBX_cursor *mc, MDBX_val *key, MDBX_val *data, ovpages = omp->mp_pages; /* Is the ov page large enough? */ - if (ovpages >= dpages) { - if (!(omp->mp_flags & P_DIRTY) && - (level || (env->me_flags & MDBX_WRITEMAP))) { + if (unlikely(mc->mc_flags & C_GCFREEZE) + ? ovpages >= dpages + : ovpages == + /* LY: add configurable threshold to keep reserve space */ + dpages) { + if (!IS_DIRTY(omp) && (level || (env->me_flags & MDBX_WRITEMAP))) { rc = mdbx_page_unspill(mc->mc_txn, omp, &omp); if (unlikely(rc)) return rc; level = 0; /* dirty in this txn or clean */ } /* Is it dirty? */ - if (omp->mp_flags & P_DIRTY) { + if (IS_DIRTY(omp)) { /* yes, overwrite it. Note in this case we don't * bother to try shrinking the page if the new data * is smaller than the overflow threshold. */ if (unlikely(level > 1)) { /* It is writable only in a parent txn */ MDBX_page *np = mdbx_page_malloc(mc->mc_txn, ovpages); - MDBX_ID2 id2; if (unlikely(!np)) return MDBX_ENOMEM; - id2.mid = pg; - id2.mptr = np; /* Note - this page is already counted in parent's dirtyroom */ - rc2 = mdbx_mid2l_insert(mc->mc_txn->mt_rw_dirtylist, &id2); - mdbx_cassert(mc, rc2 == 0); + rc2 = mdbx_dpl_insert(mc->mc_txn->mt_rw_dirtylist, pg, np); + if (unlikely(rc2 != MDBX_SUCCESS)) { + rc = rc2; + mdbx_dpage_free(env, np, ovpages); + goto fail; + } /* Currently we make the page look as with put() in the * parent txn, in case the user peeks at MDBX_RESERVEd @@ -7844,6 +8291,12 @@ int mdbx_cursor_put(MDBX_cursor *mc, MDBX_val *key, MDBX_val *data, data->iov_base = PAGEDATA(omp); else memcpy(PAGEDATA(omp), data->iov_base, data->iov_len); + + if (mdbx_audit_enabled()) { + int err = mdbx_cursor_check(mc, false); + if (unlikely(err != MDBX_SUCCESS)) + return err; + } return MDBX_SUCCESS; } } @@ -7860,19 +8313,22 @@ int mdbx_cursor_put(MDBX_cursor *mc, MDBX_val *key, MDBX_val *data, memcpy(olddata.iov_base, data->iov_base, data->iov_len); else { mdbx_cassert(mc, NUMKEYS(mc->mc_pg[mc->mc_top]) == 1); - mdbx_cassert(mc, mc->mc_pg[mc->mc_top]->mp_upper == - mc->mc_pg[mc->mc_top]->mp_lower); - mdbx_cassert(mc, IS_LEAF(mc->mc_pg[mc->mc_top]) && - !IS_LEAF2(mc->mc_pg[mc->mc_top])); + mdbx_cassert(mc, PAGETYPE(mc->mc_pg[mc->mc_top]) == P_LEAF); mdbx_cassert(mc, NODEDSZ(leaf) == 0); mdbx_cassert(mc, leaf->mn_flags == 0); mdbx_cassert(mc, key->iov_len < UINT16_MAX); leaf->mn_ksize = (uint16_t)key->iov_len; memcpy(NODEKEY(leaf), key->iov_base, key->iov_len); - assert((char *)NODEDATA(leaf) + NODEDSZ(leaf) < + assert((char *)NODEKEY(leaf) + NODEDSZ(leaf) < (char *)(mc->mc_pg[mc->mc_top]) + env->me_psize); goto fix_parent; } + + if (mdbx_audit_enabled()) { + int err = mdbx_cursor_check(mc, false); + if (unlikely(err != MDBX_SUCCESS)) + return err; + } return MDBX_SUCCESS; } mdbx_node_del(mc, 0); @@ -7890,9 +8346,15 @@ new_sub: if (!insert_key) nflags |= MDBX_SPLIT_REPLACE; rc = mdbx_page_split(mc, key, rdata, P_INVALID, nflags); + if (rc == MDBX_SUCCESS && mdbx_audit_enabled()) + rc = mdbx_cursor_check(mc, false); } else { /* There is room already in this leaf page. */ - rc = mdbx_node_add(mc, mc->mc_ki[mc->mc_top], key, rdata, 0, nflags); + if (IS_LEAF2(mc->mc_pg[mc->mc_top])) { + mdbx_cassert(mc, nflags == 0 && rdata->iov_len == 0); + rc = mdbx_node_add_leaf2(mc, mc->mc_ki[mc->mc_top], key); + } else + rc = mdbx_node_add_leaf(mc, mc->mc_ki[mc->mc_top], key, rdata, nflags); if (likely(rc == 0)) { /* Adjust other cursors pointing to mp */ MDBX_cursor *m2, *m3; @@ -7901,10 +8363,7 @@ new_sub: MDBX_page *mp = mc->mc_pg[i]; for (m2 = mc->mc_txn->mt_cursors[dbi]; m2; m2 = m2->mc_next) { - if (mc->mc_flags & C_SUB) - m3 = &m2->mc_xcursor->mx_cursor; - else - m3 = m2; + m3 = (mc->mc_flags & C_SUB) ? &m2->mc_xcursor->mx_cursor : m2; if (m3 == mc || m3->mc_snum < mc->mc_snum || m3->mc_pg[i] != mp) continue; if (m3->mc_ki[i] >= mc->mc_ki[i] && insert_key) { @@ -7955,7 +8414,7 @@ new_sub: MDBX_xcursor *mx = mc->mc_xcursor; unsigned i = mc->mc_top; MDBX_page *mp = mc->mc_pg[i]; - int nkeys = NUMKEYS(mp); + const int nkeys = NUMKEYS(mp); for (m2 = mc->mc_txn->mt_cursors[mc->mc_dbi]; m2; m2 = m2->mc_next) { if (m2 == mc || m2->mc_snum < mc->mc_snum) @@ -8007,6 +8466,8 @@ new_sub: } } } + if (rc == MDBX_SUCCESS && mdbx_audit_enabled()) + rc = mdbx_cursor_check(mc, false); return rc; bad_sub: if (unlikely(rc == MDBX_KEYEXIST)) @@ -8014,6 +8475,7 @@ new_sub: /* should not happen, we deleted that item */ rc = MDBX_PROBLEM; } +fail: mc->mc_txn->mt_flags |= MDBX_TXN_ERROR; return rc; } @@ -8107,6 +8569,9 @@ int mdbx_cursor_del(MDBX_cursor *mc, unsigned flags) { if (leaf->mn_flags & F_SUBDATA) { /* add all the child DB's pages to the free list */ + mc->mc_db->md_branch_pages -= mc->mc_xcursor->mx_db.md_branch_pages; + mc->mc_db->md_leaf_pages -= mc->mc_xcursor->mx_db.md_leaf_pages; + mc->mc_db->md_overflow_pages -= mc->mc_xcursor->mx_db.md_overflow_pages; rc = mdbx_drop0(&mc->mc_xcursor->mx_cursor, 0); if (unlikely(rc)) goto fail; @@ -8164,12 +8629,25 @@ static int mdbx_page_new(MDBX_cursor *mc, unsigned flags, unsigned num, mc->mc_db->md_branch_pages++; else if (IS_LEAF(np)) mc->mc_db->md_leaf_pages++; - else if (IS_OVERFLOW(np)) { + else { + mdbx_cassert(mc, IS_OVERFLOW(np)); mc->mc_db->md_overflow_pages += num; np->mp_pages = num; } - *mp = np; + if (unlikely(mc->mc_flags & C_SUB)) { + MDBX_db *outer = mdbx_outer_db(mc); + if (IS_BRANCH(np)) + outer->md_branch_pages++; + else if (IS_LEAF(np)) + outer->md_leaf_pages++; + else { + mdbx_cassert(mc, IS_OVERFLOW(np)); + outer->md_overflow_pages += num; + } + } + + *mp = np; return MDBX_SUCCESS; } @@ -8186,17 +8664,15 @@ static int mdbx_page_new(MDBX_cursor *mc, unsigned flags, unsigned num, * [in] data The data for the node. * * Returns The number of bytes needed to store the node. */ -static __inline size_t mdbx_leaf_size(MDBX_env *env, MDBX_val *key, - MDBX_val *data) { - size_t sz; - - sz = LEAFSIZE(key, data); +static __inline size_t mdbx_leaf_size(MDBX_env *env, const MDBX_val *key, + const MDBX_val *data) { + size_t sz = LEAFSIZE(key, data); if (sz > env->me_nodemax) { /* put on overflow page */ - sz -= data->iov_len - sizeof(pgno_t); + sz = sz - data->iov_len + sizeof(pgno_t); } - return EVEN(sz + sizeof(indx_t)); + return EVEN(sz) + sizeof(indx_t); } /* Calculate the size of a branch node. @@ -8211,21 +8687,223 @@ static __inline size_t mdbx_leaf_size(MDBX_env *env, MDBX_val *key, * [in] key The key for the node. * * Returns The number of bytes needed to store the node. */ -static __inline size_t mdbx_branch_size(MDBX_env *env, MDBX_val *key) { - size_t sz; - - sz = INDXSIZE(key); +static __inline size_t mdbx_branch_size(MDBX_env *env, const MDBX_val *key) { + size_t sz = INDXSIZE(key); if (unlikely(sz > env->me_nodemax)) { /* put on overflow page */ /* not implemented */ mdbx_assert_fail(env, "INDXSIZE(key) <= env->me_nodemax", __FUNCTION__, __LINE__); - sz -= key->iov_len - sizeof(pgno_t); + sz = sz - key->iov_len + sizeof(pgno_t); } - return sz + sizeof(indx_t); + return EVEN(sz) + sizeof(indx_t); } +static int __must_check_result mdbx_node_add_leaf2(MDBX_cursor *mc, + unsigned indx, + const MDBX_val *key) { + MDBX_page *mp = mc->mc_pg[mc->mc_top]; + DKBUF; + mdbx_debug("add to leaf2-%spage %" PRIaPGNO " index %i, " + " key size %" PRIuPTR " [%s]", + IS_SUBP(mp) ? "sub-" : "", mp->mp_pgno, indx, + key ? key->iov_len : 0, DKEY(key)); + + mdbx_cassert(mc, key); + mdbx_cassert(mc, PAGETYPE(mp) == (P_LEAF | P_LEAF2)); + const unsigned ksize = mc->mc_db->md_xsize; + mdbx_cassert(mc, ksize == key->iov_len); + + const int room = SIZELEFT(mp); + mdbx_cassert(mc, room >= (int)ksize); + if (unlikely(room < (int)ksize)) { + bailout: + mc->mc_txn->mt_flags |= MDBX_TXN_ERROR; + return MDBX_PAGE_FULL; + } + + char *const ptr = LEAF2KEY(mp, indx, ksize); + mdbx_cassert(mc, NUMKEYS(mp) >= indx); + if (unlikely(NUMKEYS(mp) < indx)) + goto bailout; + + const unsigned diff = NUMKEYS(mp) - indx; + if (likely(diff > 0)) + /* Move higher keys up one slot. */ + memmove(ptr + ksize, ptr, diff * ksize); + /* insert new key */ + memcpy(ptr, key->iov_base, ksize); + + /* Just using these for counting */ + mdbx_cassert(mc, UINT16_MAX - mp->mp_lower >= (int)sizeof(indx_t)); + mp->mp_lower += sizeof(indx_t); + mdbx_cassert(mc, mp->mp_upper >= ksize - sizeof(indx_t)); + mp->mp_upper -= (indx_t)(ksize - sizeof(indx_t)); + + mdbx_cassert(mc, + mp->mp_upper >= mp->mp_lower && + PAGEHDRSZ + mp->mp_upper <= mc->mc_txn->mt_env->me_psize); + return MDBX_SUCCESS; +} + +static int __must_check_result mdbx_node_add_branch(MDBX_cursor *mc, + unsigned indx, + const MDBX_val *key, + pgno_t pgno) { + MDBX_page *mp = mc->mc_pg[mc->mc_top]; + DKBUF; + mdbx_debug("add to branch-%spage %" PRIaPGNO " index %i, node-pgno %" PRIaPGNO + " key size %" PRIuPTR " [%s]", + IS_SUBP(mp) ? "sub-" : "", mp->mp_pgno, indx, pgno, + key ? key->iov_len : 0, DKEY(key)); + + mdbx_cassert(mc, PAGETYPE(mp) == P_BRANCH); + STATIC_ASSERT(NODESIZE % 2 == 0); + + const size_t room = SIZELEFT(mp); + const size_t node_size = + likely(key != NULL) ? NODESIZE + EVEN(key->iov_len) : NODESIZE; + mdbx_cassert(mc, mdbx_branch_size(mc->mc_txn->mt_env, key) == + node_size + sizeof(indx_t)); + mdbx_cassert(mc, room >= node_size + sizeof(indx_t)); + if (unlikely(room < node_size + sizeof(indx_t))) { + bailout: + mc->mc_txn->mt_flags |= MDBX_TXN_ERROR; + return MDBX_PAGE_FULL; + } + + const unsigned numkeys = NUMKEYS(mp); + mdbx_cassert(mc, numkeys >= indx); + if (unlikely(numkeys < indx)) + goto bailout; + + /* Move higher pointers up one slot. */ + for (unsigned i = numkeys; i > indx; --i) + mp->mp_ptrs[i] = mp->mp_ptrs[i - 1]; + + /* Adjust free space offsets. */ + const size_t ofs = mp->mp_upper - node_size; + mdbx_cassert(mc, ofs >= mp->mp_lower + sizeof(indx_t)); + mdbx_cassert(mc, ofs <= UINT16_MAX); + mp->mp_ptrs[indx] = (uint16_t)ofs; + mp->mp_upper = (uint16_t)ofs; + mp->mp_lower += sizeof(indx_t); + + /* Write the node data. */ + MDBX_node *node = NODEPTR(mp, indx); + SETPGNO(node, pgno); + node->mn_ksize = 0; + node->mn_flags = 0; + if (likely(key != NULL)) { + node->mn_ksize = (uint16_t)key->iov_len; + memcpy(NODEKEY(node), key->iov_base, key->iov_len); + } + + mdbx_cassert(mc, + mp->mp_upper >= mp->mp_lower && + PAGEHDRSZ + mp->mp_upper <= mc->mc_txn->mt_env->me_psize); + return MDBX_SUCCESS; +} + +static int __must_check_result mdbx_node_add_leaf(MDBX_cursor *mc, + unsigned indx, + const MDBX_val *key, + MDBX_val *data, + unsigned flags) { + MDBX_page *mp = mc->mc_pg[mc->mc_top]; + DKBUF; + mdbx_debug("add to leaf-%spage %" PRIaPGNO " index %i, data size %" PRIuPTR + " key size %" PRIuPTR " [%s]", + IS_SUBP(mp) ? "sub-" : "", mp->mp_pgno, indx, + data ? data->iov_len : 0, key ? key->iov_len : 0, DKEY(key)); + mdbx_cassert(mc, key != NULL && data != NULL); + mdbx_cassert(mc, PAGETYPE(mp) == P_LEAF); + MDBX_page *largepage = NULL; + + const size_t room = SIZELEFT(mp); + size_t node_size = NODESIZE + key->iov_len; + if (unlikely(flags & F_BIGDATA)) { + /* Data already on overflow page. */ + STATIC_ASSERT(sizeof(pgno_t) % 2 == 0); + node_size += sizeof(pgno_t); + } else if (unlikely(node_size + data->iov_len > + mc->mc_txn->mt_env->me_nodemax)) { + const pgno_t ovpages = OVPAGES(mc->mc_txn->mt_env, data->iov_len); + /* Put data on overflow page. */ + mdbx_debug("data size is %" PRIuPTR ", node would be %" PRIuPTR + ", put data on %u-overflow page(s)", + data->iov_len, node_size + data->iov_len, ovpages); + int rc = mdbx_page_new(mc, P_OVERFLOW, ovpages, &largepage); + if (unlikely(rc != MDBX_SUCCESS)) + return rc; + mdbx_debug("allocated overflow page %" PRIaPGNO "", largepage->mp_pgno); + flags |= F_BIGDATA; + node_size += sizeof(pgno_t); + mdbx_cassert(mc, mdbx_leaf_size(mc->mc_txn->mt_env, key, data) == + EVEN(node_size) + sizeof(indx_t)); + } else { + node_size += data->iov_len; + mdbx_cassert(mc, mdbx_leaf_size(mc->mc_txn->mt_env, key, data) == + EVEN(node_size) + sizeof(indx_t)); + } + + node_size = EVEN(node_size); + mdbx_cassert(mc, room >= node_size + sizeof(indx_t)); + if (unlikely(room < node_size + sizeof(indx_t))) { + bailout: + mc->mc_txn->mt_flags |= MDBX_TXN_ERROR; + return MDBX_PAGE_FULL; + } + + const unsigned numkeys = NUMKEYS(mp); + mdbx_cassert(mc, numkeys >= indx); + if (unlikely(numkeys < indx)) + goto bailout; + + /* Move higher pointers up one slot. */ + for (unsigned i = numkeys; i > indx; --i) + mp->mp_ptrs[i] = mp->mp_ptrs[i - 1]; + + /* Adjust free space offsets. */ + const size_t ofs = mp->mp_upper - node_size; + mdbx_cassert(mc, ofs >= mp->mp_lower + sizeof(indx_t)); + mdbx_cassert(mc, ofs <= UINT16_MAX); + mp->mp_ptrs[indx] = (uint16_t)ofs; + mp->mp_upper = (uint16_t)ofs; + mp->mp_lower += sizeof(indx_t); + + /* Write the node data. */ + MDBX_node *node = NODEPTR(mp, indx); + node->mn_ksize = (uint16_t)key->iov_len; + node->mn_flags = (uint16_t)flags; + SETDSZ(node, data->iov_len); + memcpy(NODEKEY(node), key->iov_base, key->iov_len); + + void *nodedata = NODEDATA(node); + if (likely(largepage == NULL)) { + if (unlikely(flags & F_BIGDATA)) + memcpy(nodedata, data->iov_base, sizeof(pgno_t)); + else if (unlikely(flags & MDBX_RESERVE)) + data->iov_base = nodedata; + else if (likely(nodedata != data->iov_base)) + memcpy(nodedata, data->iov_base, data->iov_len); + } else { + memcpy(nodedata, &largepage->mp_pgno, sizeof(pgno_t)); + nodedata = PAGEDATA(largepage); + if (unlikely(flags & MDBX_RESERVE)) + data->iov_base = nodedata; + else if (likely(nodedata != data->iov_base)) + memcpy(nodedata, data->iov_base, data->iov_len); + } + + mdbx_cassert(mc, + mp->mp_upper >= mp->mp_lower && + PAGEHDRSZ + mp->mp_upper <= mc->mc_txn->mt_env->me_psize); + return MDBX_SUCCESS; +} + +#if 0 /* Add a node to the page pointed to by the cursor. * Set MDBX_TXN_ERROR on failure. * @@ -8242,7 +8920,7 @@ static __inline size_t mdbx_branch_size(MDBX_env *env, MDBX_val *key) { * MDBX_PAGE_FULL - there is insufficient room in the page. This error * should never happen since all callers already calculate * the page's free space before calling this function. */ -static int mdbx_node_add(MDBX_cursor *mc, unsigned indx, MDBX_val *key, +static int mdbx_node_add(MDBX_cursor *mc, unsigned indx, const MDBX_val *key, MDBX_val *data, pgno_t pgno, unsigned flags) { unsigned i; size_t node_size = NODESIZE; @@ -8251,35 +8929,16 @@ static int mdbx_node_add(MDBX_cursor *mc, unsigned indx, MDBX_val *key, MDBX_page *mp = mc->mc_pg[mc->mc_top]; MDBX_page *ofp = NULL; /* overflow page */ void *ndata; - DKBUF; mdbx_cassert(mc, mp->mp_upper >= mp->mp_lower); + DKBUF; mdbx_debug("add to %s %spage %" PRIaPGNO " index %i, data size %" PRIuPTR " key size %" PRIuPTR " [%s]", IS_LEAF(mp) ? "leaf" : "branch", IS_SUBP(mp) ? "sub-" : "", mp->mp_pgno, indx, data ? data->iov_len : 0, key ? key->iov_len : 0, DKEY(key)); - if (IS_LEAF2(mp)) { - mdbx_cassert(mc, key); - /* Move higher keys up one slot. */ - const int ksize = mc->mc_db->md_xsize; - char *const ptr = LEAF2KEY(mp, indx, ksize); - const int diff = NUMKEYS(mp) - indx; - if (diff > 0) - memmove(ptr + ksize, ptr, diff * ksize); - /* insert new key */ - memcpy(ptr, key->iov_base, ksize); - - /* Just using these for counting */ - mdbx_cassert(mc, UINT16_MAX - mp->mp_lower >= (int)sizeof(indx_t)); - mp->mp_lower += sizeof(indx_t); - mdbx_cassert(mc, mp->mp_upper >= ksize - sizeof(indx_t)); - mp->mp_upper -= (indx_t)(ksize - sizeof(indx_t)); - return MDBX_SUCCESS; - } - room = (intptr_t)SIZELEFT(mp) - (intptr_t)sizeof(indx_t); if (key != NULL) node_size += key->iov_len; @@ -8339,7 +8998,7 @@ update: if (IS_LEAF(mp)) { ndata = NODEDATA(node); - if (unlikely(ofp == NULL)) { + if (likely(ofp == NULL)) { if (unlikely(F_ISSET(flags, F_BIGDATA))) memcpy(ndata, data->iov_base, sizeof(pgno_t)); else if (F_ISSET(flags, MDBX_RESERVE)) @@ -8367,6 +9026,7 @@ full: mc->mc_txn->mt_flags |= MDBX_TXN_ERROR; return MDBX_PAGE_FULL; } +#endif /* Delete the specified node from a page. * [in] mc Cursor pointing to the node to delete. @@ -8442,19 +9102,23 @@ static void mdbx_node_shrink(MDBX_page *mp, unsigned indx) { node = NODEPTR(mp, indx); sp = (MDBX_page *)NODEDATA(node); delta = SIZELEFT(sp); - nsize = NODEDSZ(node) - delta; + assert(delta > 0); /* Prepare to shift upward, set len = length(subpage part to shift) */ if (IS_LEAF2(sp)) { + delta &= /* do not make the node uneven-sized */ ~1u; + if (unlikely(delta) == 0) + return; + nsize = NODEDSZ(node) - delta; + assert(nsize % 1 == 0); len = nsize; - if (nsize & 1) - return; /* do not make the node uneven-sized */ } else { xp = (MDBX_page *)((char *)sp + delta); /* destination subpage */ for (i = NUMKEYS(sp); --i >= 0;) { assert(sp->mp_ptrs[i] >= delta); xp->mp_ptrs[i] = (indx_t)(sp->mp_ptrs[i] - delta); } + nsize = NODEDSZ(node) - delta; len = PAGEHDRSZ; } sp->mp_upper = sp->mp_lower; @@ -8517,7 +9181,7 @@ static int mdbx_xcursor_init1(MDBX_cursor *mc, MDBX_node *node) { if (unlikely(mx == nullptr)) return MDBX_CORRUPTED; - mdbx_cassert(mc, mc->mc_txn->mt_txnid >= mc->mc_txn->mt_env->me_oldest[0]); + mdbx_cassert(mc, mc->mc_txn->mt_txnid >= *mc->mc_txn->mt_env->me_oldest); if (node->mn_flags & F_SUBDATA) { memcpy(&mx->mx_db, NODEDATA(node), sizeof(MDBX_db)); mx->mx_cursor.mc_pg[0] = 0; @@ -8571,7 +9235,7 @@ static int mdbx_xcursor_init2(MDBX_cursor *mc, MDBX_xcursor *src_mx, if (unlikely(mx == nullptr)) return MDBX_CORRUPTED; - mdbx_cassert(mc, mc->mc_txn->mt_txnid >= mc->mc_txn->mt_env->me_oldest[0]); + mdbx_cassert(mc, mc->mc_txn->mt_txnid >= *mc->mc_txn->mt_env->me_oldest); if (new_dupdata) { mx->mx_cursor.mc_snum = 1; mx->mx_cursor.mc_top = 0; @@ -8590,8 +9254,7 @@ static int mdbx_xcursor_init2(MDBX_cursor *mc, MDBX_xcursor *src_mx, } /* Initialize a cursor for a given transaction and database. */ -static int mdbx_cursor_init(MDBX_cursor *mc, MDBX_txn *txn, MDBX_dbi dbi, - MDBX_xcursor *mx) { +static int mdbx_cursor_init(MDBX_cursor *mc, MDBX_txn *txn, MDBX_dbi dbi) { mc->mc_signature = MDBX_MC_SIGNATURE; mc->mc_next = NULL; mc->mc_backup = NULL; @@ -8608,6 +9271,8 @@ static int mdbx_cursor_init(MDBX_cursor *mc, MDBX_txn *txn, MDBX_dbi dbi, mc->mc_xcursor = NULL; if (txn->mt_dbs[dbi].md_flags & MDBX_DUPSORT) { + STATIC_ASSERT(offsetof(MDBX_cursor_couple, outer) == 0); + MDBX_xcursor *mx = &container_of(mc, MDBX_cursor_couple, outer)->inner; mdbx_tassert(txn, mx != NULL); mx->mx_cursor.mc_signature = MDBX_MC_SIGNATURE; mc->mc_xcursor = mx; @@ -8616,7 +9281,7 @@ static int mdbx_cursor_init(MDBX_cursor *mc, MDBX_txn *txn, MDBX_dbi dbi, return rc; } - mdbx_cassert(mc, mc->mc_txn->mt_txnid >= mc->mc_txn->mt_env->me_oldest[0]); + mdbx_cassert(mc, mc->mc_txn->mt_txnid >= *mc->mc_txn->mt_env->me_oldest); int rc = MDBX_SUCCESS; if (unlikely(*mc->mc_dbflag & DB_STALE)) { rc = mdbx_page_search(mc, NULL, MDBX_PS_ROOTONLY); @@ -8626,9 +9291,6 @@ static int mdbx_cursor_init(MDBX_cursor *mc, MDBX_txn *txn, MDBX_dbi dbi, } int mdbx_cursor_open(MDBX_txn *txn, MDBX_dbi dbi, MDBX_cursor **ret) { - MDBX_cursor *mc; - size_t size = sizeof(MDBX_cursor); - if (unlikely(!ret || !txn)) return MDBX_EINVAL; @@ -8647,11 +9309,13 @@ int mdbx_cursor_open(MDBX_txn *txn, MDBX_dbi dbi, MDBX_cursor **ret) { if (unlikely(dbi == FREE_DBI && !F_ISSET(txn->mt_flags, MDBX_TXN_RDONLY))) return MDBX_EINVAL; - if (txn->mt_dbs[dbi].md_flags & MDBX_DUPSORT) - size += sizeof(MDBX_xcursor); + const size_t size = (txn->mt_dbs[dbi].md_flags & MDBX_DUPSORT) + ? sizeof(MDBX_cursor_couple) + : sizeof(MDBX_cursor); + MDBX_cursor *mc; if (likely((mc = malloc(size)) != NULL)) { - int rc = mdbx_cursor_init(mc, txn, dbi, (MDBX_xcursor *)(mc + 1)); + int rc = mdbx_cursor_init(mc, txn, dbi); if (unlikely(rc != MDBX_SUCCESS)) { free(mc); return rc; @@ -8704,7 +9368,7 @@ int mdbx_cursor_renew(MDBX_txn *txn, MDBX_cursor *mc) { if (unlikely(txn->mt_flags & MDBX_TXN_BLOCKED)) return MDBX_BAD_TXN; - return mdbx_cursor_init(mc, txn, mc->mc_dbi, mc->mc_xcursor); + return mdbx_cursor_init(mc, txn, mc->mc_dbi); } /* Return the count of duplicate data items for the current key */ @@ -8796,7 +9460,7 @@ MDBX_dbi mdbx_cursor_dbi(MDBX_cursor *mc) { * [in] mc Cursor pointing to the node to operate on. * [in] key The new key to use. * Returns 0 on success, non-zero on failure. */ -static int mdbx_update_key(MDBX_cursor *mc, MDBX_val *key) { +static int mdbx_update_key(MDBX_cursor *mc, const MDBX_val *key) { MDBX_page *mp; MDBX_node *node; char *base; @@ -8826,13 +9490,15 @@ static int mdbx_update_key(MDBX_cursor *mc, MDBX_val *key) { /* Shift node contents if EVEN(key length) changed. */ if (delta) { - if (delta > 0 && SIZELEFT(mp) < delta) { - pgno_t pgno; + if (SIZELEFT(mp) < delta) { /* not enough space left, do a delete and split */ mdbx_debug("Not enough room, delta = %d, splitting...", delta); - pgno = NODEPGNO(node); + pgno_t pgno = NODEPGNO(node); mdbx_node_del(mc, 0); - return mdbx_page_split(mc, key, NULL, pgno, MDBX_SPLIT_REPLACE); + int rc = mdbx_page_split(mc, key, NULL, pgno, MDBX_SPLIT_REPLACE); + if (rc == MDBX_SUCCESS && mdbx_audit_enabled()) + rc = mdbx_cursor_check(mc, true); + return rc; } numkeys = NUMKEYS(mp); @@ -8856,182 +9522,194 @@ static int mdbx_update_key(MDBX_cursor *mc, MDBX_val *key) { if (node->mn_ksize != key->iov_len) node->mn_ksize = (uint16_t)key->iov_len; - if (key->iov_len) - memcpy(NODEKEY(node), key->iov_base, key->iov_len); - + memcpy(NODEKEY(node), key->iov_base, key->iov_len); return MDBX_SUCCESS; } static void mdbx_cursor_copy(const MDBX_cursor *csrc, MDBX_cursor *cdst); -/* Perform act while tracking temporary cursor mn */ -#define WITH_CURSOR_TRACKING(mn, act) \ - do { \ - mdbx_cassert(&(mn), \ - mn.mc_txn->mt_cursors != NULL /* must be not rdonly txt */); \ - MDBX_cursor mc_dummy, *tracked, \ - **tp = &(mn).mc_txn->mt_cursors[mn.mc_dbi]; \ - if ((mn).mc_flags & C_SUB) { \ - mc_dummy.mc_flags = C_INITIALIZED; \ - mc_dummy.mc_xcursor = (MDBX_xcursor *)&(mn); \ - tracked = &mc_dummy; \ - } else { \ - tracked = &(mn); \ - } \ - tracked->mc_next = *tp; \ - *tp = tracked; \ - { act; } \ - *tp = tracked->mc_next; \ - } while (0) - /* Move a node from csrc to cdst. */ static int mdbx_node_move(MDBX_cursor *csrc, MDBX_cursor *cdst, int fromleft) { - MDBX_node *srcnode; - MDBX_val key, data; - pgno_t srcpg; - MDBX_cursor mn; int rc; - unsigned flags; - DKBUF; /* Mark src and dst as dirty. */ if (unlikely((rc = mdbx_page_touch(csrc)) || (rc = mdbx_page_touch(cdst)))) return rc; - if (IS_LEAF2(csrc->mc_pg[csrc->mc_top])) { - key.iov_len = csrc->mc_db->md_xsize; - key.iov_base = LEAF2KEY(csrc->mc_pg[csrc->mc_top], - csrc->mc_ki[csrc->mc_top], key.iov_len); - data.iov_len = 0; - data.iov_base = NULL; - srcpg = 0; - flags = 0; - } else { - srcnode = NODEPTR(csrc->mc_pg[csrc->mc_top], csrc->mc_ki[csrc->mc_top]); - mdbx_cassert(csrc, !((size_t)srcnode & 1)); - srcpg = NODEPGNO(srcnode); - flags = srcnode->mn_flags; - if (csrc->mc_ki[csrc->mc_top] == 0 && - IS_BRANCH(csrc->mc_pg[csrc->mc_top])) { - unsigned snum = csrc->mc_snum; - MDBX_node *s2; + MDBX_page *const psrc = csrc->mc_pg[csrc->mc_top]; + MDBX_page *const pdst = cdst->mc_pg[cdst->mc_top]; + mdbx_cassert(csrc, PAGETYPE(psrc) == PAGETYPE(pdst)); + mdbx_cassert(csrc, csrc->mc_dbi == cdst->mc_dbi); + mdbx_cassert(csrc, csrc->mc_top == cdst->mc_top); + if (unlikely(PAGETYPE(psrc) != PAGETYPE(pdst))) { + bailout: + csrc->mc_txn->mt_flags |= MDBX_TXN_ERROR; + return MDBX_PROBLEM; + } + + MDBX_val key4move; + switch (PAGETYPE(psrc)) { + case P_BRANCH: { + const MDBX_node *srcnode = NODEPTR(psrc, csrc->mc_ki[csrc->mc_top]); + mdbx_cassert(csrc, srcnode->mn_flags == 0); + const pgno_t srcpg = NODEPGNO(srcnode); + key4move.iov_len = NODEKSZ(srcnode); + key4move.iov_base = NODEKEY(srcnode); + if (csrc->mc_ki[csrc->mc_top] == 0) { + const uint16_t snum = csrc->mc_snum; + mdbx_cassert(csrc, snum > 0); /* must find the lowest key below src */ rc = mdbx_page_search_lowest(csrc); + MDBX_page *psrc2 = csrc->mc_pg[csrc->mc_top]; + if (unlikely(rc)) + return rc; + mdbx_cassert(csrc, IS_LEAF(psrc2)); + if (unlikely(!IS_LEAF(psrc2))) + goto bailout; + if (IS_LEAF2(psrc2)) { + key4move.iov_len = csrc->mc_db->md_xsize; + key4move.iov_base = LEAF2KEY(psrc2, 0, key4move.iov_len); + } else { + const MDBX_node *s2 = NODEPTR(psrc2, 0); + key4move.iov_len = NODEKSZ(s2); + key4move.iov_base = NODEKEY(s2); + } + csrc->mc_snum = snum; + csrc->mc_top = snum - 1; + csrc->mc_ki[csrc->mc_top] = 0; + /* paranoia */ + mdbx_cassert(csrc, psrc == csrc->mc_pg[csrc->mc_top]); + mdbx_cassert(csrc, IS_BRANCH(psrc)); + if (unlikely(!IS_BRANCH(psrc))) + goto bailout; + } + + if (cdst->mc_ki[cdst->mc_top] == 0) { + const uint16_t snum = cdst->mc_snum; + mdbx_cassert(csrc, snum > 0); + MDBX_cursor mn; + mdbx_cursor_copy(cdst, &mn); + mn.mc_xcursor = NULL; + /* must find the lowest key below dst */ + rc = mdbx_page_search_lowest(&mn); if (unlikely(rc)) return rc; - if (IS_LEAF2(csrc->mc_pg[csrc->mc_top])) { - key.iov_len = csrc->mc_db->md_xsize; - key.iov_base = LEAF2KEY(csrc->mc_pg[csrc->mc_top], 0, key.iov_len); + MDBX_page *const pdst2 = mn.mc_pg[mn.mc_top]; + mdbx_cassert(cdst, IS_LEAF(pdst2)); + if (unlikely(!IS_LEAF(pdst2))) + goto bailout; + MDBX_val key; + if (IS_LEAF2(pdst2)) { + key.iov_len = mn.mc_db->md_xsize; + key.iov_base = LEAF2KEY(pdst2, 0, key.iov_len); } else { - s2 = NODEPTR(csrc->mc_pg[csrc->mc_top], 0); + MDBX_node *s2 = NODEPTR(pdst2, 0); key.iov_len = NODEKSZ(s2); key.iov_base = NODEKEY(s2); } - mdbx_cassert(csrc, snum >= 1 && snum <= UINT16_MAX); - csrc->mc_snum = (uint16_t)snum--; - csrc->mc_top = (uint16_t)snum; - } else { - key.iov_len = NODEKSZ(srcnode); - key.iov_base = NODEKEY(srcnode); + mn.mc_snum = snum; + mn.mc_top = snum - 1; + mn.mc_ki[mn.mc_top] = 0; + rc = mdbx_update_key(&mn, &key); + if (unlikely(rc)) + return rc; } + + mdbx_debug("moving %s-node %u [%s] on page %" PRIaPGNO + " to node %u on page %" PRIaPGNO, + "branch", csrc->mc_ki[csrc->mc_top], DKEY(&key4move), + psrc->mp_pgno, cdst->mc_ki[cdst->mc_top], pdst->mp_pgno); + /* Add the node to the destination page. */ + rc = + mdbx_node_add_branch(cdst, cdst->mc_ki[cdst->mc_top], &key4move, srcpg); + } break; + + case P_LEAF: { + const MDBX_node *srcnode = NODEPTR(psrc, csrc->mc_ki[csrc->mc_top]); + MDBX_val data; data.iov_len = NODEDSZ(srcnode); data.iov_base = NODEDATA(srcnode); - } - mn.mc_xcursor = NULL; - if (IS_BRANCH(cdst->mc_pg[cdst->mc_top]) && cdst->mc_ki[cdst->mc_top] == 0) { - unsigned snum = cdst->mc_snum; - MDBX_node *s2; - MDBX_val bkey; - /* must find the lowest key below dst */ - mdbx_cursor_copy(cdst, &mn); - rc = mdbx_page_search_lowest(&mn); - if (unlikely(rc)) - return rc; - if (IS_LEAF2(mn.mc_pg[mn.mc_top])) { - bkey.iov_len = mn.mc_db->md_xsize; - bkey.iov_base = LEAF2KEY(mn.mc_pg[mn.mc_top], 0, bkey.iov_len); - } else { - s2 = NODEPTR(mn.mc_pg[mn.mc_top], 0); - bkey.iov_len = NODEKSZ(s2); - bkey.iov_base = NODEKEY(s2); - } - mdbx_cassert(csrc, snum >= 1 && snum <= UINT16_MAX); - mn.mc_snum = (uint16_t)snum--; - mn.mc_top = (uint16_t)snum; - mn.mc_ki[snum] = 0; - rc = mdbx_update_key(&mn, &bkey); - if (unlikely(rc)) - return rc; - } + key4move.iov_len = NODEKSZ(srcnode); + key4move.iov_base = NODEKEY(srcnode); + mdbx_debug("moving %s-node %u [%s] on page %" PRIaPGNO + " to node %u on page %" PRIaPGNO, + "leaf", csrc->mc_ki[csrc->mc_top], DKEY(&key4move), + psrc->mp_pgno, cdst->mc_ki[cdst->mc_top], pdst->mp_pgno); + /* Add the node to the destination page. */ + rc = mdbx_node_add_leaf(cdst, cdst->mc_ki[cdst->mc_top], &key4move, &data, + srcnode->mn_flags); + } break; + + case P_LEAF | P_LEAF2: { + key4move.iov_len = csrc->mc_db->md_xsize; + key4move.iov_base = + LEAF2KEY(psrc, csrc->mc_ki[csrc->mc_top], key4move.iov_len); + mdbx_debug("moving %s-node %u [%s] on page %" PRIaPGNO + " to node %u on page %" PRIaPGNO, + "leaf2", csrc->mc_ki[csrc->mc_top], DKEY(&key4move), + psrc->mp_pgno, cdst->mc_ki[cdst->mc_top], pdst->mp_pgno); + /* Add the node to the destination page. */ + rc = mdbx_node_add_leaf2(cdst, cdst->mc_ki[cdst->mc_top], &key4move); + } break; - mdbx_debug("moving %s node %u [%s] on page %" PRIaPGNO - " to node %u on page %" PRIaPGNO "", - IS_LEAF(csrc->mc_pg[csrc->mc_top]) ? "leaf" : "branch", - csrc->mc_ki[csrc->mc_top], DKEY(&key), - csrc->mc_pg[csrc->mc_top]->mp_pgno, cdst->mc_ki[cdst->mc_top], - cdst->mc_pg[cdst->mc_top]->mp_pgno); + default: + goto bailout; + } - /* Add the node to the destination page. */ - rc = - mdbx_node_add(cdst, cdst->mc_ki[cdst->mc_top], &key, &data, srcpg, flags); if (unlikely(rc != MDBX_SUCCESS)) return rc; /* Delete the node from the source page. */ - mdbx_node_del(csrc, key.iov_len); + mdbx_node_del(csrc, key4move.iov_len); + + mdbx_cassert(csrc, psrc == csrc->mc_pg[csrc->mc_top]); + mdbx_cassert(cdst, pdst == cdst->mc_pg[cdst->mc_top]); + mdbx_cassert(csrc, PAGETYPE(psrc) == PAGETYPE(pdst)); { /* Adjust other cursors pointing to mp */ MDBX_cursor *m2, *m3; - MDBX_dbi dbi = csrc->mc_dbi; - MDBX_page *mpd, *mps; - - mps = csrc->mc_pg[csrc->mc_top]; - /* If we're adding on the left, bump others up */ + const MDBX_dbi dbi = csrc->mc_dbi; + mdbx_cassert(csrc, csrc->mc_top == cdst->mc_top); if (fromleft) { - mpd = cdst->mc_pg[csrc->mc_top]; + /* If we're adding on the left, bump others up */ for (m2 = csrc->mc_txn->mt_cursors[dbi]; m2; m2 = m2->mc_next) { - if (csrc->mc_flags & C_SUB) - m3 = &m2->mc_xcursor->mx_cursor; - else - m3 = m2; + m3 = (csrc->mc_flags & C_SUB) ? &m2->mc_xcursor->mx_cursor : m2; if (!(m3->mc_flags & C_INITIALIZED) || m3->mc_top < csrc->mc_top) continue; - if (m3 != cdst && m3->mc_pg[csrc->mc_top] == mpd && + if (m3 != cdst && m3->mc_pg[csrc->mc_top] == pdst && m3->mc_ki[csrc->mc_top] >= cdst->mc_ki[csrc->mc_top]) { m3->mc_ki[csrc->mc_top]++; } - if (m3 != csrc && m3->mc_pg[csrc->mc_top] == mps && + if (m3 != csrc && m3->mc_pg[csrc->mc_top] == psrc && m3->mc_ki[csrc->mc_top] == csrc->mc_ki[csrc->mc_top]) { - m3->mc_pg[csrc->mc_top] = cdst->mc_pg[cdst->mc_top]; + m3->mc_pg[csrc->mc_top] = pdst; m3->mc_ki[csrc->mc_top] = cdst->mc_ki[cdst->mc_top]; + mdbx_cassert(csrc, csrc->mc_top > 0); m3->mc_ki[csrc->mc_top - 1]++; } - if (XCURSOR_INITED(m3) && IS_LEAF(mps)) + if (XCURSOR_INITED(m3) && IS_LEAF(psrc)) XCURSOR_REFRESH(m3, m3->mc_pg[csrc->mc_top], m3->mc_ki[csrc->mc_top]); } - } else - /* Adding on the right, bump others down */ - { + } else { + /* Adding on the right, bump others down */ for (m2 = csrc->mc_txn->mt_cursors[dbi]; m2; m2 = m2->mc_next) { - if (csrc->mc_flags & C_SUB) - m3 = &m2->mc_xcursor->mx_cursor; - else - m3 = m2; + m3 = (csrc->mc_flags & C_SUB) ? &m2->mc_xcursor->mx_cursor : m2; if (m3 == csrc) continue; if (!(m3->mc_flags & C_INITIALIZED) || m3->mc_top < csrc->mc_top) continue; - if (m3->mc_pg[csrc->mc_top] == mps) { + if (m3->mc_pg[csrc->mc_top] == psrc) { if (!m3->mc_ki[csrc->mc_top]) { - m3->mc_pg[csrc->mc_top] = cdst->mc_pg[cdst->mc_top]; + m3->mc_pg[csrc->mc_top] = pdst; m3->mc_ki[csrc->mc_top] = cdst->mc_ki[cdst->mc_top]; + mdbx_cassert(csrc, csrc->mc_top > 0); m3->mc_ki[csrc->mc_top - 1]--; } else { m3->mc_ki[csrc->mc_top]--; } - if (XCURSOR_INITED(m3) && IS_LEAF(mps)) + if (XCURSOR_INITED(m3) && IS_LEAF(psrc)) XCURSOR_REFRESH(m3, m3->mc_pg[csrc->mc_top], m3->mc_ki[csrc->mc_top]); } @@ -9041,17 +9719,23 @@ static int mdbx_node_move(MDBX_cursor *csrc, MDBX_cursor *cdst, int fromleft) { /* Update the parent separators. */ if (csrc->mc_ki[csrc->mc_top] == 0) { + mdbx_cassert(csrc, csrc->mc_top > 0); if (csrc->mc_ki[csrc->mc_top - 1] != 0) { - if (IS_LEAF2(csrc->mc_pg[csrc->mc_top])) { - key.iov_base = LEAF2KEY(csrc->mc_pg[csrc->mc_top], 0, key.iov_len); + MDBX_val key; + if (IS_LEAF2(psrc)) { + key.iov_len = psrc->mp_leaf2_ksize; + key.iov_base = LEAF2KEY(psrc, 0, key.iov_len); } else { - srcnode = NODEPTR(csrc->mc_pg[csrc->mc_top], 0); + MDBX_node *srcnode = NODEPTR(psrc, 0); key.iov_len = NODEKSZ(srcnode); key.iov_base = NODEKEY(srcnode); } mdbx_debug("update separator for source page %" PRIaPGNO " to [%s]", - csrc->mc_pg[csrc->mc_top]->mp_pgno, DKEY(&key)); + psrc->mp_pgno, DKEY(&key)); + MDBX_cursor mn; mdbx_cursor_copy(csrc, &mn); + mn.mc_xcursor = NULL; + mdbx_cassert(csrc, mn.mc_snum > 0); mn.mc_snum--; mn.mc_top--; /* We want mdbx_rebalance to find mn when doing fixups */ @@ -9059,10 +9743,9 @@ static int mdbx_node_move(MDBX_cursor *csrc, MDBX_cursor *cdst, int fromleft) { if (unlikely(rc != MDBX_SUCCESS)) return rc; } - if (IS_BRANCH(csrc->mc_pg[csrc->mc_top])) { - MDBX_val nullkey; - indx_t ix = csrc->mc_ki[csrc->mc_top]; - nullkey.iov_len = 0; + if (IS_BRANCH(psrc)) { + const MDBX_val nullkey = {0, 0}; + const indx_t ix = csrc->mc_ki[csrc->mc_top]; csrc->mc_ki[csrc->mc_top] = 0; rc = mdbx_update_key(csrc, &nullkey); csrc->mc_ki[csrc->mc_top] = ix; @@ -9071,17 +9754,23 @@ static int mdbx_node_move(MDBX_cursor *csrc, MDBX_cursor *cdst, int fromleft) { } if (cdst->mc_ki[cdst->mc_top] == 0) { + mdbx_cassert(cdst, cdst->mc_top > 0); if (cdst->mc_ki[cdst->mc_top - 1] != 0) { - if (IS_LEAF2(csrc->mc_pg[csrc->mc_top])) { - key.iov_base = LEAF2KEY(cdst->mc_pg[cdst->mc_top], 0, key.iov_len); + MDBX_val key; + if (IS_LEAF2(psrc)) { + key.iov_len = pdst->mp_leaf2_ksize; + key.iov_base = LEAF2KEY(pdst, 0, key.iov_len); } else { - srcnode = NODEPTR(cdst->mc_pg[cdst->mc_top], 0); + MDBX_node *srcnode = NODEPTR(pdst, 0); key.iov_len = NODEKSZ(srcnode); key.iov_base = NODEKEY(srcnode); } mdbx_debug("update separator for destination page %" PRIaPGNO " to [%s]", - cdst->mc_pg[cdst->mc_top]->mp_pgno, DKEY(&key)); + pdst->mp_pgno, DKEY(&key)); + MDBX_cursor mn; mdbx_cursor_copy(cdst, &mn); + mn.mc_xcursor = NULL; + mdbx_cassert(cdst, mn.mc_snum > 0); mn.mc_snum--; mn.mc_top--; /* We want mdbx_rebalance to find mn when doing fixups */ @@ -9089,10 +9778,9 @@ static int mdbx_node_move(MDBX_cursor *csrc, MDBX_cursor *cdst, int fromleft) { if (unlikely(rc != MDBX_SUCCESS)) return rc; } - if (IS_BRANCH(cdst->mc_pg[cdst->mc_top])) { - MDBX_val nullkey; - indx_t ix = cdst->mc_ki[cdst->mc_top]; - nullkey.iov_len = 0; + if (IS_BRANCH(pdst)) { + const MDBX_val nullkey = {0, 0}; + const indx_t ix = cdst->mc_ki[cdst->mc_top]; cdst->mc_ki[cdst->mc_top] = 0; rc = mdbx_update_key(cdst, &nullkey); cdst->mc_ki[cdst->mc_top] = ix; @@ -9113,46 +9801,50 @@ static int mdbx_node_move(MDBX_cursor *csrc, MDBX_cursor *cdst, int fromleft) { * * Returns 0 on success, non-zero on failure. */ static int mdbx_page_merge(MDBX_cursor *csrc, MDBX_cursor *cdst) { - MDBX_page *psrc, *pdst; MDBX_node *srcnode; - MDBX_val key, data; - unsigned nkeys; + MDBX_val key; int rc; - unsigned i, j; - psrc = csrc->mc_pg[csrc->mc_top]; - pdst = cdst->mc_pg[cdst->mc_top]; - - mdbx_debug("merging page %" PRIaPGNO " into %" PRIaPGNO "", psrc->mp_pgno, - pdst->mp_pgno); - - mdbx_cassert(csrc, csrc->mc_snum > 1); /* can't merge root page */ - mdbx_cassert(csrc, cdst->mc_snum > 1); + mdbx_cassert(csrc, csrc != cdst); /* Mark dst as dirty. */ if (unlikely(rc = mdbx_page_touch(cdst))) return rc; - /* get dst page again now that we've touched it. */ - pdst = cdst->mc_pg[cdst->mc_top]; + MDBX_page *const psrc = csrc->mc_pg[csrc->mc_top]; + MDBX_page *const pdst = cdst->mc_pg[cdst->mc_top]; + + mdbx_debug("merging page %" PRIaPGNO " into %" PRIaPGNO "", psrc->mp_pgno, + pdst->mp_pgno); - /* Move all nodes from src to dst. */ - j = nkeys = NUMKEYS(pdst); - if (IS_LEAF2(psrc)) { + mdbx_cassert(csrc, PAGETYPE(psrc) == PAGETYPE(pdst)); + mdbx_cassert(csrc, + csrc->mc_dbi == cdst->mc_dbi && csrc->mc_db == cdst->mc_db); + mdbx_cassert(csrc, csrc->mc_snum > 1); /* can't merge root page */ + mdbx_cassert(cdst, cdst->mc_snum > 1); + mdbx_cassert(cdst, cdst->mc_snum < cdst->mc_db->md_depth || + IS_LEAF(cdst->mc_pg[cdst->mc_db->md_depth - 1])); + mdbx_cassert(csrc, csrc->mc_snum < csrc->mc_db->md_depth || + IS_LEAF(csrc->mc_pg[csrc->mc_db->md_depth - 1])); + const int pagetype = PAGETYPE(psrc); + + /* Move all nodes from src to dst */ + const unsigned nkeys = NUMKEYS(pdst); + unsigned j = nkeys; + if (unlikely(pagetype & P_LEAF2)) { key.iov_len = csrc->mc_db->md_xsize; key.iov_base = PAGEDATA(psrc); - for (i = 0; i < NUMKEYS(psrc); i++, j++) { - rc = mdbx_node_add(cdst, j, &key, NULL, 0, 0); + for (unsigned i = 0; i < NUMKEYS(psrc); i++, j++) { + rc = mdbx_node_add_leaf2(cdst, j, &key); if (unlikely(rc != MDBX_SUCCESS)) return rc; key.iov_base = (char *)key.iov_base + key.iov_len; } } else { - for (i = 0; i < NUMKEYS(psrc); i++, j++) { + for (unsigned i = 0; i < NUMKEYS(psrc); i++, j++) { srcnode = NODEPTR(psrc, i); - if (i == 0 && IS_BRANCH(psrc)) { + if (i == 0 && (pagetype & P_BRANCH)) { MDBX_cursor mn; - MDBX_node *s2; mdbx_cursor_copy(csrc, &mn); mn.mc_xcursor = NULL; /* must find the lowest key below src */ @@ -9163,7 +9855,7 @@ static int mdbx_page_merge(MDBX_cursor *csrc, MDBX_cursor *cdst) { key.iov_len = mn.mc_db->md_xsize; key.iov_base = LEAF2KEY(mn.mc_pg[mn.mc_top], 0, key.iov_len); } else { - s2 = NODEPTR(mn.mc_pg[mn.mc_top], 0); + MDBX_node *s2 = NODEPTR(mn.mc_pg[mn.mc_top], 0); key.iov_len = NODEKSZ(s2); key.iov_base = NODEKEY(s2); } @@ -9172,10 +9864,15 @@ static int mdbx_page_merge(MDBX_cursor *csrc, MDBX_cursor *cdst) { key.iov_base = NODEKEY(srcnode); } - data.iov_len = NODEDSZ(srcnode); - data.iov_base = NODEDATA(srcnode); - rc = mdbx_node_add(cdst, j, &key, &data, NODEPGNO(srcnode), - srcnode->mn_flags); + if (pagetype & P_LEAF) { + MDBX_val data; + data.iov_len = NODEDSZ(srcnode); + data.iov_base = NODEDATA(srcnode); + rc = mdbx_node_add_leaf(cdst, j, &key, &data, srcnode->mn_flags); + } else { + mdbx_cassert(csrc, srcnode->mn_flags == 0); + rc = mdbx_node_add_branch(cdst, j, &key, NODEPGNO(srcnode)); + } if (unlikely(rc != MDBX_SUCCESS)) return rc; } @@ -9183,14 +9880,17 @@ static int mdbx_page_merge(MDBX_cursor *csrc, MDBX_cursor *cdst) { mdbx_debug("dst page %" PRIaPGNO " now has %u keys (%.1f%% filled)", pdst->mp_pgno, NUMKEYS(pdst), - (float)PAGEFILL(cdst->mc_txn->mt_env, pdst) / 10); + PAGEFILL(cdst->mc_txn->mt_env, pdst) / 10.24); + + mdbx_cassert(csrc, psrc == csrc->mc_pg[csrc->mc_top]); + mdbx_cassert(cdst, pdst == cdst->mc_pg[cdst->mc_top]); /* Unlink the src page from parent and add to free list. */ csrc->mc_top--; mdbx_node_del(csrc, 0); if (csrc->mc_ki[csrc->mc_top] == 0) { - key.iov_len = 0; - rc = mdbx_update_key(csrc, &key); + const MDBX_val nullkey = {0, 0}; + rc = mdbx_update_key(csrc, &nullkey); if (unlikely(rc)) { csrc->mc_top++; return rc; @@ -9198,31 +9898,18 @@ static int mdbx_page_merge(MDBX_cursor *csrc, MDBX_cursor *cdst) { } csrc->mc_top++; - psrc = csrc->mc_pg[csrc->mc_top]; - /* If not operating on FreeDB, allow this page to be reused - * in this txn. Otherwise just add to free list. */ - rc = mdbx_page_loose(csrc, psrc); - if (unlikely(rc)) - return rc; + mdbx_cassert(csrc, psrc == csrc->mc_pg[csrc->mc_top]); + mdbx_cassert(cdst, pdst == cdst->mc_pg[cdst->mc_top]); - if (IS_LEAF(psrc)) - csrc->mc_db->md_leaf_pages--; - else - csrc->mc_db->md_branch_pages--; { /* Adjust other cursors pointing to mp */ MDBX_cursor *m2, *m3; - MDBX_dbi dbi = csrc->mc_dbi; - unsigned top = csrc->mc_top; + const MDBX_dbi dbi = csrc->mc_dbi; + const unsigned top = csrc->mc_top; for (m2 = csrc->mc_txn->mt_cursors[dbi]; m2; m2 = m2->mc_next) { - if (csrc->mc_flags & C_SUB) - m3 = &m2->mc_xcursor->mx_cursor; - else - m3 = m2; - if (m3 == csrc) - continue; - if (m3->mc_snum < csrc->mc_snum) + m3 = (csrc->mc_flags & C_SUB) ? &m2->mc_xcursor->mx_cursor : m2; + if (m3 == csrc || top >= m3->mc_snum) continue; if (m3->mc_pg[top] == psrc) { m3->mc_pg[top] = pdst; @@ -9237,23 +9924,93 @@ static int mdbx_page_merge(MDBX_cursor *csrc, MDBX_cursor *cdst) { XCURSOR_REFRESH(m3, m3->mc_pg[top], m3->mc_ki[top]); } } - { - unsigned snum = cdst->mc_snum; - uint16_t depth = cdst->mc_db->md_depth; - mdbx_cursor_pop(cdst); - rc = mdbx_rebalance(cdst); - if (unlikely(rc)) - return rc; - mdbx_cassert(cdst, cdst->mc_db->md_entries > 0); - /* Did the tree height change? */ - if (depth != cdst->mc_db->md_depth) - snum += cdst->mc_db->md_depth - depth; - mdbx_cassert(cdst, snum >= 1 && snum <= UINT16_MAX); - cdst->mc_snum = (uint16_t)snum; - cdst->mc_top = (uint16_t)(snum - 1); + /* If not operating on FreeDB, allow this page to be reused + * in this txn. Otherwise just add to free list. */ + rc = mdbx_page_loose(csrc, psrc); + if (unlikely(rc)) + return rc; + + mdbx_cassert(cdst, cdst->mc_db->md_entries > 0); + mdbx_cassert(cdst, cdst->mc_snum <= cdst->mc_db->md_depth); + mdbx_cassert(cdst, cdst->mc_top > 0); + mdbx_cassert(cdst, cdst->mc_snum == cdst->mc_top + 1); + MDBX_page *const top_page = cdst->mc_pg[cdst->mc_top]; + const indx_t top_indx = cdst->mc_ki[cdst->mc_top]; + const uint16_t save_snum = cdst->mc_snum; + const uint16_t save_depth = cdst->mc_db->md_depth; + mdbx_cursor_pop(cdst); + rc = mdbx_rebalance(cdst); + if (unlikely(rc)) + return rc; + + mdbx_cassert(cdst, cdst->mc_db->md_entries > 0); + mdbx_cassert(cdst, cdst->mc_snum <= cdst->mc_db->md_depth); + mdbx_cassert(cdst, cdst->mc_snum == cdst->mc_top + 1); + + if (IS_LEAF(cdst->mc_pg[cdst->mc_top])) { + /* LY: don't touch cursor if top-page is a LEAF */ + mdbx_cassert(cdst, IS_LEAF(cdst->mc_pg[cdst->mc_top]) || + PAGETYPE(cdst->mc_pg[cdst->mc_top]) == pagetype); + return MDBX_SUCCESS; } - return MDBX_SUCCESS; + + if (pagetype != PAGETYPE(top_page)) { + /* LY: LEAF-page becomes BRANCH, unable restore cursor's stack */ + goto bailout; + } + + if (top_page == cdst->mc_pg[cdst->mc_top]) { + /* LY: don't touch cursor if prev top-page already on the top */ + mdbx_cassert(cdst, cdst->mc_ki[cdst->mc_top] == top_indx); + mdbx_cassert(cdst, IS_LEAF(cdst->mc_pg[cdst->mc_top]) || + PAGETYPE(cdst->mc_pg[cdst->mc_top]) == pagetype); + return MDBX_SUCCESS; + } + + const int new_snum = save_snum - save_depth + cdst->mc_db->md_depth; + if (unlikely(new_snum < 1 || new_snum > cdst->mc_db->md_depth)) { + /* LY: out of range, unable restore cursor's stack */ + goto bailout; + } + + if (top_page == cdst->mc_pg[new_snum - 1]) { + mdbx_cassert(cdst, cdst->mc_ki[new_snum - 1] == top_indx); + /* LY: restore cursor stack */ + cdst->mc_snum = (uint16_t)new_snum; + cdst->mc_top = (uint16_t)new_snum - 1; + mdbx_cassert(cdst, cdst->mc_snum < cdst->mc_db->md_depth || + IS_LEAF(cdst->mc_pg[cdst->mc_db->md_depth - 1])); + mdbx_cassert(cdst, IS_LEAF(cdst->mc_pg[cdst->mc_top]) || + PAGETYPE(cdst->mc_pg[cdst->mc_top]) == pagetype); + return MDBX_SUCCESS; + } + + MDBX_page *const stub_page = (MDBX_page *)(~(uintptr_t)top_page); + const indx_t stub_indx = top_indx; + if (save_depth > cdst->mc_db->md_depth && + ((cdst->mc_pg[save_snum - 1] == top_page && + cdst->mc_ki[save_snum - 1] == top_indx) || + (cdst->mc_pg[save_snum - 1] == stub_page && + cdst->mc_ki[save_snum - 1] == stub_indx))) { + /* LY: restore cursor stack */ + cdst->mc_pg[new_snum - 1] = top_page; + cdst->mc_ki[new_snum - 1] = top_indx; + cdst->mc_pg[new_snum] = (MDBX_page *)(~(uintptr_t)cdst->mc_pg[new_snum]); + cdst->mc_ki[new_snum] = ~cdst->mc_ki[new_snum]; + cdst->mc_snum = (uint16_t)new_snum; + cdst->mc_top = (uint16_t)new_snum - 1; + mdbx_cassert(cdst, cdst->mc_snum < cdst->mc_db->md_depth || + IS_LEAF(cdst->mc_pg[cdst->mc_db->md_depth - 1])); + mdbx_cassert(cdst, IS_LEAF(cdst->mc_pg[cdst->mc_top]) || + PAGETYPE(cdst->mc_pg[cdst->mc_top]) == pagetype); + return MDBX_SUCCESS; + } + +bailout: + /* LY: unable restore cursor's stack */ + cdst->mc_flags &= ~C_INITIALIZED; + return MDBX_CURSOR_FULL; } /* Copy the contents of a cursor. @@ -9263,7 +10020,7 @@ static void mdbx_cursor_copy(const MDBX_cursor *csrc, MDBX_cursor *cdst) { unsigned i; mdbx_cassert(csrc, - csrc->mc_txn->mt_txnid >= csrc->mc_txn->mt_env->me_oldest[0]); + csrc->mc_txn->mt_txnid >= *csrc->mc_txn->mt_env->me_oldest); cdst->mc_txn = csrc->mc_txn; cdst->mc_dbi = csrc->mc_dbi; cdst->mc_db = csrc->mc_db; @@ -9283,12 +10040,14 @@ static void mdbx_cursor_copy(const MDBX_cursor *csrc, MDBX_cursor *cdst) { * Returns 0 on success, non-zero on failure. */ static int mdbx_rebalance(MDBX_cursor *mc) { MDBX_node *node; - int rc, fromleft; - unsigned ptop, minkeys, thresh; - MDBX_cursor mn; - indx_t oldki; + int rc; + unsigned minkeys, thresh; - if (IS_BRANCH(mc->mc_pg[mc->mc_top])) { + mdbx_cassert(mc, mc->mc_snum > 0); + mdbx_cassert(mc, mc->mc_snum < mc->mc_db->md_depth || + IS_LEAF(mc->mc_pg[mc->mc_db->md_depth - 1])); + const int pagetype = PAGETYPE(mc->mc_pg[mc->mc_top]); + if (pagetype == P_BRANCH) { minkeys = 2; thresh = 1; } else { @@ -9296,9 +10055,9 @@ static int mdbx_rebalance(MDBX_cursor *mc) { thresh = FILL_THRESHOLD; } mdbx_debug("rebalancing %s page %" PRIaPGNO " (has %u keys, %.1f%% full)", - IS_LEAF(mc->mc_pg[mc->mc_top]) ? "leaf" : "branch", + (pagetype & P_LEAF) ? "leaf" : "branch", mc->mc_pg[mc->mc_top]->mp_pgno, NUMKEYS(mc->mc_pg[mc->mc_top]), - (float)PAGEFILL(mc->mc_txn->mt_env, mc->mc_pg[mc->mc_top]) / 10); + PAGEFILL(mc->mc_txn->mt_env, mc->mc_pg[mc->mc_top]) / 10.24); if (PAGEFILL(mc->mc_txn->mt_env, mc->mc_pg[mc->mc_top]) >= thresh && NUMKEYS(mc->mc_pg[mc->mc_top]) >= minkeys) { @@ -9314,15 +10073,22 @@ static int mdbx_rebalance(MDBX_cursor *mc) { mdbx_cassert(mc, (mc->mc_db->md_entries == 0) == (nkeys == 0)); if (IS_SUBP(mp)) { mdbx_debug("Can't rebalance a subpage, ignoring"); + mdbx_cassert(mc, pagetype & P_LEAF); return MDBX_SUCCESS; } if (nkeys == 0) { + mdbx_cassert(mc, IS_LEAF(mp)); mdbx_debug("tree is completely empty"); mc->mc_db->md_root = P_INVALID; mc->mc_db->md_depth = 0; + mdbx_cassert(mc, mc->mc_db->md_branch_pages == 0 && + mc->mc_db->md_overflow_pages == 0 && + mc->mc_db->md_leaf_pages == 1); mc->mc_db->md_leaf_pages = 0; + if (mc->mc_flags & C_SUB) + mdbx_outer_db(mc)->md_leaf_pages -= 1; rc = mdbx_pnl_append(&mc->mc_txn->mt_befree_pages, mp->mp_pgno); - if (unlikely(rc)) + if (unlikely(rc != MDBX_SUCCESS)) return rc; /* Adjust cursors pointing to mp */ const MDBX_dbi dbi = mc->mc_dbi; @@ -9330,7 +10096,7 @@ static int mdbx_rebalance(MDBX_cursor *mc) { m2 = m2->mc_next) { MDBX_cursor *m3 = (mc->mc_flags & C_SUB) ? &m2->mc_xcursor->mx_cursor : m2; - if (!(m3->mc_flags & C_INITIALIZED) || (m3->mc_snum < mc->mc_snum)) + if (m3 == mc || !(m3->mc_flags & C_INITIALIZED)) continue; if (m3->mc_pg[0] == mp) { m3->mc_snum = 0; @@ -9342,46 +10108,46 @@ static int mdbx_rebalance(MDBX_cursor *mc) { mc->mc_top = 0; mc->mc_flags &= ~C_INITIALIZED; } else if (IS_BRANCH(mp) && nkeys == 1) { - int i; mdbx_debug("collapsing root page!"); rc = mdbx_pnl_append(&mc->mc_txn->mt_befree_pages, mp->mp_pgno); if (unlikely(rc)) return rc; mc->mc_db->md_root = NODEPGNO(NODEPTR(mp, 0)); rc = mdbx_page_get(mc, mc->mc_db->md_root, &mc->mc_pg[0], NULL); - if (unlikely(rc)) + if (unlikely(rc != MDBX_SUCCESS)) return rc; mc->mc_db->md_depth--; mc->mc_db->md_branch_pages--; + if (mc->mc_flags & C_SUB) + mdbx_outer_db(mc)->md_branch_pages -= 1; mc->mc_ki[0] = mc->mc_ki[1]; - for (i = 1; i < mc->mc_db->md_depth; i++) { + for (int i = 1; i < mc->mc_db->md_depth; i++) { mc->mc_pg[i] = mc->mc_pg[i + 1]; mc->mc_ki[i] = mc->mc_ki[i + 1]; } - { - /* Adjust other cursors pointing to mp */ - MDBX_cursor *m2, *m3; - MDBX_dbi dbi = mc->mc_dbi; - for (m2 = mc->mc_txn->mt_cursors[dbi]; m2; m2 = m2->mc_next) { - if (mc->mc_flags & C_SUB) - m3 = &m2->mc_xcursor->mx_cursor; - else - m3 = m2; - if (m3 == mc) - continue; - if (!(m3->mc_flags & C_INITIALIZED)) - continue; - if (m3->mc_pg[0] == mp) { - for (i = 0; i < mc->mc_db->md_depth; i++) { - m3->mc_pg[i] = m3->mc_pg[i + 1]; - m3->mc_ki[i] = m3->mc_ki[i + 1]; - } - m3->mc_snum--; - m3->mc_top--; + /* Adjust other cursors pointing to mp */ + MDBX_cursor *m2, *m3; + MDBX_dbi dbi = mc->mc_dbi; + + for (m2 = mc->mc_txn->mt_cursors[dbi]; m2; m2 = m2->mc_next) { + m3 = (mc->mc_flags & C_SUB) ? &m2->mc_xcursor->mx_cursor : m2; + if (m3 == mc || !(m3->mc_flags & C_INITIALIZED)) + continue; + if (m3->mc_pg[0] == mp) { + for (int i = 0; i < mc->mc_db->md_depth; i++) { + m3->mc_pg[i] = m3->mc_pg[i + 1]; + m3->mc_ki[i] = m3->mc_ki[i + 1]; } + m3->mc_snum--; + m3->mc_top--; } } + + mdbx_cassert(mc, IS_LEAF(mc->mc_pg[mc->mc_top]) || + PAGETYPE(mc->mc_pg[mc->mc_top]) == pagetype); + mdbx_cassert(mc, mc->mc_snum < mc->mc_db->md_depth || + IS_LEAF(mc->mc_pg[mc->mc_db->md_depth - 1])); } else { mdbx_debug("root page %" PRIaPGNO " doesn't need rebalancing (flags 0x%x)", @@ -9392,45 +10158,53 @@ static int mdbx_rebalance(MDBX_cursor *mc) { /* The parent (branch page) must have at least 2 pointers, * otherwise the tree is invalid. */ - ptop = mc->mc_top - 1; - mdbx_cassert(mc, NUMKEYS(mc->mc_pg[ptop]) > 1); + const unsigned pre_top = mc->mc_top - 1; + mdbx_cassert(mc, IS_BRANCH(mc->mc_pg[pre_top])); + mdbx_cassert(mc, !IS_SUBP(mc->mc_pg[0])); + mdbx_cassert(mc, NUMKEYS(mc->mc_pg[pre_top]) > 1); /* Leaf page fill factor is below the threshold. * Try to move keys from left or right neighbor, or * merge with a neighbor page. */ /* Find neighbors. */ + MDBX_cursor mn; mdbx_cursor_copy(mc, &mn); mn.mc_xcursor = NULL; - oldki = mc->mc_ki[mc->mc_top]; - if (mc->mc_ki[ptop] == 0) { + indx_t oldki = mc->mc_ki[mc->mc_top]; + bool fromleft; + if (mc->mc_ki[pre_top] == 0) { /* We're the leftmost leaf in our parent. */ mdbx_debug("reading right neighbor"); - mn.mc_ki[ptop]++; - node = NODEPTR(mc->mc_pg[ptop], mn.mc_ki[ptop]); + mn.mc_ki[pre_top]++; + node = NODEPTR(mc->mc_pg[pre_top], mn.mc_ki[pre_top]); rc = mdbx_page_get(mc, NODEPGNO(node), &mn.mc_pg[mn.mc_top], NULL); - if (unlikely(rc)) + if (unlikely(rc != MDBX_SUCCESS)) return rc; + mdbx_cassert(mc, PAGETYPE(mn.mc_pg[mn.mc_top]) == + PAGETYPE(mc->mc_pg[mc->mc_top])); mn.mc_ki[mn.mc_top] = 0; mc->mc_ki[mc->mc_top] = NUMKEYS(mc->mc_pg[mc->mc_top]); - fromleft = 0; + fromleft = false; } else { /* There is at least one neighbor to the left. */ mdbx_debug("reading left neighbor"); - mn.mc_ki[ptop]--; - node = NODEPTR(mc->mc_pg[ptop], mn.mc_ki[ptop]); + mn.mc_ki[pre_top]--; + node = NODEPTR(mc->mc_pg[pre_top], mn.mc_ki[pre_top]); rc = mdbx_page_get(mc, NODEPGNO(node), &mn.mc_pg[mn.mc_top], NULL); - if (unlikely(rc)) + if (unlikely(rc != MDBX_SUCCESS)) return rc; + mdbx_cassert(mc, PAGETYPE(mn.mc_pg[mn.mc_top]) == + PAGETYPE(mc->mc_pg[mc->mc_top])); mn.mc_ki[mn.mc_top] = NUMKEYS(mn.mc_pg[mn.mc_top]) - 1; mc->mc_ki[mc->mc_top] = 0; - fromleft = 1; + fromleft = true; } mdbx_debug("found neighbor page %" PRIaPGNO " (%u keys, %.1f%% full)", mn.mc_pg[mn.mc_top]->mp_pgno, NUMKEYS(mn.mc_pg[mn.mc_top]), - (float)PAGEFILL(mc->mc_txn->mt_env, mn.mc_pg[mn.mc_top]) / 10); + PAGEFILL(mc->mc_txn->mt_env, mn.mc_pg[mn.mc_top]) / 10.24); /* If the neighbor page is above threshold and has enough keys, * move one key from it. Otherwise we should try to merge them. @@ -9438,24 +10212,95 @@ static int mdbx_rebalance(MDBX_cursor *mc) { if (PAGEFILL(mc->mc_txn->mt_env, mn.mc_pg[mn.mc_top]) >= thresh && NUMKEYS(mn.mc_pg[mn.mc_top]) > minkeys) { rc = mdbx_node_move(&mn, mc, fromleft); - if (fromleft) { - /* if we inserted on left, bump position up */ - oldki++; - } + if (unlikely(rc != MDBX_SUCCESS)) + return rc; + oldki += fromleft /* if we inserted on left, bump position up */; + mdbx_cassert(mc, IS_LEAF(mc->mc_pg[mc->mc_top]) || + PAGETYPE(mc->mc_pg[mc->mc_top]) == pagetype); + mdbx_cassert(mc, mc->mc_snum < mc->mc_db->md_depth || + IS_LEAF(mc->mc_pg[mc->mc_db->md_depth - 1])); } else { if (!fromleft) { rc = mdbx_page_merge(&mn, mc); + if (unlikely(rc != MDBX_SUCCESS)) + return rc; + mdbx_cassert(mc, IS_LEAF(mc->mc_pg[mc->mc_top]) || + PAGETYPE(mc->mc_pg[mc->mc_top]) == pagetype); + mdbx_cassert(mc, mc->mc_snum < mc->mc_db->md_depth || + IS_LEAF(mc->mc_pg[mc->mc_db->md_depth - 1])); } else { oldki += NUMKEYS(mn.mc_pg[mn.mc_top]); mn.mc_ki[mn.mc_top] += mc->mc_ki[mn.mc_top] + 1; /* We want mdbx_rebalance to find mn when doing fixups */ WITH_CURSOR_TRACKING(mn, rc = mdbx_page_merge(mc, &mn)); + if (unlikely(rc != MDBX_SUCCESS)) + return rc; mdbx_cursor_copy(&mn, mc); + mdbx_cassert(mc, IS_LEAF(mc->mc_pg[mc->mc_top]) || + PAGETYPE(mc->mc_pg[mc->mc_top]) == pagetype); + mdbx_cassert(mc, mc->mc_snum < mc->mc_db->md_depth || + IS_LEAF(mc->mc_pg[mc->mc_db->md_depth - 1])); } mc->mc_flags &= ~C_EOF; } mc->mc_ki[mc->mc_top] = oldki; - return rc; + return MDBX_SUCCESS; +} + +static __cold int mdbx_cursor_check(MDBX_cursor *mc, bool pending) { + mdbx_cassert(mc, mc->mc_top == mc->mc_snum - 1); + if (unlikely(mc->mc_top != mc->mc_snum - 1)) + return MDBX_CURSOR_FULL; + mdbx_cassert(mc, pending ? mc->mc_snum <= mc->mc_db->md_depth + : mc->mc_snum == mc->mc_db->md_depth); + if (unlikely(pending ? mc->mc_snum > mc->mc_db->md_depth + : mc->mc_snum != mc->mc_db->md_depth)) + return MDBX_CURSOR_FULL; + + for (int n = 0; n < mc->mc_snum; ++n) { + MDBX_page *mp = mc->mc_pg[n]; + const unsigned numkeys = NUMKEYS(mp); + const bool expect_branch = (n < mc->mc_db->md_depth - 1) ? true : false; + const bool expect_nested_leaf = + (n + 1 == mc->mc_db->md_depth - 1) ? true : false; + const bool branch = IS_BRANCH(mp) ? true : false; + mdbx_cassert(mc, branch == expect_branch); + if (unlikely(branch != expect_branch)) + return MDBX_CURSOR_FULL; + if (!pending) { + mdbx_cassert(mc, numkeys > mc->mc_ki[n] || + (!branch && numkeys == mc->mc_ki[n] && + (mc->mc_flags & C_EOF) != 0)); + if (unlikely(numkeys <= mc->mc_ki[n] && + !(!branch && numkeys == mc->mc_ki[n] && + (mc->mc_flags & C_EOF) != 0))) + return MDBX_CURSOR_FULL; + } else { + mdbx_cassert(mc, numkeys + 1 >= mc->mc_ki[n]); + if (unlikely(numkeys + 1 < mc->mc_ki[n])) + return MDBX_CURSOR_FULL; + } + + for (unsigned i = 0; i < numkeys; ++i) { + MDBX_node *node = NODEPTR(mp, i); + if (branch) { + mdbx_cassert(mc, node->mn_flags == 0); + if (unlikely(node->mn_flags != 0)) + return MDBX_CURSOR_FULL; + pgno_t pgno = NODEPGNO(node); + MDBX_page *np; + int rc = mdbx_page_get(mc, pgno, &np, NULL); + mdbx_cassert(mc, rc == MDBX_SUCCESS); + if (unlikely(rc != MDBX_SUCCESS)) + return rc; + const bool nested_leaf = IS_LEAF(np) ? true : false; + mdbx_cassert(mc, nested_leaf == expect_nested_leaf); + if (unlikely(nested_leaf != expect_nested_leaf)) + return MDBX_CURSOR_FULL; + } + } + } + return MDBX_SUCCESS; } /* Complete a delete operation started by mdbx_cursor_del(). */ @@ -9467,6 +10312,7 @@ static int mdbx_cursor_del0(MDBX_cursor *mc) { MDBX_cursor *m2, *m3; MDBX_dbi dbi = mc->mc_dbi; + mdbx_cassert(mc, IS_LEAF(mc->mc_pg[mc->mc_top])); ki = mc->mc_ki[mc->mc_top]; mp = mc->mc_pg[mc->mc_top]; mdbx_node_del(mc, mc->mc_db->md_xsize); @@ -9475,9 +10321,9 @@ static int mdbx_cursor_del0(MDBX_cursor *mc) { /* Adjust other cursors pointing to mp */ for (m2 = mc->mc_txn->mt_cursors[dbi]; m2; m2 = m2->mc_next) { m3 = (mc->mc_flags & C_SUB) ? &m2->mc_xcursor->mx_cursor : m2; - if (!(m2->mc_flags & m3->mc_flags & C_INITIALIZED)) + if (m3 == mc || !(m2->mc_flags & m3->mc_flags & C_INITIALIZED)) continue; - if (m3 == mc || m3->mc_snum < mc->mc_snum) + if (m3->mc_snum < mc->mc_snum) continue; if (m3->mc_pg[mc->mc_top] == mp) { if (m3->mc_ki[mc->mc_top] == ki) { @@ -9508,32 +10354,35 @@ static int mdbx_cursor_del0(MDBX_cursor *mc) { return rc; } + ki = mc->mc_ki[mc->mc_top]; mp = mc->mc_pg[mc->mc_top]; + mdbx_cassert(mc, IS_LEAF(mc->mc_pg[mc->mc_top])); nkeys = NUMKEYS(mp); mdbx_cassert(mc, (mc->mc_db->md_entries > 0 && nkeys > 0) || ((mc->mc_flags & C_SUB) && mc->mc_db->md_entries == 0 && nkeys == 0)); - /* Adjust other cursors pointing to mp */ - for (m2 = mc->mc_txn->mt_cursors[dbi]; !rc && m2; m2 = m2->mc_next) { + /* Adjust THIS and other cursors pointing to mp */ + for (m2 = mc->mc_txn->mt_cursors[dbi]; m2; m2 = m2->mc_next) { m3 = (mc->mc_flags & C_SUB) ? &m2->mc_xcursor->mx_cursor : m2; - if (!(m2->mc_flags & m3->mc_flags & C_INITIALIZED)) + if (m3 == mc || !(m2->mc_flags & m3->mc_flags & C_INITIALIZED)) continue; if (m3->mc_snum < mc->mc_snum) continue; if (m3->mc_pg[mc->mc_top] == mp) { /* if m3 points past last node in page, find next sibling */ - if (m3->mc_ki[mc->mc_top] >= mc->mc_ki[mc->mc_top]) { - if (m3->mc_ki[mc->mc_top] >= nkeys) { - rc = mdbx_cursor_sibling(m3, 1); - if (rc == MDBX_NOTFOUND) { - m3->mc_flags |= C_EOF; - rc = MDBX_SUCCESS; - continue; - } else if (unlikely(rc != MDBX_SUCCESS)) - break; - } - if (mc->mc_db->md_flags & MDBX_DUPSORT) { + if (m3->mc_ki[mc->mc_top] >= nkeys) { + rc = mdbx_cursor_sibling(m3, true); + if (rc == MDBX_NOTFOUND) { + m3->mc_flags |= C_EOF; + rc = MDBX_SUCCESS; + continue; + } else if (unlikely(rc != MDBX_SUCCESS)) + break; + } + if (m3->mc_ki[mc->mc_top] >= ki || m3->mc_pg[mc->mc_top] != mp) { + if ((mc->mc_db->md_flags & MDBX_DUPSORT) != 0 && + (m3->mc_flags & C_EOF) == 0) { MDBX_node *node = NODEPTR(m3->mc_pg[m3->mc_top], m3->mc_ki[m3->mc_top]); /* If this node has dupdata, it may need to be reinited @@ -9546,19 +10395,49 @@ static int mdbx_cursor_del0(MDBX_cursor *mc) { m3->mc_xcursor->mx_cursor.mc_pg[0] = NODEDATA(node); } else { rc = mdbx_xcursor_init1(m3, node); - if (likely(rc == MDBX_SUCCESS)) - m3->mc_xcursor->mx_cursor.mc_flags |= C_DEL; + if (unlikely(rc != MDBX_SUCCESS)) + break; + m3->mc_xcursor->mx_cursor.mc_flags |= C_DEL; } } } } } } + + if (mc->mc_ki[mc->mc_top] >= nkeys) { + rc = mdbx_cursor_sibling(mc, true); + if (rc == MDBX_NOTFOUND) { + mc->mc_flags |= C_EOF; + rc = MDBX_SUCCESS; + } + } + if ((mc->mc_db->md_flags & MDBX_DUPSORT) != 0 && + (mc->mc_flags & C_EOF) == 0) { + MDBX_node *node = NODEPTR(mc->mc_pg[mc->mc_top], mc->mc_ki[mc->mc_top]); + /* If this node has dupdata, it may need to be reinited + * because its data has moved. + * If the xcursor was not initd it must be reinited. + * Else if node points to a subDB, nothing is needed. */ + if (node->mn_flags & F_DUPDATA) { + if (mc->mc_xcursor->mx_cursor.mc_flags & C_INITIALIZED) { + if (!(node->mn_flags & F_SUBDATA)) + mc->mc_xcursor->mx_cursor.mc_pg[0] = NODEDATA(node); + } else { + rc = mdbx_xcursor_init1(mc, node); + if (likely(rc != MDBX_SUCCESS)) + mc->mc_xcursor->mx_cursor.mc_flags |= C_DEL; + } + } + } mc->mc_flags |= C_DEL; } if (unlikely(rc)) mc->mc_txn->mt_flags |= MDBX_TXN_ERROR; + else if (mdbx_audit_enabled()) + rc = mdbx_cursor_check(mc, false); + return rc; } @@ -9583,8 +10462,7 @@ int mdbx_del(MDBX_txn *txn, MDBX_dbi dbi, MDBX_val *key, MDBX_val *data) { static int mdbx_del0(MDBX_txn *txn, MDBX_dbi dbi, MDBX_val *key, MDBX_val *data, unsigned flags) { - MDBX_cursor mc; - MDBX_xcursor mx; + MDBX_cursor_couple cx; MDBX_cursor_op op; MDBX_val rdata; int rc, exact = 0; @@ -9593,7 +10471,7 @@ static int mdbx_del0(MDBX_txn *txn, MDBX_dbi dbi, MDBX_val *key, MDBX_val *data, mdbx_debug("====> delete db %u key [%s], data [%s]", dbi, DKEY(key), DVAL(data)); - rc = mdbx_cursor_init(&mc, txn, dbi, &mx); + rc = mdbx_cursor_init(&cx.outer, txn, dbi); if (unlikely(rc != MDBX_SUCCESS)) return rc; @@ -9605,7 +10483,7 @@ static int mdbx_del0(MDBX_txn *txn, MDBX_dbi dbi, MDBX_val *key, MDBX_val *data, op = MDBX_SET; flags |= MDBX_NODUPDATA; } - rc = mdbx_cursor_set(&mc, key, data, op, &exact); + rc = mdbx_cursor_set(&cx.outer, key, data, op, &exact); if (likely(rc == MDBX_SUCCESS)) { /* let mdbx_page_split know about this cursor if needed: * delete will trigger a rebalance; if it needs to move @@ -9614,10 +10492,10 @@ static int mdbx_del0(MDBX_txn *txn, MDBX_dbi dbi, MDBX_val *key, MDBX_val *data, * is larger than the current one, the parent page may * run out of space, triggering a split. We need this * cursor to be consistent until the end of the rebalance. */ - mc.mc_next = txn->mt_cursors[dbi]; - txn->mt_cursors[dbi] = &mc; - rc = mdbx_cursor_del(&mc, flags); - txn->mt_cursors[dbi] = mc.mc_next; + cx.outer.mc_next = txn->mt_cursors[dbi]; + txn->mt_cursors[dbi] = &cx.outer; + rc = mdbx_cursor_del(&cx.outer, flags); + txn->mt_cursors[dbi] = cx.outer.mc_next; } return rc; } @@ -9632,15 +10510,15 @@ static int mdbx_del0(MDBX_txn *txn, MDBX_dbi dbi, MDBX_val *key, MDBX_val *data, * [in] newpgno The page number, if the new node is a branch node. * [in] nflags The NODE_ADD_FLAGS for the new node. * Returns 0 on success, non-zero on failure. */ -static int mdbx_page_split(MDBX_cursor *mc, MDBX_val *newkey, MDBX_val *newdata, - pgno_t newpgno, unsigned nflags) { +static int mdbx_page_split(MDBX_cursor *mc, const MDBX_val *newkey, + MDBX_val *newdata, pgno_t newpgno, unsigned nflags) { unsigned flags; - int rc = MDBX_SUCCESS, new_root = 0, did_split = 0; + int rc = MDBX_SUCCESS, foliage = 0, did_split = 0; pgno_t pgno = 0; unsigned i, ptop; MDBX_env *env = mc->mc_txn->mt_env; MDBX_node *node; - MDBX_val sepkey, rkey, xdata, *rdata = &xdata; + MDBX_val sepkey, rkey, xdata; MDBX_page *copy = NULL; MDBX_page *rp, *pp; MDBX_cursor mn; @@ -9649,6 +10527,11 @@ static int mdbx_page_split(MDBX_cursor *mc, MDBX_val *newkey, MDBX_val *newdata, MDBX_page *mp = mc->mc_pg[mc->mc_top]; unsigned newindx = mc->mc_ki[mc->mc_top]; unsigned nkeys = NUMKEYS(mp); + if (mdbx_audit_enabled()) { + int err = mdbx_cursor_check(mc, true); + if (unlikely(err != MDBX_SUCCESS)) + return err; + } mdbx_debug("-----> splitting %s page %" PRIaPGNO " and adding [%s] at index %i/%i", @@ -9669,18 +10552,19 @@ static int mdbx_page_split(MDBX_cursor *mc, MDBX_val *newkey, MDBX_val *newdata, if ((rc = mdbx_page_new(mc, P_BRANCH, 1, &pp))) goto done; /* shift current top to make room for new parent */ - for (i = mc->mc_snum; i > 0; i--) { - mc->mc_pg[i] = mc->mc_pg[i - 1]; - mc->mc_ki[i] = mc->mc_ki[i - 1]; - } + mdbx_cassert(mc, mc->mc_snum < 2 && mc->mc_db->md_depth > 0); + mc->mc_pg[2] = mc->mc_pg[1]; + mc->mc_ki[2] = mc->mc_ki[1]; + mc->mc_pg[1] = mc->mc_pg[0]; + mc->mc_ki[1] = mc->mc_ki[0]; mc->mc_pg[0] = pp; mc->mc_ki[0] = 0; mc->mc_db->md_root = pp->mp_pgno; mdbx_debug("root split! new root = %" PRIaPGNO "", pp->mp_pgno); - new_root = mc->mc_db->md_depth++; + foliage = mc->mc_db->md_depth++; /* Add left (implicit) pointer. */ - if (unlikely((rc = mdbx_node_add(mc, 0, NULL, NULL, mp->mp_pgno, 0)) != + if (unlikely((rc = mdbx_node_add_branch(mc, 0, NULL, mp->mp_pgno)) != MDBX_SUCCESS)) { /* undo the pre-push */ mc->mc_pg[0] = mc->mc_pg[1]; @@ -9700,6 +10584,7 @@ static int mdbx_page_split(MDBX_cursor *mc, MDBX_val *newkey, MDBX_val *newdata, mdbx_cursor_copy(mc, &mn); mn.mc_xcursor = NULL; mn.mc_pg[mn.mc_top] = rp; + mn.mc_ki[mn.mc_top] = 0; mn.mc_ki[ptop] = mc->mc_ki[ptop] + 1; unsigned split_indx; @@ -9710,7 +10595,6 @@ static int mdbx_page_split(MDBX_cursor *mc, MDBX_val *newkey, MDBX_val *newdata, nkeys = 0; } else { split_indx = (nkeys + 1) / 2; - if (IS_LEAF2(rp)) { char *split, *ins; int x; @@ -9762,12 +10646,9 @@ static int mdbx_page_split(MDBX_cursor *mc, MDBX_val *newkey, MDBX_val *newdata, } else { size_t psize, nsize, k; /* Maximum free space in an empty page */ - unsigned pmax = env->me_psize - PAGEHDRSZ; - if (IS_LEAF(mp)) - nsize = mdbx_leaf_size(env, newkey, newdata); - else - nsize = mdbx_branch_size(env, newkey); - nsize = EVEN(nsize); + const unsigned pmax = env->me_psize - PAGEHDRSZ; + nsize = IS_LEAF(mp) ? mdbx_leaf_size(env, newkey, newdata) + : mdbx_branch_size(env, newkey); /* grab a page to hold a temporary copy */ copy = mdbx_page_malloc(mc->mc_txn, 1); @@ -9850,10 +10731,19 @@ static int mdbx_page_split(MDBX_cursor *mc, MDBX_val *newkey, MDBX_val *newdata, } mdbx_debug("separator is %d [%s]", split_indx, DKEY(&sepkey)); + if (mdbx_audit_enabled()) { + int err = mdbx_cursor_check(mc, true); + if (unlikely(err != MDBX_SUCCESS)) + return err; + err = mdbx_cursor_check(&mn, true); + if (unlikely(err != MDBX_SUCCESS)) + return err; + } /* Copy separator key to the parent. */ if (SIZELEFT(mn.mc_pg[ptop]) < mdbx_branch_size(env, &sepkey)) { - int snum = mc->mc_snum; + const int snum = mc->mc_snum; + const int depth = mc->mc_db->md_depth; mn.mc_snum--; mn.mc_top--; did_split = 1; @@ -9862,10 +10752,15 @@ static int mdbx_page_split(MDBX_cursor *mc, MDBX_val *newkey, MDBX_val *newdata, mn, rc = mdbx_page_split(&mn, &sepkey, NULL, rp->mp_pgno, 0)); if (unlikely(rc != MDBX_SUCCESS)) goto done; + mdbx_cassert(mc, mc->mc_snum - snum == mc->mc_db->md_depth - depth); + if (mdbx_audit_enabled()) { + int err = mdbx_cursor_check(mc, true); + if (unlikely(err != MDBX_SUCCESS)) + return err; + } /* root split? */ - if (mc->mc_snum > snum) - ptop++; + ptop += mc->mc_snum - snum; /* Right page might now have changed parent. * Check if left page also changed parent. */ @@ -9881,12 +10776,12 @@ static int mdbx_page_split(MDBX_cursor *mc, MDBX_val *newkey, MDBX_val *newdata, } else { /* find right page's left sibling */ mc->mc_ki[ptop] = mn.mc_ki[ptop]; - rc = mdbx_cursor_sibling(mc, 0); + rc = mdbx_cursor_sibling(mc, false); } } } else { mn.mc_top--; - rc = mdbx_node_add(&mn, mn.mc_ki[ptop], &sepkey, NULL, rp->mp_pgno, 0); + rc = mdbx_node_add_branch(&mn, mn.mc_ki[ptop], &sepkey, rp->mp_pgno); mn.mc_top++; } if (unlikely(rc != MDBX_SUCCESS)) { @@ -9896,10 +10791,27 @@ static int mdbx_page_split(MDBX_cursor *mc, MDBX_val *newkey, MDBX_val *newdata, } goto done; } + if (nflags & MDBX_APPEND) { mc->mc_pg[mc->mc_top] = rp; mc->mc_ki[mc->mc_top] = 0; - rc = mdbx_node_add(mc, 0, newkey, newdata, newpgno, nflags); + switch (PAGETYPE(rp)) { + case P_BRANCH: { + mdbx_cassert(mc, nflags == 0); + rc = mdbx_node_add_branch(mc, 0, newkey, newpgno); + } break; + case P_LEAF: { + mdbx_cassert(mc, newpgno == 0); + rc = mdbx_node_add_leaf(mc, 0, newkey, newdata, nflags); + } break; + case P_LEAF | P_LEAF2: { + mdbx_cassert(mc, nflags == 0); + mdbx_cassert(mc, newpgno == 0); + rc = mdbx_node_add_leaf2(mc, 0, newkey); + } break; + default: + rc = MDBX_CORRUPTED; + } if (rc) goto done; for (i = 0; i < mc->mc_top; i++) @@ -9910,6 +10822,7 @@ static int mdbx_page_split(MDBX_cursor *mc, MDBX_val *newkey, MDBX_val *newdata, i = split_indx; indx_t n = 0; do { + MDBX_val *rdata = NULL; if (i == newindx) { rkey.iov_base = newkey->iov_base; rkey.iov_len = newkey->iov_len; @@ -9933,14 +10846,30 @@ static int mdbx_page_split(MDBX_cursor *mc, MDBX_val *newkey, MDBX_val *newdata, flags = node->mn_flags; } - if (!IS_LEAF(mp) && n == 0) { - /* First branch index doesn't need key data. */ - rkey.iov_len = 0; + switch (PAGETYPE(rp)) { + case P_BRANCH: { + mdbx_cassert(mc, 0 == (uint16_t)flags); + if (n == 0) { + /* First branch index doesn't need key data. */ + rkey.iov_len = 0; + } + rc = mdbx_node_add_branch(mc, n, &rkey, pgno); + } break; + case P_LEAF: { + mdbx_cassert(mc, pgno == 0); + rc = mdbx_node_add_leaf(mc, n, &rkey, rdata, flags); + } break; + /* case P_LEAF | P_LEAF2: { + mdbx_cassert(mc, 0 == (uint16_t)flags); + mdbx_cassert(mc, gno == 0); + rc = mdbx_node_add_leaf2(mc, n, &rkey); + } break; */ + default: + rc = MDBX_CORRUPTED; } - - rc = mdbx_node_add(mc, n, &rkey, rdata, pgno, flags); if (rc) goto done; + if (i == nkeys) { i = 0; n = 0; @@ -10001,29 +10930,22 @@ static int mdbx_page_split(MDBX_cursor *mc, MDBX_val *newkey, MDBX_val *newdata, nkeys = NUMKEYS(mp); for (m2 = mc->mc_txn->mt_cursors[dbi]; m2; m2 = m2->mc_next) { - if (mc->mc_flags & C_SUB) - m3 = &m2->mc_xcursor->mx_cursor; - else - m3 = m2; + m3 = (mc->mc_flags & C_SUB) ? &m2->mc_xcursor->mx_cursor : m2; if (m3 == mc) continue; if (!(m2->mc_flags & m3->mc_flags & C_INITIALIZED)) continue; - if (new_root) { + if (foliage) { int k; /* sub cursors may be on different DB */ if (m3->mc_pg[0] != mp) continue; /* root split */ - for (k = new_root; k >= 0; k--) { + for (k = foliage; k >= 0; k--) { m3->mc_ki[k + 1] = m3->mc_ki[k]; m3->mc_pg[k + 1] = m3->mc_pg[k]; } - if (m3->mc_ki[0] >= nkeys) { - m3->mc_ki[0] = 1; - } else { - m3->mc_ki[0] = 0; - } + m3->mc_ki[0] = (m3->mc_ki[0] >= nkeys) ? 1 : 0; m3->mc_pg[0] = mc->mc_pg[0]; m3->mc_snum++; m3->mc_top++; @@ -10053,7 +10975,7 @@ static int mdbx_page_split(MDBX_cursor *mc, MDBX_val *newkey, MDBX_val *newdata, done: if (copy) /* tmp page */ - mdbx_page_free(env, copy); + mdbx_dpage_free(env, copy, 1); if (unlikely(rc)) mc->mc_txn->mt_flags |= MDBX_TXN_ERROR; return rc; @@ -10061,8 +10983,6 @@ done: int mdbx_put(MDBX_txn *txn, MDBX_dbi dbi, MDBX_val *key, MDBX_val *data, unsigned flags) { - MDBX_cursor mc; - MDBX_xcursor mx; if (unlikely(!key || !data || !txn)) return MDBX_EINVAL; @@ -10083,30 +11003,32 @@ int mdbx_put(MDBX_txn *txn, MDBX_dbi dbi, MDBX_val *key, MDBX_val *data, if (unlikely(txn->mt_flags & (MDBX_TXN_RDONLY | MDBX_TXN_BLOCKED))) return (txn->mt_flags & MDBX_TXN_RDONLY) ? MDBX_EACCESS : MDBX_BAD_TXN; - int rc = mdbx_cursor_init(&mc, txn, dbi, &mx); + MDBX_cursor_couple cx; + int rc = mdbx_cursor_init(&cx.outer, txn, dbi); if (unlikely(rc != MDBX_SUCCESS)) return rc; - mc.mc_next = txn->mt_cursors[dbi]; - txn->mt_cursors[dbi] = &mc; + cx.outer.mc_next = txn->mt_cursors[dbi]; + txn->mt_cursors[dbi] = &cx.outer; /* LY: support for update (explicit overwrite) */ if (flags & MDBX_CURRENT) { - rc = mdbx_cursor_get(&mc, key, NULL, MDBX_SET); + rc = mdbx_cursor_get(&cx.outer, key, NULL, MDBX_SET); if (likely(rc == MDBX_SUCCESS) && (txn->mt_dbs[dbi].md_flags & MDBX_DUPSORT)) { /* LY: allows update (explicit overwrite) only for unique keys */ - MDBX_node *leaf = NODEPTR(mc.mc_pg[mc.mc_top], mc.mc_ki[mc.mc_top]); + MDBX_node *leaf = NODEPTR(cx.outer.mc_pg[cx.outer.mc_top], + cx.outer.mc_ki[cx.outer.mc_top]); if (F_ISSET(leaf->mn_flags, F_DUPDATA)) { - mdbx_tassert(txn, XCURSOR_INITED(&mc) && - mc.mc_xcursor->mx_db.md_entries > 1); + mdbx_tassert(txn, XCURSOR_INITED(&cx.outer) && + cx.outer.mc_xcursor->mx_db.md_entries > 1); rc = MDBX_EMULTIVAL; } } } if (likely(rc == MDBX_SUCCESS)) - rc = mdbx_cursor_put(&mc, key, data, flags); - txn->mt_cursors[dbi] = mc.mc_next; + rc = mdbx_cursor_put(&cx.outer, key, data, flags); + txn->mt_cursors[dbi] = cx.outer.mc_next; return rc; } @@ -10416,7 +11338,7 @@ static int __cold mdbx_env_compact(MDBX_env *env, mdbx_filehandle_t fd) { MDBX_cursor mc; MDBX_val key, data; - rc = mdbx_cursor_init(&mc, txn, FREE_DBI, NULL); + rc = mdbx_cursor_init(&mc, txn, FREE_DBI); if (unlikely(rc != MDBX_SUCCESS)) return rc; while ((rc = mdbx_cursor_get(&mc, &key, &data, MDBX_NEXT)) == 0) @@ -10742,7 +11664,7 @@ static MDBX_cmp_func *mdbx_default_keycmp(unsigned flags) { static MDBX_cmp_func *mdbx_default_datacmp(unsigned flags) { return !(flags & MDBX_DUPSORT) - ? 0 + ? mdbx_cmp_memn : ((flags & MDBX_INTEGERDUP) ? mdbx_cmp_int_ua : ((flags & MDBX_REVERSEDUP) ? mdbx_cmp_memnr @@ -10854,7 +11776,7 @@ int mdbx_dbi_open_ex(MDBX_txn *txn, const char *table_name, unsigned user_flags, key.iov_len = len; key.iov_base = (void *)table_name; MDBX_cursor mc; - int rc = mdbx_cursor_init(&mc, txn, MAIN_DBI, NULL); + int rc = mdbx_cursor_init(&mc, txn, MAIN_DBI); if (unlikely(rc != MDBX_SUCCESS)) return rc; rc = mdbx_cursor_set(&mc, &key, &data, MDBX_SET, &exact); @@ -10914,10 +11836,10 @@ int mdbx_dbi_open_ex(MDBX_txn *txn, const char *table_name, unsigned user_flags, } unsigned dbflag = DB_FRESH | DB_VALID | DB_USRVALID; + MDBX_db db_dummy; if (unlikely(rc)) { /* MDBX_NOTFOUND and MDBX_CREATE: Create new DB */ assert(rc == MDBX_NOTFOUND); - MDBX_db db_dummy; memset(&db_dummy, 0, sizeof(db_dummy)); db_dummy.md_root = P_INVALID; db_dummy.md_flags = user_flags & PERSISTENT_FLAGS; @@ -10990,10 +11912,9 @@ int __cold mdbx_dbi_stat(MDBX_txn *txn, MDBX_dbi dbi, MDBX_stat *arg, return MDBX_BAD_TXN; if (unlikely(txn->mt_dbflags[dbi] & DB_STALE)) { - MDBX_cursor mc; - MDBX_xcursor mx; + MDBX_cursor_couple cx; /* Stale, must read the DB's root. cursor_init does it for us. */ - int rc = mdbx_cursor_init(&mc, txn, dbi, &mx); + int rc = mdbx_cursor_init(&cx.outer, txn, dbi); if (unlikely(rc != MDBX_SUCCESS)) return rc; } @@ -11060,9 +11981,7 @@ int mdbx_dbi_flags(MDBX_txn *txn, MDBX_dbi dbi, unsigned *flags) { * [in] subs non-Zero to check for sub-DBs in this DB. * Returns 0 on success, non-zero on failure. */ static int mdbx_drop0(MDBX_cursor *mc, int subs) { - int rc; - - rc = mdbx_page_search(mc, NULL, MDBX_PS_FIRST); + int rc = mdbx_page_search(mc, NULL, MDBX_PS_FIRST); if (likely(rc == MDBX_SUCCESS)) { MDBX_txn *txn = mc->mc_txn; MDBX_node *ni; @@ -11073,7 +11992,14 @@ static int mdbx_drop0(MDBX_cursor *mc, int subs) { * This also avoids any P_LEAF2 pages, which have no nodes. * Also if the DB doesn't have sub-DBs and has no overflow * pages, omit scanning leaves. */ - if ((mc->mc_flags & C_SUB) || (!subs && !mc->mc_db->md_overflow_pages)) + + if (mc->mc_flags & C_SUB) { + MDBX_db *outer = mdbx_outer_db(mc); + outer->md_branch_pages -= mc->mc_db->md_branch_pages; + outer->md_leaf_pages -= mc->mc_db->md_leaf_pages; + outer->md_overflow_pages -= mc->mc_db->md_overflow_pages; + mdbx_cursor_pop(mc); + } else if (!subs && !mc->mc_db->md_overflow_pages) mdbx_cursor_pop(mc); mdbx_cursor_copy(mc, &mx); @@ -11091,11 +12017,9 @@ static int mdbx_drop0(MDBX_cursor *mc, int subs) { if (unlikely(rc)) goto done; mdbx_cassert(mc, IS_OVERFLOW(omp)); - rc = - mdbx_pnl_append_range(&txn->mt_befree_pages, pg, omp->mp_pages); + rc = mdbx_page_befree(mc, omp); if (unlikely(rc)) goto done; - mc->mc_db->md_overflow_pages -= omp->mp_pages; if (!mc->mc_db->md_overflow_pages && !subs) break; } else if (subs && (ni->mn_flags & F_SUBDATA)) { @@ -11482,7 +12406,7 @@ static txnid_t __cold mdbx_oomkick(MDBX_env *env, const txnid_t laggard) { txnid_t oldest = mdbx_reclaiming_detent(env); mdbx_assert(env, oldest < env->me_txn0->mt_txnid); mdbx_assert(env, oldest >= laggard); - mdbx_assert(env, oldest >= env->me_oldest[0]); + mdbx_assert(env, oldest >= *env->me_oldest); if (oldest == laggard || unlikely(env->me_lck == NULL /* exclusive mode */)) return oldest; @@ -11510,9 +12434,9 @@ static txnid_t __cold mdbx_oomkick(MDBX_env *env, const txnid_t laggard) { (gap < UINT_MAX) ? (unsigned)gap : UINT_MAX, -retry); } mdbx_notice("oom-kick: update oldest %" PRIaTXN " -> %" PRIaTXN, - env->me_oldest[0], oldest); - mdbx_assert(env, env->me_oldest[0] <= oldest); - return env->me_oldest[0] = oldest; + *env->me_oldest, oldest); + mdbx_assert(env, *env->me_oldest <= oldest); + return *env->me_oldest = oldest; } mdbx_tid_t tid; @@ -11627,13 +12551,8 @@ typedef struct mdbx_walk_ctx { /* Depth-first tree traversal. */ static int __cold mdbx_env_walk(mdbx_walk_ctx_t *ctx, const char *dbi, - pgno_t pg, int deep) { - MDBX_page *mp; - int rc, i, nkeys; - size_t header_size, unused_size, payload_size, align_bytes; - const char *type; - - if (pg == P_INVALID) + pgno_t pgno, int deep) { + if (pgno == P_INVALID) return MDBX_SUCCESS; /* empty db */ MDBX_cursor mc; @@ -11641,116 +12560,169 @@ static int __cold mdbx_env_walk(mdbx_walk_ctx_t *ctx, const char *dbi, mc.mc_snum = 1; mc.mc_txn = ctx->mw_txn; - rc = mdbx_page_get(&mc, pg, &mp, NULL); + MDBX_page *mp; + int rc = mdbx_page_get(&mc, pgno, &mp, NULL); if (rc) return rc; - if (pg != mp->mp_pgno) - return MDBX_CORRUPTED; - nkeys = NUMKEYS(mp); - header_size = IS_LEAF2(mp) ? PAGEHDRSZ : PAGEHDRSZ + mp->mp_lower; - unused_size = SIZELEFT(mp); - payload_size = 0; + const int nkeys = NUMKEYS(mp); + size_t header_size = IS_LEAF2(mp) ? PAGEHDRSZ : PAGEHDRSZ + mp->mp_lower; + size_t unused_size = SIZELEFT(mp); + size_t payload_size = 0; + size_t align_bytes = 0; + MDBX_page_type_t type; /* LY: Don't use mask here, e.g bitwise * (P_BRANCH|P_LEAF|P_LEAF2|P_META|P_OVERFLOW|P_SUBP). * Pages should not me marked dirty/loose or otherwise. */ switch (mp->mp_flags) { case P_BRANCH: - type = "branch"; - if (nkeys < 1) + type = MDBX_page_branch; + if (nkeys < 2) return MDBX_CORRUPTED; break; case P_LEAF: - type = "leaf"; - break; - case P_LEAF | P_SUBP: - type = "dupsort-subleaf"; + type = MDBX_page_leaf; break; case P_LEAF | P_LEAF2: - type = "dupfixed-leaf"; - break; - case P_LEAF | P_LEAF2 | P_SUBP: - type = "dupsort-dupfixed-subleaf"; + type = MDBX_page_dupfixed_leaf; break; - case P_META: - case P_OVERFLOW: - __fallthrough; default: return MDBX_CORRUPTED; } - for (align_bytes = i = 0; i < nkeys; + for (int i = 0; i < nkeys; align_bytes += ((payload_size + align_bytes) & 1), i++) { - MDBX_node *node; - - if (IS_LEAF2(mp)) { + if (type == MDBX_page_dupfixed_leaf) { /* LEAF2 pages have no mp_ptrs[] or node headers */ payload_size += mp->mp_leaf2_ksize; continue; } - node = NODEPTR(mp, i); - payload_size += NODESIZE + node->mn_ksize; + MDBX_node *node = NODEPTR(mp, i); + payload_size += NODESIZE + NODEKSZ(node); - if (IS_BRANCH(mp)) { + if (type == MDBX_page_branch) { rc = mdbx_env_walk(ctx, dbi, NODEPGNO(node), deep); if (rc) return rc; continue; } - assert(IS_LEAF(mp)); - if (node->mn_flags & F_BIGDATA) { - MDBX_page *omp; - pgno_t *opg; - size_t over_header, over_payload, over_unused; + assert(type == MDBX_page_leaf); + switch (node->mn_flags) { + case 0 /* usual node */: { + payload_size += NODEDSZ(node); + } break; + case F_BIGDATA /* long data on the large/overflow page */: { payload_size += sizeof(pgno_t); - opg = NODEDATA(node); - rc = mdbx_page_get(&mc, *opg, &omp, NULL); + + MDBX_page *op; + pgno_t large_pgno; + memcpy(&large_pgno, NODEDATA(node), sizeof(pgno_t)); + rc = mdbx_page_get(&mc, large_pgno, &op, NULL); if (rc) return rc; - if (*opg != omp->mp_pgno) - return MDBX_CORRUPTED; + /* LY: Don't use mask here, e.g bitwise * (P_BRANCH|P_LEAF|P_LEAF2|P_META|P_OVERFLOW|P_SUBP). * Pages should not me marked dirty/loose or otherwise. */ - if (P_OVERFLOW != omp->mp_flags) + if (P_OVERFLOW != op->mp_flags) return MDBX_CORRUPTED; - over_header = PAGEHDRSZ; - over_payload = NODEDSZ(node); - over_unused = pgno2bytes(ctx->mw_txn->mt_env, omp->mp_pages) - - over_payload - over_header; + const size_t over_header = PAGEHDRSZ; + const size_t over_payload = NODEDSZ(node); + const size_t over_unused = pgno2bytes(ctx->mw_txn->mt_env, op->mp_pages) - + over_payload - over_header; - rc = ctx->mw_visitor(*opg, omp->mp_pages, ctx->mw_user, dbi, - "overflow-data", 1, over_payload, over_header, + rc = ctx->mw_visitor(large_pgno, op->mp_pages, ctx->mw_user, deep, dbi, + pgno2bytes(ctx->mw_txn->mt_env, op->mp_pages), + MDBX_page_large, 1, over_payload, over_header, over_unused); - if (rc) - return rc; - continue; - } + } break; + + case F_SUBDATA /* sub-db */: { + const size_t namelen = NODEKSZ(node); + if (namelen == 0 || NODEDSZ(node) != sizeof(MDBX_db)) + return MDBX_CORRUPTED; + payload_size += sizeof(MDBX_db); + + MDBX_db db; + memcpy(&db, NODEDATA(node), sizeof(db)); + char *name = memcpy(alloca(namelen + 1), NODEKEY(node), namelen); + name[namelen] = 0; + rc = mdbx_env_walk(ctx, name, db.md_root, deep + 1); + } break; + + case F_SUBDATA | F_DUPDATA /* dupsorted sub-tree */: { + if (NODEDSZ(node) != sizeof(MDBX_db)) + return MDBX_CORRUPTED; + payload_size += sizeof(MDBX_db); + + MDBX_db db; + memcpy(&db, NODEDATA(node), sizeof(db)); + rc = mdbx_env_walk(ctx, dbi, db.md_root, deep + 1); + } break; + + case F_DUPDATA /* short sub-page */: { + if (NODEDSZ(node) < PAGEHDRSZ) + return MDBX_CORRUPTED; - payload_size += NODEDSZ(node); - if (node->mn_flags & F_SUBDATA) { - MDBX_db *db = NODEDATA(node); - char *name = NULL; + MDBX_page *sp = NODEDATA(node); + const int nsubkeys = NUMKEYS(sp); + size_t subheader_size = + IS_LEAF2(sp) ? PAGEHDRSZ : PAGEHDRSZ + sp->mp_lower; + size_t subunused_size = SIZELEFT(sp); + size_t subpayload_size = 0; + size_t subalign_bytes = 0; + MDBX_page_type_t subtype; + + switch (sp->mp_flags & ~P_DIRTY /* ignore for sub-pages */) { + case P_LEAF | P_SUBP: + subtype = MDBX_subpage_leaf; + break; + case P_LEAF | P_LEAF2 | P_SUBP: + subtype = MDBX_subpage_dupfixed_leaf; + break; + default: + return MDBX_CORRUPTED; + } + + for (int j = 0; j < nsubkeys; + subalign_bytes += ((subpayload_size + subalign_bytes) & 1), j++) { - if (!(node->mn_flags & F_DUPDATA)) { - name = NODEKEY(node); - ptrdiff_t namelen = (char *)db - name; - name = memcpy(alloca(namelen + 1), name, namelen); - name[namelen] = 0; + if (subtype == MDBX_subpage_dupfixed_leaf) { + /* LEAF2 pages have no mp_ptrs[] or node headers */ + subpayload_size += sp->mp_leaf2_ksize; + } else { + assert(subtype == MDBX_subpage_leaf); + MDBX_node *subnode = NODEPTR(sp, j); + subpayload_size += NODESIZE + NODEKSZ(subnode) + NODEDSZ(subnode); + if (subnode->mn_flags != 0) + return MDBX_CORRUPTED; + } } - rc = mdbx_env_walk(ctx, (name && name[0]) ? name : dbi, db->md_root, - deep + 1); - if (rc) - return rc; + + rc = ctx->mw_visitor(pgno, 0, ctx->mw_user, deep + 1, dbi, NODEDSZ(node), + subtype, nsubkeys, subpayload_size, subheader_size, + subunused_size + subalign_bytes); + header_size += subheader_size; + unused_size += subunused_size; + payload_size += subpayload_size; + align_bytes += subalign_bytes; + } break; + + default: + return MDBX_CORRUPTED; } + + if (unlikely(rc)) + return rc; } - return ctx->mw_visitor(mp->mp_pgno, 1, ctx->mw_user, dbi, type, nkeys, + return ctx->mw_visitor(mp->mp_pgno, 1, ctx->mw_user, deep, dbi, + ctx->mw_txn->mt_env->me_psize, type, nkeys, payload_size, header_size, unused_size + align_bytes); } @@ -11770,16 +12742,18 @@ int __cold mdbx_env_pgwalk(MDBX_txn *txn, MDBX_pgvisitor_func *visitor, ctx.mw_user = user; ctx.mw_visitor = visitor; - int rc = visitor(0, NUM_METAS, user, "meta", "meta", NUM_METAS, - sizeof(MDBX_meta) * NUM_METAS, PAGEHDRSZ * NUM_METAS, - (txn->mt_env->me_psize - sizeof(MDBX_meta) - PAGEHDRSZ) * - NUM_METAS); + int rc = visitor( + 0, NUM_METAS, user, -2, "@META", pgno2bytes(txn->mt_env, NUM_METAS), + MDBX_page_meta, NUM_METAS, sizeof(MDBX_meta) * NUM_METAS, + PAGEHDRSZ * NUM_METAS, + (txn->mt_env->me_psize - sizeof(MDBX_meta) - PAGEHDRSZ) * NUM_METAS); if (!rc) - rc = mdbx_env_walk(&ctx, "free", txn->mt_dbs[FREE_DBI].md_root, 0); + rc = mdbx_env_walk(&ctx, "@GC", txn->mt_dbs[FREE_DBI].md_root, -1); if (!rc) - rc = mdbx_env_walk(&ctx, "main", txn->mt_dbs[MAIN_DBI].md_root, 0); + rc = mdbx_env_walk(&ctx, "@MAIN", txn->mt_dbs[MAIN_DBI].md_root, 0); if (!rc) - rc = visitor(P_INVALID, 0, user, NULL, NULL, 0, 0, 0, 0); + rc = visitor(P_INVALID, 0, user, INT_MIN, NULL, 0, MDBX_page_void, 0, 0, 0, + 0); return rc; } @@ -11944,13 +12918,12 @@ int mdbx_replace(MDBX_txn *txn, MDBX_dbi dbi, MDBX_val *key, MDBX_val *new_data, if (unlikely(txn->mt_flags & (MDBX_TXN_RDONLY | MDBX_TXN_BLOCKED))) return (txn->mt_flags & MDBX_TXN_RDONLY) ? MDBX_EACCESS : MDBX_BAD_TXN; - MDBX_cursor mc; - MDBX_xcursor mx; - int rc = mdbx_cursor_init(&mc, txn, dbi, &mx); + MDBX_cursor_couple cx; + int rc = mdbx_cursor_init(&cx.outer, txn, dbi); if (unlikely(rc != MDBX_SUCCESS)) return rc; - mc.mc_next = txn->mt_cursors[dbi]; - txn->mt_cursors[dbi] = &mc; + cx.outer.mc_next = txn->mt_cursors[dbi]; + txn->mt_cursors[dbi] = &cx.outer; MDBX_val present_key = *key; if (F_ISSET(flags, MDBX_CURRENT | MDBX_NOOVERWRITE)) { @@ -11963,7 +12936,7 @@ int mdbx_replace(MDBX_txn *txn, MDBX_dbi dbi, MDBX_val *key, MDBX_val *new_data, /* убираем лишний бит, он был признаком запрошенного режима */ flags -= MDBX_NOOVERWRITE; - rc = mdbx_cursor_get(&mc, &present_key, old_data, MDBX_GET_BOTH); + rc = mdbx_cursor_get(&cx.outer, &present_key, old_data, MDBX_GET_BOTH); if (rc != MDBX_SUCCESS) goto bailout; @@ -11978,7 +12951,7 @@ int mdbx_replace(MDBX_txn *txn, MDBX_dbi dbi, MDBX_val *key, MDBX_val *new_data, if (unlikely(new_data && old_data->iov_base == new_data->iov_base)) return MDBX_EINVAL; MDBX_val present_data; - rc = mdbx_cursor_get(&mc, &present_key, &present_data, MDBX_SET_KEY); + rc = mdbx_cursor_get(&cx.outer, &present_key, &present_data, MDBX_SET_KEY); if (unlikely(rc != MDBX_SUCCESS)) { old_data->iov_base = NULL; old_data->iov_len = rc; @@ -11989,16 +12962,16 @@ int mdbx_replace(MDBX_txn *txn, MDBX_dbi dbi, MDBX_val *key, MDBX_val *new_data, *old_data = present_data; goto bailout; } else { - MDBX_page *page = mc.mc_pg[mc.mc_top]; + MDBX_page *page = cx.outer.mc_pg[cx.outer.mc_top]; if (txn->mt_dbs[dbi].md_flags & MDBX_DUPSORT) { if (flags & MDBX_CURRENT) { /* для не-уникальных ключей позволяем update/delete только если ключ * один */ - MDBX_node *leaf = NODEPTR(page, mc.mc_ki[mc.mc_top]); + MDBX_node *leaf = NODEPTR(page, cx.outer.mc_ki[cx.outer.mc_top]); if (F_ISSET(leaf->mn_flags, F_DUPDATA)) { - mdbx_tassert(txn, XCURSOR_INITED(&mc) && - mc.mc_xcursor->mx_db.md_entries > 1); - if (mc.mc_xcursor->mx_db.md_entries > 1) { + mdbx_tassert(txn, XCURSOR_INITED(&cx.outer) && + cx.outer.mc_xcursor->mx_db.md_entries > 1); + if (cx.outer.mc_xcursor->mx_db.md_entries > 1) { rc = MDBX_EMULTIVAL; goto bailout; } @@ -12027,7 +13000,7 @@ int mdbx_replace(MDBX_txn *txn, MDBX_dbi dbi, MDBX_val *key, MDBX_val *new_data, flags |= MDBX_CURRENT; } - if (page->mp_flags & P_DIRTY) { + if (IS_DIRTY(page)) { if (unlikely(old_data->iov_len < present_data.iov_len)) { old_data->iov_base = NULL; old_data->iov_len = present_data.iov_len; @@ -12043,12 +13016,12 @@ int mdbx_replace(MDBX_txn *txn, MDBX_dbi dbi, MDBX_val *key, MDBX_val *new_data, } if (likely(new_data)) - rc = mdbx_cursor_put(&mc, key, new_data, flags); + rc = mdbx_cursor_put(&cx.outer, key, new_data, flags); else - rc = mdbx_cursor_del(&mc, 0); + rc = mdbx_cursor_del(&cx.outer, 0); bailout: - txn->mt_cursors[dbi] = mc.mc_next; + txn->mt_cursors[dbi] = cx.outer.mc_next; return rc; } @@ -12072,14 +13045,13 @@ int mdbx_get_ex(MDBX_txn *txn, MDBX_dbi dbi, MDBX_val *key, MDBX_val *data, if (unlikely(txn->mt_flags & MDBX_TXN_BLOCKED)) return MDBX_BAD_TXN; - MDBX_cursor mc; - MDBX_xcursor mx; - int rc = mdbx_cursor_init(&mc, txn, dbi, &mx); + MDBX_cursor_couple cx; + int rc = mdbx_cursor_init(&cx.outer, txn, dbi); if (unlikely(rc != MDBX_SUCCESS)) return rc; int exact = 0; - rc = mdbx_cursor_set(&mc, key, data, MDBX_SET_KEY, &exact); + rc = mdbx_cursor_set(&cx.outer, key, data, MDBX_SET_KEY, &exact); if (unlikely(rc != MDBX_SUCCESS)) { if (rc == MDBX_NOTFOUND && values_count) *values_count = 0; @@ -12088,15 +13060,17 @@ int mdbx_get_ex(MDBX_txn *txn, MDBX_dbi dbi, MDBX_val *key, MDBX_val *data, if (values_count) { *values_count = 1; - if (mc.mc_xcursor != NULL) { - MDBX_node *leaf = NODEPTR(mc.mc_pg[mc.mc_top], mc.mc_ki[mc.mc_top]); + if (cx.outer.mc_xcursor != NULL) { + MDBX_node *leaf = NODEPTR(cx.outer.mc_pg[cx.outer.mc_top], + cx.outer.mc_ki[cx.outer.mc_top]); if (F_ISSET(leaf->mn_flags, F_DUPDATA)) { - mdbx_tassert(txn, mc.mc_xcursor == &mx && - (mx.mx_cursor.mc_flags & C_INITIALIZED)); - *values_count = (sizeof(*values_count) >= sizeof(mx.mx_db.md_entries) || - mx.mx_db.md_entries <= SIZE_MAX) - ? (size_t)mx.mx_db.md_entries - : SIZE_MAX; + mdbx_tassert(txn, cx.outer.mc_xcursor == &cx.inner && + (cx.inner.mx_cursor.mc_flags & C_INITIALIZED)); + *values_count = + (sizeof(*values_count) >= sizeof(cx.inner.mx_db.md_entries) || + cx.inner.mx_db.md_entries <= SIZE_MAX) + ? (size_t)cx.inner.mx_db.md_entries + : SIZE_MAX; } } } @@ -12230,6 +13204,58 @@ int mdbx_dbi_sequence(MDBX_txn *txn, MDBX_dbi dbi, uint64_t *result, } /*----------------------------------------------------------------------------*/ + +__cold intptr_t mdbx_limits_keysize_max(intptr_t pagesize) { + if (pagesize < 1) + pagesize = (intptr_t)mdbx_syspagesize(); + else if (unlikely(pagesize < (intptr_t)MIN_PAGESIZE || + pagesize > (intptr_t)MAX_PAGESIZE || + !mdbx_is_power2((size_t)pagesize))) + return -MDBX_EINVAL; + + return mdbx_maxkey(mdbx_nodemax(pagesize)); +} + +__cold int mdbx_limits_pgsize_min(void) { return MIN_PAGESIZE; } + +__cold int mdbx_limits_pgsize_max(void) { return MAX_PAGESIZE; } + +__cold intptr_t mdbx_limits_dbsize_min(intptr_t pagesize) { + if (pagesize < 1) + pagesize = (intptr_t)mdbx_syspagesize(); + else if (unlikely(pagesize < (intptr_t)MIN_PAGESIZE || + pagesize > (intptr_t)MAX_PAGESIZE || + !mdbx_is_power2((size_t)pagesize))) + return -MDBX_EINVAL; + + return MIN_PAGENO * pagesize; +} + +__cold intptr_t mdbx_limits_dbsize_max(intptr_t pagesize) { + if (pagesize < 1) + pagesize = (intptr_t)mdbx_syspagesize(); + else if (unlikely(pagesize < (intptr_t)MIN_PAGESIZE || + pagesize > (intptr_t)MAX_PAGESIZE || + !mdbx_is_power2((size_t)pagesize))) + return -MDBX_EINVAL; + + const uint64_t limit = MAX_PAGENO * (uint64_t)pagesize; + return (limit < (intptr_t)MAX_MAPSIZE) ? (intptr_t)limit + : (intptr_t)MAX_PAGESIZE; +} + +__cold intptr_t mdbx_limits_txnsize_max(intptr_t pagesize) { + if (pagesize < 1) + pagesize = (intptr_t)mdbx_syspagesize(); + else if (unlikely(pagesize < (intptr_t)MIN_PAGESIZE || + pagesize > (intptr_t)MAX_PAGESIZE || + !mdbx_is_power2((size_t)pagesize))) + return -MDBX_EINVAL; + + return pagesize * (MDBX_DPL_TXNFULL - 1); +} + +/*----------------------------------------------------------------------------*/ /* attribute support functions for Nexenta */ static __inline int mdbx_attr_peek(MDBX_val *data, mdbx_attr_t *attrptr) { @@ -12320,19 +13346,18 @@ int mdbx_set_attr(MDBX_txn *txn, MDBX_dbi dbi, MDBX_val *key, MDBX_val *data, if (unlikely(txn->mt_flags & (MDBX_TXN_RDONLY | MDBX_TXN_BLOCKED))) return (txn->mt_flags & MDBX_TXN_RDONLY) ? MDBX_EACCESS : MDBX_BAD_TXN; - MDBX_cursor mc; - MDBX_xcursor mx; + MDBX_cursor_couple cx; MDBX_val old_data; - int rc = mdbx_cursor_init(&mc, txn, dbi, &mx); + int rc = mdbx_cursor_init(&cx.outer, txn, dbi); if (unlikely(rc != MDBX_SUCCESS)) return rc; - rc = mdbx_cursor_set(&mc, key, &old_data, MDBX_SET, NULL); + rc = mdbx_cursor_set(&cx.outer, key, &old_data, MDBX_SET, NULL); if (unlikely(rc != MDBX_SUCCESS)) { if (rc == MDBX_NOTFOUND && data) { - mc.mc_next = txn->mt_cursors[dbi]; - txn->mt_cursors[dbi] = &mc; - rc = mdbx_cursor_put_attr(&mc, key, data, attr, 0); - txn->mt_cursors[dbi] = mc.mc_next; + cx.outer.mc_next = txn->mt_cursors[dbi]; + txn->mt_cursors[dbi] = &cx.outer; + rc = mdbx_cursor_put_attr(&cx.outer, key, data, attr, 0); + txn->mt_cursors[dbi] = cx.outer.mc_next; } return rc; } @@ -12347,11 +13372,11 @@ int mdbx_set_attr(MDBX_txn *txn, MDBX_dbi dbi, MDBX_val *key, MDBX_val *data, old_data.iov_len) == 0))) return MDBX_SUCCESS; - mc.mc_next = txn->mt_cursors[dbi]; - txn->mt_cursors[dbi] = &mc; - rc = mdbx_cursor_put_attr(&mc, key, data ? data : &old_data, attr, + cx.outer.mc_next = txn->mt_cursors[dbi]; + txn->mt_cursors[dbi] = &cx.outer; + rc = mdbx_cursor_put_attr(&cx.outer, key, data ? data : &old_data, attr, MDBX_CURRENT); - txn->mt_cursors[dbi] = mc.mc_next; + txn->mt_cursors[dbi] = cx.outer.mc_next; return rc; } diff --git a/libs/libmdbx/src/src/osal.h b/libs/libmdbx/src/src/osal.h index daa79064f9..a1feb998d2 100644 --- a/libs/libmdbx/src/src/osal.h +++ b/libs/libmdbx/src/src/osal.h @@ -552,7 +552,6 @@ int mdbx_lck_init(MDBX_env *env); int mdbx_lck_seize(MDBX_env *env); int mdbx_lck_downgrade(MDBX_env *env, bool complete); -int mdbx_lck_upgrade(MDBX_env *env); void mdbx_lck_destroy(MDBX_env *env); int mdbx_rdt_lock(MDBX_env *env); diff --git a/libs/libmdbx/src/src/tools/mdbx_chk.c b/libs/libmdbx/src/src/tools/mdbx_chk.c index 51096c4053..e3ffe3acfe 100644 --- a/libs/libmdbx/src/src/tools/mdbx_chk.c +++ b/libs/libmdbx/src/src/tools/mdbx_chk.c @@ -1,4 +1,4 @@ -/* mdbx_chk.c - memory-mapped database check tool */ +/* mdbx_chk.c - memory-mapped database check tool */ /* * Copyright 2015-2018 Leonid Yuriev <leo@yuriev.ru> @@ -61,17 +61,28 @@ static void signal_handler(int sig) { #define EXIT_FAILURE_CHECK_MAJOR (EXIT_FAILURE + 1) #define EXIT_FAILURE_CHECK_MINOR EXIT_FAILURE +typedef struct { + const char *name; + struct { + uint64_t branch, large_count, large_volume, leaf; + uint64_t subleaf_dupsort, leaf_dupfixed, subleaf_dupfixed; + uint64_t total, empty, other; + } pages; + uint64_t payload_bytes; + uint64_t lost_bytes; +} walk_dbi_t; + struct { - const char *dbi_names[MAX_DBI]; - uint64_t dbi_pages[MAX_DBI]; - uint64_t dbi_empty_pages[MAX_DBI]; - uint64_t dbi_payload_bytes[MAX_DBI]; - uint64_t dbi_lost_bytes[MAX_DBI]; + walk_dbi_t dbi[MAX_DBI]; short *pagemap; uint64_t total_payload_bytes; uint64_t pgcount; } walk; +#define dbi_free walk.dbi[FREE_DBI] +#define dbi_main walk.dbi[MAIN_DBI] +#define dbi_meta walk.dbi[CORE_DBS] + uint64_t total_unused_bytes; int envflags = MDBX_RDONLY | MDBX_EXCLUSIVE; @@ -80,7 +91,7 @@ MDBX_txn *txn; MDBX_envinfo envinfo; MDBX_stat envstat; size_t maxkeysize, userdb_count, skipped_subdb; -uint64_t reclaimable_pages, freedb_pages, lastpgno; +uint64_t reclaimable_pages, gc_pages, lastpgno, unused_pages; unsigned verbose, quiet; const char *only_subdb; @@ -94,7 +105,7 @@ struct problem *problems_list; uint64_t total_problems; static void -#ifdef __GNU__ +#ifdef __GNUC__ __attribute__((format(printf, 1, 2))) #endif print(const char *msg, ...) { @@ -109,7 +120,7 @@ static void } static void -#ifdef __GNU__ +#ifdef __GNUC__ __attribute__((format(printf, 1, 2))) #endif error(const char *msg, ...) { @@ -120,6 +131,7 @@ static void fflush(stdout); va_start(args, msg); + fputs(" ! ", stderr); vfprintf(stderr, msg, args); va_end(args); fflush(NULL); @@ -127,12 +139,10 @@ static void } static void pagemap_cleanup(void) { - int i; - - for (i = 1; i < MAX_DBI; ++i) { - if (walk.dbi_names[i]) { - free((void *)walk.dbi_names[i]); - walk.dbi_names[i] = NULL; + for (int i = CORE_DBS; ++i < MAX_DBI;) { + if (walk.dbi[i].name) { + free((void *)walk.dbi[i].name); + walk.dbi[i].name = NULL; } } @@ -140,32 +150,35 @@ static void pagemap_cleanup(void) { walk.pagemap = NULL; } -static int pagemap_lookup_dbi(const char *dbi) { - static int last; - int i; +static walk_dbi_t *pagemap_lookup_dbi(const char *dbi_name, bool silent) { + static walk_dbi_t *last; - if (last > 0 && strcmp(walk.dbi_names[last], dbi) == 0) + if (last && strcmp(last->name, dbi_name) == 0) return last; - for (i = 1; walk.dbi_names[i] && last < MAX_DBI; ++i) - if (strcmp(walk.dbi_names[i], dbi) == 0) - return last = i; - - if (i == MAX_DBI) - return -1; - - walk.dbi_names[i] = strdup(dbi); + walk_dbi_t *dbi = walk.dbi + CORE_DBS; + for (dbi = walk.dbi + CORE_DBS; (++dbi)->name;) { + if (strcmp(dbi->name, dbi_name) == 0) + return last = dbi; + if (dbi == walk.dbi + MAX_DBI) + return NULL; + } - if (verbose > 1) { - print(" - found '%s' area\n", dbi); + dbi->name = strdup(dbi_name); + if (verbose > 1 && !silent) { + print(" - found '%s' area\n", dbi_name); fflush(NULL); } - return last = i; + return last = dbi; } -static void problem_add(const char *object, uint64_t entry_number, - const char *msg, const char *extra, ...) { +static void +#ifdef __GNUC__ + __attribute__((format(printf, 4, 5))) +#endif + problem_add(const char *object, uint64_t entry_number, const char *msg, + const char *extra, ...) { total_problems++; if (!quiet) { @@ -231,81 +244,140 @@ static uint64_t problems_pop(struct problem *list) { return count; } -static int pgvisitor(uint64_t pgno, unsigned pgnumber, void *ctx, - const char *dbi, const char *type, size_t nentries, +static int pgvisitor(uint64_t pgno, unsigned pgnumber, void *ctx, int deep, + const char *dbi_name, size_t page_size, + MDBX_page_type_t pagetype, size_t nentries, size_t payload_bytes, size_t header_bytes, size_t unused_bytes) { (void)ctx; + if (pagetype == MDBX_page_void) + return MDBX_SUCCESS; - if (type) { - uint64_t page_bytes = payload_bytes + header_bytes + unused_bytes; - size_t page_size = (size_t)pgnumber * envstat.ms_psize; - int index = pagemap_lookup_dbi(dbi); - if (index < 0) + walk_dbi_t fake, *dbi = &fake; + if (deep > 0) { + dbi = pagemap_lookup_dbi(dbi_name, false); + if (!dbi) return MDBX_ENOMEM; + } else if (deep == 0 && strcmp(dbi_name, dbi_main.name) == 0) + dbi = &dbi_main; + else if (deep == -1 && strcmp(dbi_name, dbi_free.name) == 0) + dbi = &dbi_free; + else if (deep == -2 && strcmp(dbi_name, dbi_meta.name) == 0) + dbi = &dbi_meta; + else + problem_add("deep", deep, "unknown area", "%s", dbi_name); + + const uint64_t page_bytes = payload_bytes + header_bytes + unused_bytes; + walk.pgcount += pgnumber; + + const char *pagetype_caption; + switch (pagetype) { + default: + problem_add("page", pgno, "unknown page-type", "%u", (unsigned)pagetype); + pagetype_caption = "unknown"; + dbi->pages.other += pgnumber; + break; + case MDBX_page_meta: + pagetype_caption = "meta"; + dbi->pages.other += pgnumber; + break; + case MDBX_page_large: + pagetype_caption = "large"; + dbi->pages.large_volume += pgnumber; + dbi->pages.large_count += 1; + break; + case MDBX_page_branch: + pagetype_caption = "branch"; + dbi->pages.branch += pgnumber; + break; + case MDBX_page_leaf: + pagetype_caption = "leaf"; + dbi->pages.leaf += pgnumber; + break; + case MDBX_page_dupfixed_leaf: + pagetype_caption = "leaf-dupfixed"; + dbi->pages.leaf_dupfixed += pgnumber; + break; + case MDBX_subpage_leaf: + pagetype_caption = "subleaf-dupsort"; + dbi->pages.subleaf_dupsort += 1; + break; + case MDBX_subpage_dupfixed_leaf: + pagetype_caption = "subleaf-dupfixed"; + dbi->pages.subleaf_dupfixed += 1; + break; + } - if (verbose > 2 && (!only_subdb || strcmp(only_subdb, dbi) == 0)) { + if (pgnumber) { + if (verbose > 3 && (!only_subdb || strcmp(only_subdb, dbi_name) == 0)) { if (pgnumber == 1) - print(" %s-page %" PRIu64, type, pgno); + print(" %s-page %" PRIu64, pagetype_caption, pgno); else - print(" %s-span %" PRIu64 "[%u]", type, pgno, pgnumber); + print(" %s-span %" PRIu64 "[%u]", pagetype_caption, pgno, pgnumber); print(" of %s: header %" PRIiPTR ", payload %" PRIiPTR ", unused %" PRIiPTR "\n", - dbi, header_bytes, payload_bytes, unused_bytes); + dbi_name, header_bytes, payload_bytes, unused_bytes); } + } - walk.pgcount += pgnumber; - - if (unused_bytes > page_size) - problem_add("page", pgno, "illegal unused-bytes", "%u < %i < %u", 0, - unused_bytes, envstat.ms_psize); - - if (header_bytes < (int)sizeof(long) || - (size_t)header_bytes >= envstat.ms_psize - sizeof(long)) - problem_add("page", pgno, "illegal header-length", - "%" PRIuPTR " < %i < %" PRIuPTR "", sizeof(long), - header_bytes, envstat.ms_psize - sizeof(long)); - if (payload_bytes < 1) { - if (nentries > 1) { - problem_add("page", pgno, "zero size-of-entry", - "payload %i bytes, %i entries", payload_bytes, nentries); - if ((size_t)header_bytes + unused_bytes < page_size) { - /* LY: hush a misuse error */ - page_bytes = page_size; - } - } else { - problem_add("page", pgno, "empty", "payload %i bytes, %i entries", - payload_bytes, nentries); - walk.dbi_empty_pages[index] += 1; - } + if (unused_bytes > page_size) + problem_add("page", pgno, "illegal unused-bytes", + "%s-page: %u < %" PRIuPTR " < %u", pagetype_caption, 0, + unused_bytes, envstat.ms_psize); + + if (header_bytes < (int)sizeof(long) || + (size_t)header_bytes >= envstat.ms_psize - sizeof(long)) + problem_add("page", pgno, "illegal header-length", + "%s-page: %" PRIuPTR " < %" PRIuPTR " < %" PRIuPTR, + pagetype_caption, sizeof(long), header_bytes, + envstat.ms_psize - sizeof(long)); + if (payload_bytes < 1) { + if (nentries > 1) { + problem_add("page", pgno, "zero size-of-entry", + "%s-page: payload %" PRIuPTR " bytes, %" PRIuPTR " entries", + pagetype_caption, payload_bytes, nentries); + /* if ((size_t)header_bytes + unused_bytes < page_size) { + // LY: hush a misuse error + page_bytes = page_size; + } */ + } else { + problem_add("page", pgno, "empty", + "%s-page: payload %" PRIuPTR " bytes, %" PRIuPTR " entries", + pagetype_caption, payload_bytes, nentries); + dbi->pages.empty += 1; } + } + if (pgnumber) { if (page_bytes != page_size) { problem_add("page", pgno, "misused", - "%" PRIu64 " != %" PRIu64 " (%ih + %ip + %iu)", page_size, - page_bytes, header_bytes, payload_bytes, unused_bytes); + "%s-page: %" PRIu64 " != %" PRIu64 " (%" PRIuPTR + "h + %" PRIuPTR "p + %" PRIuPTR "u)", + pagetype_caption, page_size, page_bytes, header_bytes, + payload_bytes, unused_bytes); if (page_size > page_bytes) - walk.dbi_lost_bytes[index] += page_size - page_bytes; + dbi->lost_bytes += page_size - page_bytes; } else { - walk.dbi_payload_bytes[index] += payload_bytes + header_bytes; + dbi->payload_bytes += payload_bytes + header_bytes; walk.total_payload_bytes += payload_bytes + header_bytes; } + } - if (pgnumber) { - do { - if (pgno >= lastpgno) - problem_add("page", pgno, "wrong page-no", - "%" PRIu64 " > %" PRIu64 "", pgno, lastpgno); - else if (walk.pagemap[pgno]) - problem_add("page", pgno, "already used", "in %s", - walk.dbi_names[walk.pagemap[pgno]]); - else { - walk.pagemap[pgno] = (short)index; - walk.dbi_pages[index] += 1; - } - ++pgno; - } while (--pgnumber); - } + if (pgnumber) { + do { + if (pgno >= lastpgno) + problem_add("page", pgno, "wrong page-no", + "%s-page: %" PRIu64 " > %" PRIu64, pagetype_caption, pgno, + lastpgno); + else if (walk.pagemap[pgno]) + problem_add("page", pgno, "already used", "%s-page: by %s", + pagetype_caption, walk.dbi[walk.pagemap[pgno] - 1].name); + else { + walk.pagemap[pgno] = (short)(dbi - walk.dbi + 1); + dbi->pages.total += 1; + } + ++pgno; + } while (--pgnumber); } return user_break ? MDBX_EINTR : MDBX_SUCCESS; @@ -313,7 +385,8 @@ static int pgvisitor(uint64_t pgno, unsigned pgnumber, void *ctx, typedef int(visitor)(const uint64_t record_number, const MDBX_val *key, const MDBX_val *data); -static int process_db(MDBX_dbi dbi, char *name, visitor *handler, bool silent); +static int process_db(MDBX_dbi dbi_handle, char *dbi_name, visitor *handler, + bool silent); static int handle_userdb(const uint64_t record_number, const MDBX_val *key, const MDBX_val *data) { @@ -331,65 +404,79 @@ static int handle_freedb(const uint64_t record_number, const MDBX_val *key, if (key->iov_len != sizeof(txnid_t)) problem_add("entry", record_number, "wrong txn-id size", - "key-size %" PRIiPTR "", key->iov_len); + "key-size %" PRIiPTR, key->iov_len); else if (txnid < 1 || txnid > envinfo.mi_recent_txnid) - problem_add("entry", record_number, "wrong txn-id", "%" PRIaTXN "", txnid); - - if (data->iov_len < sizeof(pgno_t) || data->iov_len % sizeof(pgno_t)) - problem_add("entry", record_number, "wrong idl size", "%" PRIuPTR "", - data->iov_len); + problem_add("entry", record_number, "wrong txn-id", "%" PRIaTXN, txnid); else { - const pgno_t number = *iptr++; - if (number >= MDBX_PNL_UM_MAX) - problem_add("entry", record_number, "wrong idl length", "%" PRIiPTR "", + if (data->iov_len < sizeof(pgno_t) || data->iov_len % sizeof(pgno_t)) + problem_add("entry", record_number, "wrong idl size", "%" PRIuPTR, + data->iov_len); + size_t number = (data->iov_len >= sizeof(pgno_t)) ? *iptr++ : 0; + if (number < 1 || number > MDBX_PNL_MAX) + problem_add("entry", record_number, "wrong idl length", "%" PRIuPTR, number); - else if ((number + 1) * sizeof(pgno_t) != data->iov_len) - problem_add("entry", record_number, "mismatch idl length", - "%" PRIuSIZE " != %" PRIuSIZE "", + else if ((number + 1) * sizeof(pgno_t) > data->iov_len) { + problem_add("entry", record_number, "trimmed idl", + "%" PRIuSIZE " > %" PRIuSIZE " (corruption)", (number + 1) * sizeof(pgno_t), data->iov_len); - else { - freedb_pages += number; - if (envinfo.mi_latter_reader_txnid > txnid) - reclaimable_pages += number; - - pgno_t prev = - MDBX_PNL_ASCENDING ? NUM_METAS - 1 : (pgno_t)envinfo.mi_last_pgno + 1; - pgno_t span = 1; - for (unsigned i = 0; i < number; ++i) { - const pgno_t pg = iptr[i]; - if (pg < NUM_METAS || pg > envinfo.mi_last_pgno) - problem_add("entry", record_number, "wrong idl entry", - "%u < %" PRIaPGNO " < %" PRIu64 "", NUM_METAS, pg, - envinfo.mi_last_pgno); - else if (MDBX_PNL_DISORDERED(prev, pg)) { + number = data->iov_len / sizeof(pgno_t) - 1; + } else if (data->iov_len - (number + 1) * sizeof(pgno_t) > + sizeof(pgno_t) * 2) + problem_add("entry", record_number, "extra idl space", + "%" PRIuSIZE " < %" PRIuSIZE " (minor, not a trouble)", + (number + 1) * sizeof(pgno_t), data->iov_len); + + gc_pages += number; + if (envinfo.mi_latter_reader_txnid > txnid) + reclaimable_pages += number; + + pgno_t prev = + MDBX_PNL_ASCENDING ? NUM_METAS - 1 : (pgno_t)envinfo.mi_last_pgno + 1; + pgno_t span = 1; + for (unsigned i = 0; i < number; ++i) { + const pgno_t pgno = iptr[i]; + if (pgno < NUM_METAS || pgno > envinfo.mi_last_pgno) + problem_add("entry", record_number, "wrong idl entry", + "%u < %" PRIaPGNO " < %" PRIu64, NUM_METAS, pgno, + envinfo.mi_last_pgno); + else { + if (MDBX_PNL_DISORDERED(prev, pgno)) { bad = " [bad sequence]"; problem_add("entry", record_number, "bad sequence", - "%" PRIaPGNO " <> %" PRIaPGNO "", prev, pg); + "%" PRIaPGNO " <> %" PRIaPGNO, prev, pgno); + } + if (walk.pagemap && walk.pagemap[pgno]) { + if (walk.pagemap[pgno] > 0) + problem_add("page", pgno, "already used", "by %s", + walk.dbi[walk.pagemap[pgno] - 1].name); + else + problem_add("page", pgno, "already listed in GC", nullptr); + walk.pagemap[pgno] = -1; } - prev = pg; - while (i + span < number && - iptr[i + span] == (MDBX_PNL_ASCENDING ? pgno_add(pg, span) - : pgno_sub(pg, span))) - ++span; } - if (verbose > 2 && !only_subdb) { - print(" transaction %" PRIaTXN ", %" PRIaPGNO - " pages, maxspan %" PRIaPGNO "%s\n", - txnid, number, span, bad); - if (verbose > 3) { - for (unsigned i = 0; i < number; i += span) { - const pgno_t pg = iptr[i]; - for (span = 1; - i + span < number && - iptr[i + span] == (MDBX_PNL_ASCENDING ? pgno_add(pg, span) - : pgno_sub(pg, span)); - ++span) - ; - if (span > 1) { - print(" %9" PRIaPGNO "[%" PRIaPGNO "]\n", pg, span); - } else - print(" %9" PRIaPGNO "\n", pg); - } + prev = pgno; + while (i + span < number && + iptr[i + span] == (MDBX_PNL_ASCENDING ? pgno_add(pgno, span) + : pgno_sub(pgno, span))) + ++span; + } + if (verbose > 3 && !only_subdb) { + print(" transaction %" PRIaTXN ", %" PRIuPTR + " pages, maxspan %" PRIaPGNO "%s\n", + txnid, number, span, bad); + if (verbose > 4) { + for (unsigned i = 0; i < number; i += span) { + const pgno_t pgno = iptr[i]; + for (span = 1; + i + span < number && + iptr[i + span] == (MDBX_PNL_ASCENDING ? pgno_add(pgno, span) + : pgno_sub(pgno, span)); + ++span) + ; + if (span > 1) { + print(" %9" PRIaPGNO "[%" PRIaPGNO "]\n", pgno, span); + } else + print(" %9" PRIaPGNO "\n", pgno); } } } @@ -423,7 +510,8 @@ static int handle_maindb(const uint64_t record_number, const MDBX_val *key, return handle_userdb(record_number, key, data); } -static int process_db(MDBX_dbi dbi, char *name, visitor *handler, bool silent) { +static int process_db(MDBX_dbi dbi_handle, char *dbi_name, visitor *handler, + bool silent) { MDBX_cursor *mc; MDBX_stat ms; MDBX_val key, data; @@ -436,22 +524,23 @@ static int process_db(MDBX_dbi dbi, char *name, visitor *handler, bool silent) { uint64_t record_count = 0, dups = 0; uint64_t key_bytes = 0, data_bytes = 0; - if (dbi == ~0u) { - rc = mdbx_dbi_open(txn, name, 0, &dbi); + if (dbi_handle == ~0u) { + rc = mdbx_dbi_open(txn, dbi_name, 0, &dbi_handle); if (rc) { - if (!name || + if (!dbi_name || rc != MDBX_INCOMPATIBLE) /* LY: mainDB's record is not a user's DB. */ { - error(" - mdbx_open '%s' failed, error %d %s\n", name ? name : "main", - rc, mdbx_strerror(rc)); + error("mdbx_open '%s' failed, error %d %s\n", + dbi_name ? dbi_name : "main", rc, mdbx_strerror(rc)); } return rc; } } - if (dbi >= CORE_DBS && name && only_subdb && strcmp(only_subdb, name)) { + if (dbi_handle >= CORE_DBS && dbi_name && only_subdb && + strcmp(only_subdb, dbi_name)) { if (verbose) { - print("Skip processing '%s'...\n", name); + print("Skip processing '%s'...\n", dbi_name); fflush(NULL); } skipped_subdb++; @@ -459,24 +548,24 @@ static int process_db(MDBX_dbi dbi, char *name, visitor *handler, bool silent) { } if (!silent && verbose) { - print("Processing '%s'...\n", name ? name : "main"); + print("Processing '%s'...\n", dbi_name ? dbi_name : "@MAIN"); fflush(NULL); } - rc = mdbx_dbi_flags(txn, dbi, &flags); + rc = mdbx_dbi_flags(txn, dbi_handle, &flags); if (rc) { - error(" - mdbx_dbi_flags failed, error %d %s\n", rc, mdbx_strerror(rc)); + error("mdbx_dbi_flags failed, error %d %s\n", rc, mdbx_strerror(rc)); return rc; } - rc = mdbx_dbi_stat(txn, dbi, &ms, sizeof(ms)); + rc = mdbx_dbi_stat(txn, dbi_handle, &ms, sizeof(ms)); if (rc) { - error(" - mdbx_dbi_stat failed, error %d %s\n", rc, mdbx_strerror(rc)); + error("mdbx_dbi_stat failed, error %d %s\n", rc, mdbx_strerror(rc)); return rc; } if (!silent && verbose) { - print(" - dbi-id %d, flags:", dbi); + print(" - dbi-id %d, flags:", dbi_handle); if (!flags) print(" none"); else { @@ -495,9 +584,32 @@ static int process_db(MDBX_dbi dbi, char *name, visitor *handler, bool silent) { } } - rc = mdbx_cursor_open(txn, dbi, &mc); + walk_dbi_t *dbi = (dbi_handle < CORE_DBS) + ? &walk.dbi[dbi_handle] + : pagemap_lookup_dbi(dbi_name, true); + if (!dbi) { + error("too many DBIs or out of memory\n"); + return MDBX_ENOMEM; + } + const uint64_t subtotal_pages = + ms.ms_branch_pages + ms.ms_leaf_pages + ms.ms_overflow_pages; + if (subtotal_pages != dbi->pages.total) + error("%s pages mismatch (%" PRIu64 " != walked %" PRIu64 ")\n", "subtotal", + subtotal_pages, dbi->pages.total); + if (ms.ms_branch_pages != dbi->pages.branch) + error("%s pages mismatch (%" PRIu64 " != walked %" PRIu64 ")\n", "branch", + ms.ms_branch_pages, dbi->pages.branch); + const uint64_t allleaf_pages = dbi->pages.leaf + dbi->pages.leaf_dupfixed; + if (ms.ms_leaf_pages != allleaf_pages) + error("%s pages mismatch (%" PRIu64 " != walked %" PRIu64 ")\n", "all-leaf", + ms.ms_leaf_pages, allleaf_pages); + if (ms.ms_overflow_pages != dbi->pages.large_volume) + error("%s pages mismatch (%" PRIu64 " != walked %" PRIu64 ")\n", + "large/overlow", ms.ms_overflow_pages, dbi->pages.large_volume); + + rc = mdbx_cursor_open(txn, dbi_handle, &mc); if (rc) { - error(" - mdbx_cursor_open failed, error %d %s\n", rc, mdbx_strerror(rc)); + error("mdbx_cursor_open failed, error %d %s\n", rc, mdbx_strerror(rc)); return rc; } @@ -515,7 +627,7 @@ static int process_db(MDBX_dbi dbi, char *name, visitor *handler, bool silent) { if (key.iov_len > maxkeysize) { problem_add("entry", record_count, "key length exceeds max-key-size", - "%" PRIuPTR " > %u", key.iov_len, maxkeysize); + "%" PRIuPTR " > %" PRIuPTR, key.iov_len, maxkeysize); } else if ((flags & MDBX_INTEGERKEY) && key.iov_len != sizeof(uint64_t) && key.iov_len != sizeof(uint32_t)) { problem_add("entry", record_count, "wrong key length", @@ -531,11 +643,11 @@ static int process_db(MDBX_dbi dbi, char *name, visitor *handler, bool silent) { if (prev_key.iov_base) { if ((flags & MDBX_DUPFIXED) && prev_data.iov_len != data.iov_len) { problem_add("entry", record_count, "different data length", - "%" PRIuPTR " != %" PRIuPTR "", prev_data.iov_len, + "%" PRIuPTR " != %" PRIuPTR, prev_data.iov_len, data.iov_len); } - int cmp = mdbx_cmp(txn, dbi, &prev_key, &key); + int cmp = mdbx_cmp(txn, dbi_handle, &prev_key, &key); if (cmp > 0) { problem_add("entry", record_count, "broken ordering of entries", NULL); } else if (cmp == 0) { @@ -543,7 +655,7 @@ static int process_db(MDBX_dbi dbi, char *name, visitor *handler, bool silent) { if (!(flags & MDBX_DUPSORT)) problem_add("entry", record_count, "duplicated entries", NULL); else if (flags & MDBX_INTEGERDUP) { - cmp = mdbx_dcmp(txn, dbi, &prev_data, &data); + cmp = mdbx_dcmp(txn, dbi_handle, &prev_data, &data); if (cmp > 0) problem_add("entry", record_count, "broken ordering of multi-values", NULL); @@ -571,13 +683,13 @@ static int process_db(MDBX_dbi dbi, char *name, visitor *handler, bool silent) { rc = mdbx_cursor_get(mc, &key, &data, MDBX_NEXT); } if (rc != MDBX_NOTFOUND) - error(" - mdbx_cursor_get failed, error %d %s\n", rc, mdbx_strerror(rc)); + error("mdbx_cursor_get failed, error %d %s\n", rc, mdbx_strerror(rc)); else rc = 0; if (record_count != ms.ms_entries) problem_add("entry", record_count, "differentent number of entries", - "%" PRIuPTR " != %" PRIuPTR "", record_count, ms.ms_entries); + "%" PRIuPTR " != %" PRIuPTR, record_count, ms.ms_entries); bailout: problems_count = problems_pop(saved_list); if (!silent && verbose) { @@ -715,7 +827,7 @@ static int check_meta_head(bool steady) { switch (meta_recent(steady)) { default: assert(false); - error(" - unexpected internal error (%s)\n", + error("unexpected internal error (%s)\n", steady ? "meta_steady_head" : "meta_weak_head"); __fallthrough; case 0: @@ -757,7 +869,7 @@ static void print_size(const char *prefix, const uint64_t value, } int main(int argc, char *argv[]) { - int i, rc; + int rc; char *prog = argv[0]; char *envname; int problems_maindb = 0, problems_freedb = 0, problems_meta = 0; @@ -777,14 +889,16 @@ int main(int argc, char *argv[]) { } #endif - walk.dbi_names[0] = "@gc"; + dbi_meta.name = "@META"; + dbi_free.name = "@GC"; + dbi_main.name = "@MAIN"; atexit(pagemap_cleanup); if (argc < 2) { usage(prog); } - while ((i = getopt(argc, argv, "Vvqnwcds:")) != EOF) { + for (int i; (i = getopt(argc, argv, "Vvqnwcds:")) != EOF;) { switch (i) { case 'V': printf("%s (%s, build %s)\n", mdbx_version.git.describe, @@ -1000,26 +1114,46 @@ int main(int argc, char *argv[]) { goto bailout; } - uint64_t n; - for (n = 0; n < lastpgno; ++n) + for (uint64_t n = 0; n < lastpgno; ++n) if (!walk.pagemap[n]) - walk.dbi_pages[0] += 1; + unused_pages += 1; empty_pages = lost_bytes = 0; - for (i = 1; i < MAX_DBI && walk.dbi_names[i]; ++i) { - empty_pages += walk.dbi_empty_pages[i]; - lost_bytes += walk.dbi_lost_bytes[i]; + for (walk_dbi_t *dbi = &dbi_main; dbi < walk.dbi + MAX_DBI && dbi->name; + ++dbi) { + empty_pages += dbi->pages.empty; + lost_bytes += dbi->lost_bytes; } if (verbose) { uint64_t total_page_bytes = walk.pgcount * envstat.ms_psize; - print(" - dbi pages: %" PRIu64 " total", walk.pgcount); - if (verbose > 1) - for (i = 1; i < MAX_DBI && walk.dbi_names[i]; ++i) - print(", %s %" PRIu64 "", walk.dbi_names[i], walk.dbi_pages[i]); - print(", %s %" PRIu64 "\n", walk.dbi_names[0], walk.dbi_pages[0]); + print(" - pages: total %" PRIu64 ", unused %" PRIu64 "\n", walk.pgcount, + unused_pages); if (verbose > 1) { - print(" - space info: total %" PRIu64 " bytes, payload %" PRIu64 + for (walk_dbi_t *dbi = walk.dbi; dbi < walk.dbi + MAX_DBI && dbi->name; + ++dbi) { + print(" %s: subtotal %" PRIu64, dbi->name, dbi->pages.total); + if (dbi->pages.other && dbi->pages.other != dbi->pages.total) + print(", other %" PRIu64, dbi->pages.other); + if (dbi->pages.branch) + print(", branch %" PRIu64, dbi->pages.branch); + if (dbi->pages.large_count) + print(", large %" PRIu64, dbi->pages.large_count); + uint64_t all_leaf = dbi->pages.leaf + dbi->pages.leaf_dupfixed; + if (all_leaf) { + print(", leaf %" PRIu64, all_leaf); + if (verbose > 2) + print(" (usual %" PRIu64 ", sub-dupsort %" PRIu64 + ", dupfixed %" PRIu64 ", sub-dupfixed %" PRIu64 ")", + dbi->pages.leaf, dbi->pages.subleaf_dupsort, + dbi->pages.leaf_dupfixed, dbi->pages.subleaf_dupfixed); + } + print("\n"); + } + } + + if (verbose > 1) + print(" - usage: total %" PRIu64 " bytes, payload %" PRIu64 " (%.1f%%), unused " "%" PRIu64 " (%.1f%%)\n", total_page_bytes, walk.total_payload_bytes, @@ -1027,19 +1161,20 @@ int main(int argc, char *argv[]) { total_page_bytes - walk.total_payload_bytes, (total_page_bytes - walk.total_payload_bytes) * 100.0 / total_page_bytes); - for (i = 1; i < MAX_DBI && walk.dbi_names[i]; ++i) { - uint64_t dbi_bytes = walk.dbi_pages[i] * envstat.ms_psize; + if (verbose > 2) { + for (walk_dbi_t *dbi = walk.dbi; dbi < walk.dbi + MAX_DBI && dbi->name; + ++dbi) { + uint64_t dbi_bytes = dbi->pages.total * envstat.ms_psize; print(" %s: subtotal %" PRIu64 " bytes (%.1f%%)," " payload %" PRIu64 " (%.1f%%), unused %" PRIu64 " (%.1f%%)", - walk.dbi_names[i], dbi_bytes, - dbi_bytes * 100.0 / total_page_bytes, walk.dbi_payload_bytes[i], - walk.dbi_payload_bytes[i] * 100.0 / dbi_bytes, - dbi_bytes - walk.dbi_payload_bytes[i], - (dbi_bytes - walk.dbi_payload_bytes[i]) * 100.0 / dbi_bytes); - if (walk.dbi_empty_pages[i]) - print(", %" PRIu64 " empty pages", walk.dbi_empty_pages[i]); - if (walk.dbi_lost_bytes[i]) - print(", %" PRIu64 " bytes lost", walk.dbi_lost_bytes[i]); + dbi->name, dbi_bytes, dbi_bytes * 100.0 / total_page_bytes, + dbi->payload_bytes, dbi->payload_bytes * 100.0 / dbi_bytes, + dbi_bytes - dbi->payload_bytes, + (dbi_bytes - dbi->payload_bytes) * 100.0 / dbi_bytes); + if (dbi->pages.empty) + print(", %" PRIu64 " empty pages", dbi->pages.empty); + if (dbi->lost_bytes) + print(", %" PRIu64 " bytes lost", dbi->lost_bytes); print("\n"); } } @@ -1059,12 +1194,12 @@ int main(int argc, char *argv[]) { if (!verbose) print("Iterating DBIs...\n"); problems_maindb = process_db(~0u, /* MAIN_DBI */ NULL, NULL, false); - problems_freedb = process_db(FREE_DBI, "free", handle_freedb, false); + problems_freedb = process_db(FREE_DBI, "@GC", handle_freedb, false); if (verbose) { uint64_t value = envinfo.mi_mapsize / envstat.ms_psize; double percent = value / 100.0; - print(" - pages info: %" PRIu64 " total", value); + print(" - space: %" PRIu64 " total pages", value); value = envinfo.mi_geo.current / envinfo.mi_dxb_pagesize; print(", backed %" PRIu64 " (%.1f%%)", value, value / percent); print(", allocated %" PRIu64 " (%.1f%%)", lastpgno, lastpgno / percent); @@ -1073,12 +1208,12 @@ int main(int argc, char *argv[]) { value = envinfo.mi_mapsize / envstat.ms_psize - lastpgno; print(", remained %" PRIu64 " (%.1f%%)", value, value / percent); - value = lastpgno - freedb_pages; + value = lastpgno - gc_pages; print(", used %" PRIu64 " (%.1f%%)", value, value / percent); - print(", gc %" PRIu64 " (%.1f%%)", freedb_pages, freedb_pages / percent); + print(", gc %" PRIu64 " (%.1f%%)", gc_pages, gc_pages / percent); - value = freedb_pages - reclaimable_pages; + value = gc_pages - reclaimable_pages; print(", detained %" PRIu64 " (%.1f%%)", value, value / percent); print(", reclaimable %" PRIu64 " (%.1f%%)", reclaimable_pages, @@ -1093,13 +1228,13 @@ int main(int argc, char *argv[]) { if (problems_maindb == 0 && problems_freedb == 0) { if (!dont_traversal && (envflags & (MDBX_EXCLUSIVE | MDBX_RDONLY)) != MDBX_RDONLY) { - if (walk.pgcount != lastpgno - freedb_pages) { + if (walk.pgcount != lastpgno - gc_pages) { error("used pages mismatch (%" PRIu64 " != %" PRIu64 ")\n", - walk.pgcount, lastpgno - freedb_pages); + walk.pgcount, lastpgno - gc_pages); } - if (walk.dbi_pages[0] != freedb_pages) { - error("gc pages mismatch (%" PRIu64 " != %" PRIu64 ")\n", - walk.dbi_pages[0], freedb_pages); + if (unused_pages != gc_pages) { + error("gc pages mismatch (%" PRIu64 " != %" PRIu64 ")\n", unused_pages, + gc_pages); } } else if (verbose) { print(" - skip check used and gc pages (btree-traversal with " @@ -1141,8 +1276,8 @@ bailout: total_problems += problems_meta; if (total_problems || problems_maindb || problems_freedb) { - print("Total %" PRIu64 " error(s) is detected, elapsed %.3f seconds.\n", - total_problems, elapsed); + print("Total %" PRIu64 " error%s detected, elapsed %.3f seconds.\n", + total_problems, (total_problems > 1) ? "s are" : " is", elapsed); if (problems_meta || problems_maindb || problems_freedb) return EXIT_FAILURE_CHECK_MAJOR; return EXIT_FAILURE_CHECK_MINOR; diff --git a/libs/libmdbx/src/src/tools/mdbx_load.c b/libs/libmdbx/src/src/tools/mdbx_load.c index 4a337a1af3..a18b50c491 100644 --- a/libs/libmdbx/src/src/tools/mdbx_load.c +++ b/libs/libmdbx/src/src/tools/mdbx_load.c @@ -136,7 +136,7 @@ static void readhdr(void) { ptr = memchr(dbuf.iov_base, '\n', dbuf.iov_len); if (ptr) *ptr = '\0'; - i = sscanf((char *)dbuf.iov_base + STRLENOF("mapsize="), "%" PRIu64 "", + i = sscanf((char *)dbuf.iov_base + STRLENOF("mapsize="), "%" PRIu64, &envinfo.mi_mapsize); if (i != 1) { fprintf(stderr, "%s: line %" PRIiSIZE ": invalid mapsize %s\n", prog, diff --git a/libs/libmdbx/src/test/config.cc b/libs/libmdbx/src/test/config.cc index cbff68ce4e..619bd35727 100644 --- a/libs/libmdbx/src/test/config.cc +++ b/libs/libmdbx/src/test/config.cc @@ -43,6 +43,11 @@ bool parse_option(int argc, char *const argv[], int &narg, const char *option, if (narg + 1 < argc && strncmp("--", argv[narg + 1], 2) != 0) { *value = argv[narg + 1]; + if (strcmp(*value, "default") == 0) { + if (!default_value) + failure("Option '--%s' doen't accept default value\n", option); + *value = default_value; + } ++narg; return true; } @@ -57,9 +62,15 @@ bool parse_option(int argc, char *const argv[], int &narg, const char *option, bool parse_option(int argc, char *const argv[], int &narg, const char *option, std::string &value, bool allow_empty) { + return parse_option(argc, argv, narg, option, value, allow_empty, + allow_empty ? "" : nullptr); +} + +bool parse_option(int argc, char *const argv[], int &narg, const char *option, + std::string &value, bool allow_empty, + const char *default_value) { const char *value_cstr; - if (!parse_option(argc, argv, narg, option, &value_cstr, - allow_empty ? "" : nullptr)) + if (!parse_option(argc, argv, narg, option, &value_cstr, default_value)) return false; if (!allow_empty && strlen(value_cstr) == 0) @@ -75,7 +86,7 @@ bool parse_option(int argc, char *const argv[], int &narg, const char *option, if (!parse_option(argc, argv, narg, option, &list)) return false; - mask = 0; + unsigned clear = 0; while (*list) { if (*list == ',' || *list == ' ' || *list == '\t') { ++list; @@ -83,14 +94,21 @@ bool parse_option(int argc, char *const argv[], int &narg, const char *option, } const char *const comma = strchr(list, ','); + const bool strikethrough = *list == '-' || *list == '~'; + if (strikethrough || *list == '+') + ++list; + else + mask = clear; const size_t len = (comma) ? comma - list : strlen(list); const option_verb *scan = verbs; + while (true) { if (!scan->verb) failure("Unknown verb '%.*s', for option '==%s'\n", (int)len, list, option); if (strlen(scan->verb) == len && strncmp(list, scan->verb, len) == 0) { - mask |= scan->mask; + mask = strikethrough ? mask & ~scan->mask : mask | scan->mask; + clear = strikethrough ? clear & ~scan->mask : clear | scan->mask; list += len; break; } @@ -103,15 +121,36 @@ bool parse_option(int argc, char *const argv[], int &narg, const char *option, bool parse_option(int argc, char *const argv[], int &narg, const char *option, uint64_t &value, const scale_mode scale, - const uint64_t minval, const uint64_t maxval) { + const uint64_t minval, const uint64_t maxval, + const uint64_t default_value) { const char *value_cstr; if (!parse_option(argc, argv, narg, option, &value_cstr)) return false; + if (default_value && strcmp(value_cstr, "default") == 0) { + value = default_value; + return true; + } + + if (strcmp(value_cstr, "min") == 0 || strcmp(value_cstr, "minimal") == 0) { + value = minval; + return true; + } + + if (strcmp(value_cstr, "max") == 0 || strcmp(value_cstr, "maximal") == 0) { + value = maxval; + return true; + } + char *suffix = nullptr; errno = 0; - unsigned long raw = strtoul(value_cstr, &suffix, 0); + unsigned long long raw = strtoull(value_cstr, &suffix, 0); + if ((suffix && *suffix) || errno) { + suffix = nullptr; + errno = 0; + raw = strtoull(value_cstr, &suffix, 10); + } if (errno) failure("Option '--%s' expects a numeric value (%s)\n", option, test_strerror(errno)); @@ -167,28 +206,58 @@ bool parse_option(int argc, char *const argv[], int &narg, const char *option, bool parse_option(int argc, char *const argv[], int &narg, const char *option, unsigned &value, const scale_mode scale, - const unsigned minval, const unsigned maxval) { + const unsigned minval, const unsigned maxval, + const unsigned default_value) { uint64_t huge; - if (!parse_option(argc, argv, narg, option, huge, scale, minval, maxval)) + if (!parse_option(argc, argv, narg, option, huge, scale, minval, maxval, + default_value)) return false; value = (unsigned)huge; return true; } bool parse_option(int argc, char *const argv[], int &narg, const char *option, - uint8_t &value, const uint8_t minval, const uint8_t maxval) { + uint8_t &value, const uint8_t minval, const uint8_t maxval, + const uint8_t default_value) { uint64_t huge; - if (!parse_option(argc, argv, narg, option, huge, no_scale, minval, maxval)) + if (!parse_option(argc, argv, narg, option, huge, no_scale, minval, maxval, + default_value)) return false; value = (uint8_t)huge; return true; } bool parse_option(int argc, char *const argv[], int &narg, const char *option, + int64_t &value, const int64_t minval, const int64_t maxval, + const int64_t default_value) { + uint64_t proxy = (uint64_t)value; + if (parse_option(argc, argv, narg, option, proxy, config::binary, + (uint64_t)minval, (uint64_t)maxval, + (uint64_t)default_value)) { + value = (int64_t)proxy; + return true; + } + return false; +} + +bool parse_option(int argc, char *const argv[], int &narg, const char *option, + int32_t &value, const int32_t minval, const int32_t maxval, + const int32_t default_value) { + uint64_t proxy = (uint64_t)value; + if (parse_option(argc, argv, narg, option, proxy, config::binary, + (uint64_t)minval, (uint64_t)maxval, + (uint64_t)default_value)) { + value = (int32_t)proxy; + return true; + } + return false; +} + +bool parse_option(int argc, char *const argv[], int &narg, const char *option, bool &value) { - const char *value_cstr = NULL; + const char *value_cstr = nullptr; if (!parse_option(argc, argv, narg, option, &value_cstr, "yes")) { const char *current = argv[narg]; if (strncmp(current, "--no-", 5) == 0 && strcmp(current + 5, option) == 0) { @@ -257,7 +326,7 @@ static void dump_verbs(const char *caption, size_t bits, ++verbs; } - logging::feed("\n"); + logging::feed("%s\n", (*comma == '\0') ? "none" : ""); } static void dump_duration(const char *caption, unsigned duration) { @@ -288,8 +357,12 @@ void dump(const char *title) { : i->params.pathname_log.c_str()); } - log_info("database: %s, size %" PRIu64 "\n", i->params.pathname_db.c_str(), - i->params.size); + log_info("database: %s, size %" PRIuPTR "[%" PRIiPTR "..%" PRIiPTR + ", %i %i, %i]\n", + i->params.pathname_db.c_str(), i->params.size_now, + i->params.size_lower, i->params.size_upper, + i->params.shrink_threshold, i->params.growth_step, + i->params.pagesize); dump_verbs("mode", i->params.mode_flags, mode_bits); dump_verbs("table", i->params.table_flags, table_bits); @@ -306,7 +379,13 @@ void dump(const char *title) { log_info("threads %u\n", i->params.nthreads); - log_info("keygen.case: %s\n", keygencase2str(i->params.keygen.keycase)); + log_info( + "keygen.params: case %s, width %u, mesh %u, rotate %u, offset %" PRIu64 + ", split %u/%u\n", + keygencase2str(i->params.keygen.keycase), i->params.keygen.width, + i->params.keygen.mesh, i->params.keygen.rotate, i->params.keygen.offset, + i->params.keygen.split, + i->params.keygen.width - i->params.keygen.split); log_info("keygen.seed: %u\n", i->params.keygen.seed); log_info("key: minlen %u, maxlen %u\n", i->params.keylen_min, i->params.keylen_max); @@ -469,3 +548,27 @@ bool actor_config::deserialize(const char *str, actor_config &config) { TRACE("<< actor_config::deserialize: OK\n"); return true; } + +unsigned actor_params::mdbx_keylen_min() const { + return (table_flags & MDBX_INTEGERKEY) ? 4 : 0; +} + +unsigned actor_params::mdbx_keylen_max() const { + return (table_flags & MDBX_INTEGERKEY) + ? 8 + : std::min((unsigned)mdbx_limits_keysize_max(pagesize), + (unsigned)UINT16_MAX); +} + +unsigned actor_params::mdbx_datalen_min() const { + return (table_flags & MDBX_INTEGERDUP) ? 4 : 0; +} + +unsigned actor_params::mdbx_datalen_max() const { + return (table_flags & MDBX_INTEGERDUP) + ? 8 + : std::min((table_flags & MDBX_DUPSORT) + ? (unsigned)mdbx_limits_keysize_max(pagesize) + : (unsigned)MDBX_MAXDATASIZE, + (unsigned)UINT16_MAX); +} diff --git a/libs/libmdbx/src/test/config.h b/libs/libmdbx/src/test/config.h index 86f37fbed8..2d0fede046 100644 --- a/libs/libmdbx/src/test/config.h +++ b/libs/libmdbx/src/test/config.h @@ -63,6 +63,10 @@ bool parse_option(int argc, char *const argv[], int &narg, const char *option, std::string &value, bool allow_empty = false); bool parse_option(int argc, char *const argv[], int &narg, const char *option, + std::string &value, bool allow_empty, + const char *default_value); + +bool parse_option(int argc, char *const argv[], int &narg, const char *option, bool &value); struct option_verb { @@ -75,16 +79,25 @@ bool parse_option(int argc, char *const argv[], int &narg, const char *option, bool parse_option(int argc, char *const argv[], int &narg, const char *option, uint64_t &value, const scale_mode scale, - const uint64_t minval = 0, const uint64_t maxval = INT64_MAX); + const uint64_t minval = 0, const uint64_t maxval = INT64_MAX, + const uint64_t default_value = 0); bool parse_option(int argc, char *const argv[], int &narg, const char *option, unsigned &value, const scale_mode scale, - const unsigned minval = 0, const unsigned maxval = INT32_MAX); + const unsigned minval = 0, const unsigned maxval = INT32_MAX, + const unsigned default_value = 0); bool parse_option(int argc, char *const argv[], int &narg, const char *option, uint8_t &value, const uint8_t minval = 0, - const uint8_t maxval = 255); + const uint8_t maxval = 255, const uint8_t default_value = 0); + +bool parse_option(int argc, char *const argv[], int &narg, const char *option, + int64_t &value, const int64_t minval, const int64_t maxval, + const int64_t default_value = -1); +bool parse_option(int argc, char *const argv[], int &narg, const char *option, + int32_t &value, const int32_t minval, const int32_t maxval, + const int32_t default_value = -1); //----------------------------------------------------------------------------- #pragma pack(push, 1) @@ -121,6 +134,8 @@ struct keygen_params_pod { * Иначе говоря, нет смысла в со-координации генерации паттернов для * ключей и значений. Более того, генерацию значений всегда необходимо * рассматривать в контексте связки с одним значением ключа. + * - Тем не менее, во всех случаях достаточно важным является равномерная + * всех возможных сочетаний длин ключей и данных. * * width: * Большинство тестов предполагают создание или итерирование некоторого @@ -156,7 +171,7 @@ struct keygen_params_pod { * псевдо-случайные значений ключей без псевдо-случайности в значениях. * * Такое ограничение соответствуют внутренней алгоритмике libmdbx. Проще - * говоря мы можем проверить движок псевдо-случайной последовательностью + * говоря, мы можем проверить движок псевдо-случайной последовательностью * ключей на таблицах без дубликатов (без multi-value), а затем проверить * корректность работу псевдо-случайной последовательностью значений на * таблицах с дубликатами (с multi-value), опционально добавляя @@ -203,7 +218,12 @@ struct actor_params_pod { unsigned mode_flags; unsigned table_flags; - uint64_t size; + intptr_t size_lower; + intptr_t size_now; + intptr_t size_upper; + int shrink_threshold; + int growth_step; + int pagesize; unsigned test_duration; unsigned test_nops; @@ -246,6 +266,11 @@ struct actor_params : public config::actor_params_pod { std::string pathname_log; std::string pathname_db; void set_defaults(const std::string &tmpdir); + + unsigned mdbx_keylen_min() const; + unsigned mdbx_keylen_max() const; + unsigned mdbx_datalen_min() const; + unsigned mdbx_datalen_max() const; }; struct actor_config : public config::actor_config_pod { diff --git a/libs/libmdbx/src/test/gc.sh b/libs/libmdbx/src/test/gc.sh new file mode 100644 index 0000000000..bddd92af24 --- /dev/null +++ b/libs/libmdbx/src/test/gc.sh @@ -0,0 +1,81 @@ +#!/bin/bash +set -euo pipefail +make check +TESTDB_PREFIX=${1:-/dev/shm/mdbx-gc-test}. + +function rep9 { printf "%*s" $1 '' | tr ' ' '9'; } +function join { local IFS="$1"; shift; echo "$*"; } +function bit2option { local -n arr=$1; (( ($2&(1<<$3)) != 0 )) && echo -n '+' || echo -n '-'; echo "${arr[$3]}"; } + +options=(writemap coalesce lifo) + +function bits2list { + local -n arr=$1 + local i + local list=() + for ((i=0; i<${#arr[@]}; ++i)) do + list[$i]=$(bit2option $1 $2 $i) + done + join , "${list[@]}" +} + +function probe { + echo "=============================================== $(date)" + echo "${caption}: $*" + rm -f ${TESTDB_PREFIX}* \ + && ./mdbx_test --pathname=${TESTDB_PREFIX}db "$@" | lz4 > log.lz4 \ + && ./mdbx_chk -nvvv ${TESTDB_PREFIX}db | tee ${TESTDB_PREFIX}chk \ + || (echo "FAILED"; exit 1) +} + +############################################################################### + +caption="Failfast #1" probe \ + --pagesize=min --size=6G --table=+data.dups --keylen.min=min --keylen.max=max --datalen.min=min --datalen.max=max \ + --nops=99999 --batch.write=9 --mode=-writemap,-coalesce,+lifo --keygen.seed=248240655 --hill + +caption="Failfast #2" probe \ + --pagesize=min --size=6G --table=-data.dups --keylen.min=min --keylen.max=max --datalen.min=min --datalen.max=1111 \ + --nops=999999 --batch.write=999 --mode=+writemap,+coalesce,+lifo --keygen.seed=259083046 --hill + +caption="Failfast #3" probe \ + --pagesize=min --size=6G --table=-data.dups --keylen.min=min --keylen.max=max --datalen.min=min --datalen.max=1111 \ + --nops=999999 --batch.write=999 --mode=+writemap,+coalesce,+lifo --keygen.seed=522365681 --hill + +caption="Failfast #4" probe \ + --pagesize=min --size=6G --table=-data.dups --keylen.min=min --keylen.max=max --datalen.min=min --datalen.max=1111 \ + --nops=999999 --batch.write=9999 --mode=-writemap,+coalesce,+lifo --keygen.seed=866083781 --hill + +caption="Failfast #5" probe \ + --pagesize=min --size=6G --table=-data.dups --keylen.min=min --keylen.max=max --datalen.min=min --datalen.max=1111 \ + --nops=999999 --batch.write=999 --mode=+writemap,-coalesce,+lifo --keygen.seed=246539192 --hill + +caption="Failfast #6" probe \ + --pagesize=min --size=6G --table=-data.dups --keylen.min=min --keylen.max=max --datalen.min=min --datalen.max=1111 \ + --nops=999999 --batch.write=999 --mode=+writemap,+coalesce,+lifo --keygen.seed=540406278 --hill + +caption="Failfast #7" probe \ + --pagesize=min --size=6G --table=+data.dups --keylen.min=min --keylen.max=max --datalen.min=min --datalen.max=max \ + --nops=999999 --batch.write=999 --mode=-writemap,+coalesce,+lifo --keygen.seed=619798690 --hill + +count=0 +for nops in {2..7}; do + for ((wbatch=nops-1; wbatch > 0; --wbatch)); do + loops=$((1111/nops + 2)) + for ((rep=0; rep++ < loops; )); do + for ((bits=2**${#options[@]}; --bits >= 0; )); do + seed=$(date +%N) + caption="Probe #$((++count)) w/o-dups, repeat ${rep} of ${loops}" probe \ + --pagesize=min --size=6G --table=-data.dups --keylen.min=min --keylen.max=max --datalen.min=min --datalen.max=1111 \ + --nops=$( rep9 $nops ) --batch.write=$( rep9 $wbatch ) --mode=$(bits2list options $bits) \ + --keygen.seed=${seed} --hill + caption="Probe #$((++count)) with-dups, repeat ${rep} of ${loops}" probe \ + --pagesize=min --size=6G --table=+data.dups --keylen.min=min --keylen.max=max --datalen.min=min --datalen.max=max \ + --nops=$( rep9 $nops ) --batch.write=$( rep9 $wbatch ) --mode=$(bits2list options $bits) \ + --keygen.seed=${seed} --hill + done + done + done +done + +echo "=== ALL DONE ====================== $(date)" diff --git a/libs/libmdbx/src/test/hill.cc b/libs/libmdbx/src/test/hill.cc index c9115784d4..0193c4f2f5 100644 --- a/libs/libmdbx/src/test/hill.cc +++ b/libs/libmdbx/src/test/hill.cc @@ -65,7 +65,9 @@ bool testcase_hill::run() { ? MDBX_NODUPDATA : MDBX_NODUPDATA | MDBX_NOOVERWRITE; const unsigned update_flags = - MDBX_CURRENT | MDBX_NODUPDATA | MDBX_NOOVERWRITE; + (config.params.table_flags & MDBX_DUPSORT) + ? MDBX_CURRENT | MDBX_NODUPDATA | MDBX_NOOVERWRITE + : MDBX_NODUPDATA; uint64_t serial_count = 0; unsigned txn_nops = 0; @@ -115,7 +117,7 @@ bool testcase_hill::run() { rc = mdbx_replace(txn_guard.get(), dbi, &a_key->value, &a_data_0->value, &a_data_1->value, update_flags); if (unlikely(rc != MDBX_SUCCESS)) - failure_perror("mdbx_put(update-a: 1->0)", rc); + failure_perror("mdbx_replace(update-a: 1->0)", rc); if (++txn_nops >= config.params.batch_write) { txn_restart(false, false); @@ -156,8 +158,6 @@ bool testcase_hill::run() { a_serial); generate_pair(a_serial, a_key, a_data_0, 0); generate_pair(a_serial, a_key, a_data_1, age_shift); - if (a_serial == 808) - log_trace("!!!"); int rc = mdbx_replace(txn_guard.get(), dbi, &a_key->value, &a_data_1->value, &a_data_0->value, update_flags); if (unlikely(rc != MDBX_SUCCESS)) diff --git a/libs/libmdbx/src/test/keygen.cc b/libs/libmdbx/src/test/keygen.cc index 99b46f2976..0b68194dc1 100644 --- a/libs/libmdbx/src/test/keygen.cc +++ b/libs/libmdbx/src/test/keygen.cc @@ -30,7 +30,7 @@ serial_t injective(const serial_t serial, /* LY: All these "magic" prime numbers were found * and verified with a bit of brute force. */ - static const uint64_t m[64 - serial_minwith] = { + static const uint64_t m[64 - serial_minwith + 1] = { /* 8 - 24 */ 113, 157, 397, 653, 1753, 5641, 9697, 23873, 25693, 80833, 105953, 316937, 309277, 834497, 1499933, 4373441, 10184137, @@ -43,26 +43,31 @@ serial_t injective(const serial_t serial, 2420886491930041, 3601632139991929, 11984491914483833, 21805846439714153, 23171543400565993, 53353226456762893, 155627817337932409, 227827205384840249, 816509268558278821, 576933057762605689, - 2623957345935638441, 5048241705479929949, 4634245581946485653}; - static const uint8_t s[64 - serial_minwith] = { + 2623957345935638441, 5048241705479929949, 4634245581946485653, + 4613509448041658233, 4952535426879925961}; + static const uint8_t s[64 - serial_minwith + 1] = { /* 8 - 24 */ 2, 3, 4, 4, 2, 4, 3, 3, 7, 3, 3, 4, 8, 3, 10, 3, 11, /* 25 - 64 */ 11, 9, 9, 9, 11, 10, 5, 14, 11, 16, 14, 12, 13, 16, 19, 10, 10, 21, 7, 20, - 10, 14, 22, 19, 3, 21, 18, 19, 26, 24, 2, 21, 25, 29, 24, 10, 11, 14}; + 10, 14, 22, 19, 3, 21, 18, 19, 26, 24, 2, 21, 25, 29, 24, 10, 11, 14, 20, + 19}; - serial_t result = serial * m[bits - 8]; + const auto mult = m[bits - 8]; + const auto shift = s[bits - 8]; + serial_t result = serial * mult; if (salt) { const unsigned left = bits / 2; const unsigned right = bits - left; result = (result << left) | ((result & mask(bits)) >> right); - result = (result ^ salt) * m[bits - 8]; + result = (result ^ salt) * mult; } - result ^= result << s[bits - 8]; + result ^= result << shift; result &= mask(bits); - log_trace("keygen-injective: serial %" PRIu64 " into %" PRIu64, serial, - result); + log_trace("keygen-injective: serial %" PRIu64 "/%u @%" PRIx64 ",%u,%" PRIu64 + " => %" PRIu64 "/%u", + serial, bits, mult, shift, salt, result, bits); return result; } @@ -73,8 +78,9 @@ void __hot maker::pair(serial_t serial, const buffer &key, buffer &value, assert(mapping.mesh <= mapping.width); assert(mapping.rotate <= mapping.width); assert(mapping.offset <= mask(mapping.width)); - assert(!(key_essentials.flags & (MDBX_INTEGERDUP | MDBX_REVERSEDUP))); - assert(!(value_essentials.flags & (MDBX_INTEGERKEY | MDBX_REVERSEKEY))); + assert(!(key_essentials.flags & + ~(MDBX_INTEGERKEY | MDBX_REVERSEKEY | MDBX_DUPSORT))); + assert(!(value_essentials.flags & ~(MDBX_INTEGERDUP | MDBX_REVERSEDUP))); log_trace("keygen-pair: serial %" PRIu64 ", data-age %" PRIu64, serial, value_age); @@ -82,31 +88,49 @@ void __hot maker::pair(serial_t serial, const buffer &key, buffer &value, if (mapping.mesh >= serial_minwith) { serial = (serial & ~mask(mapping.mesh)) | injective(serial, mapping.mesh, salt); - log_trace("keygen-pair: mesh %" PRIu64, serial); + log_trace("keygen-pair: mesh@%u => %" PRIu64, mapping.mesh, serial); } if (mapping.rotate) { const unsigned right = mapping.rotate; const unsigned left = mapping.width - right; serial = (serial << left) | ((serial & mask(mapping.width)) >> right); - log_trace("keygen-pair: rotate %" PRIu64 ", 0x%" PRIx64, serial, serial); + log_trace("keygen-pair: rotate@%u => %" PRIu64 ", 0x%" PRIx64, + mapping.rotate, serial, serial); } - serial = (serial + mapping.offset) & mask(mapping.width); - log_trace("keygen-pair: offset %" PRIu64, serial); - serial += base; + if (mapping.offset) { + serial = (serial + mapping.offset) & mask(mapping.width); + log_trace("keygen-pair: offset@%" PRIu64 " => %" PRIu64, mapping.offset, + serial); + } + if (base) { + serial += base; + log_trace("keygen-pair: base@%" PRIu64 " => %" PRIu64, base, serial); + } serial_t key_serial = serial; - serial_t value_serial = value_age; + serial_t value_serial = value_age << mapping.split; if (mapping.split) { - key_serial = serial >> mapping.split; - value_serial = - (serial & mask(mapping.split)) | (value_age << mapping.split); + if (key_essentials.flags & MDBX_DUPSORT) { + key_serial >>= mapping.split; + value_serial += serial & mask(mapping.split); + } else { + /* Без MDBX_DUPSORT требуется уникальность ключей, а для этого нельзя + * отбрасывать какие-либо биты serial после инъективного преобразования. + * Поэтому key_serial не трогаем, а в value_serial нелинейно вмешиваем + * запрошенное количество бит из serial */ + value_serial += + (serial ^ (serial >> mapping.split)) & mask(mapping.split); + } + + value_serial |= value_age << mapping.split; + log_trace("keygen-pair: split@%u => k%" PRIu64 ", v%" PRIu64, mapping.split, + key_serial, value_serial); } log_trace("keygen-pair: key %" PRIu64 ", value %" PRIu64, key_serial, value_serial); - mk(key_serial, key_essentials, *key); mk(value_serial, value_essentials, *value); @@ -121,17 +145,17 @@ void __hot maker::pair(serial_t serial, const buffer &key, buffer &value, void maker::setup(const config::actor_params_pod &actor, unsigned thread_number) { key_essentials.flags = - actor.table_flags & (MDBX_INTEGERKEY | MDBX_REVERSEKEY); - assert(actor.keylen_min < UINT8_MAX); + actor.table_flags & (MDBX_INTEGERKEY | MDBX_REVERSEKEY | MDBX_DUPSORT); + assert(actor.keylen_min <= UINT8_MAX); key_essentials.minlen = (uint8_t)actor.keylen_min; - assert(actor.keylen_max < UINT16_MAX); + assert(actor.keylen_max <= UINT16_MAX); key_essentials.maxlen = (uint16_t)actor.keylen_max; value_essentials.flags = actor.table_flags & (MDBX_INTEGERDUP | MDBX_REVERSEDUP); - assert(actor.datalen_min < UINT8_MAX); + assert(actor.datalen_min <= UINT8_MAX); value_essentials.minlen = (uint8_t)actor.datalen_min; - assert(actor.datalen_max < UINT16_MAX); + assert(actor.datalen_max <= UINT16_MAX); value_essentials.maxlen = (uint16_t)actor.datalen_max; assert(thread_number < 2); @@ -165,7 +189,7 @@ bool maker::increment(serial_t &serial, int delta) { //----------------------------------------------------------------------------- -size_t length(serial_t serial) { +static size_t length(serial_t serial) { size_t n = 0; if (serial > UINT32_MAX) { n = 4; @@ -199,7 +223,10 @@ void __hot maker::mk(const serial_t serial, const essentials ¶ms, assert(params.maxlen >= length(serial)); out.value.iov_base = out.bytes; - out.value.iov_len = params.minlen; + out.value.iov_len = + (params.maxlen > params.minlen) + ? params.minlen + serial % (params.maxlen - params.minlen) + : params.minlen; if (params.flags & (MDBX_INTEGERKEY | MDBX_INTEGERDUP)) { assert(params.maxlen == params.minlen); diff --git a/libs/libmdbx/src/test/keygen.h b/libs/libmdbx/src/test/keygen.h index c1e907bc0b..449165ae9a 100644 --- a/libs/libmdbx/src/test/keygen.h +++ b/libs/libmdbx/src/test/keygen.h @@ -44,7 +44,7 @@ namespace keygen { * - абсолютное значение ключей или разность между отдельными значениями; * * Соответственно, в общих чертах, схема генерации следующая: - * - вводится плоская одномерная "координата" uint64_t; + * - вводится плоская одномерная "координата" serial (uint64_t); * - генерация специфических паттернов (последовательностей) * реализуется посредством соответствующих преобразований "координат", при * этом все подобные преобразования выполняются только над "координатой"; @@ -74,7 +74,7 @@ typedef uint64_t serial_t; enum : serial_t { serial_minwith = 8, serial_maxwith = sizeof(serial_t) * 8, - serial_allones = ~(serial_t)0 + serial_allones = ~(serial_t)0u }; struct result { @@ -85,6 +85,10 @@ struct result { uint32_t u32; uint64_t u64; }; + + std::string as_string() const { + return std::string((const char *)value.iov_base, value.iov_len); + } }; //----------------------------------------------------------------------------- @@ -120,6 +124,4 @@ public: bool increment(serial_t &serial, int delta); }; -size_t length(serial_t serial); - } /* namespace keygen */ diff --git a/libs/libmdbx/src/test/log.cc b/libs/libmdbx/src/test/log.cc index 521e1d6900..7bc3ecf613 100644 --- a/libs/libmdbx/src/test/log.cc +++ b/libs/libmdbx/src/test/log.cc @@ -37,6 +37,31 @@ void __noreturn failure_perror(const char *what, int errnum) { //----------------------------------------------------------------------------- +static void mdbx_logger(int type, const char *function, int line, + const char *msg, va_list args) { + logging::loglevel level = logging::info; + if (type & MDBX_DBG_EXTRA) + level = logging::extra; + if (type & MDBX_DBG_TRACE) + level = logging::trace; + if (type & MDBX_DBG_PRINT) + level = logging::verbose; + + if (!function) + function = "unknown"; + if (type & MDBX_DBG_ASSERT) { + log_error("mdbx: assertion failure: %s, %d", function, line); + level = logging::failure; + } + + if (logging::output( + level, + strncmp(function, "mdbx_", 5) == 0 ? "%s: " : "mdbx: %s: ", function)) + logging::feed(msg, args); + if (type & MDBX_DBG_ASSERT) + abort(); +} + namespace logging { static std::string prefix; @@ -44,8 +69,19 @@ static std::string suffix; static loglevel level; static FILE *last; -void setup(loglevel _level, const std::string &_prefix) { +void setlevel(loglevel _level) { level = (_level > error) ? failure : _level; + int mdbx_dbg_opts = MDBX_DBG_ASSERT | MDBX_DBG_JITTER | MDBX_DBG_DUMP; + if (level <= trace) + mdbx_dbg_opts |= MDBX_DBG_TRACE; + if (level <= verbose) + mdbx_dbg_opts |= MDBX_DBG_PRINT; + int rc = mdbx_setup_debug(mdbx_dbg_opts, mdbx_logger); + log_trace("set mdbx debug-opts: 0x%02x", rc); +} + +void setup(loglevel _level, const std::string &_prefix) { + setlevel(_level); prefix = _prefix; } diff --git a/libs/libmdbx/src/test/log.h b/libs/libmdbx/src/test/log.h index e97e954cea..7350f1b9b1 100644 --- a/libs/libmdbx/src/test/log.h +++ b/libs/libmdbx/src/test/log.h @@ -17,16 +17,7 @@ #include "base.h" void __noreturn usage(void); - -#ifdef __GNUC__ -#define __printf_args(format_index, first_arg) \ - __attribute__((format(printf, format_index, first_arg))) -#else -#define __printf_args(format_index, first_arg) -#endif - void __noreturn __printf_args(1, 2) failure(const char *fmt, ...); - void __noreturn failure_perror(const char *what, int errnum); const char *test_strerror(int errnum); @@ -46,6 +37,7 @@ enum loglevel { const char *level2str(const loglevel level); void setup(loglevel level, const std::string &prefix); void setup(const std::string &prefix); +void setlevel(loglevel level); bool output(const loglevel priority, const char *format, va_list ap); bool __printf_args(2, 3) diff --git a/libs/libmdbx/src/test/main.cc b/libs/libmdbx/src/test/main.cc index bc3198ed3a..7493ab75c3 100644 --- a/libs/libmdbx/src/test/main.cc +++ b/libs/libmdbx/src/test/main.cc @@ -1,4 +1,4 @@ -/* +/* * Copyright 2017-2018 Leonid Yuriev <leo@yuriev.ru> * and other libmdbx authors: please see AUTHORS file. * All rights reserved. @@ -35,25 +35,31 @@ void actor_params::set_defaults(const std::string &tmpdir) { mode_flags = MDBX_NOSUBDIR | MDBX_WRITEMAP | MDBX_MAPASYNC | MDBX_NORDAHEAD | MDBX_NOMEMINIT | MDBX_COALESCE | MDBX_LIFORECLAIM; table_flags = MDBX_DUPSORT; - size = 1024 * 1024 * 4; + + size_lower = -1; + size_now = 1024 * 1024 * ((table_flags & MDBX_DUPSORT) ? 4 : 256); + size_upper = -1; + shrink_threshold = -1; + growth_step = -1; + pagesize = -1; keygen.seed = 1; keygen.keycase = kc_random; - keygen.width = 32; - keygen.mesh = 32; + keygen.width = (table_flags & MDBX_DUPSORT) ? 32 : 64; + keygen.mesh = keygen.width; keygen.split = keygen.width / 2; - keygen.rotate = 0; - keygen.offset = 0; + keygen.rotate = 3; + keygen.offset = 41; test_duration = 0; test_nops = 1000; nrepeat = 1; nthreads = 1; - keylen_min = 0; - keylen_max = 42; - datalen_min = 0; - datalen_max = 256; + keylen_min = mdbx_keylen_min(); + keylen_max = mdbx_keylen_max(); + datalen_min = mdbx_datalen_min(); + datalen_max = std::min(mdbx_datalen_max(), 256u * 1024 + 42); batch_read = 4; batch_write = 4; @@ -150,8 +156,45 @@ int main(int argc, char *const argv[]) { if (config::parse_option(argc, argv, narg, "table", params.table_flags, config::table_bits)) continue; - if (config::parse_option(argc, argv, narg, "size", params.size, - config::binary, 4096 * 4)) + + if (config::parse_option(argc, argv, narg, "pagesize", params.pagesize, + mdbx_limits_pgsize_min(), + mdbx_limits_pgsize_max())) { + const unsigned keylen_max = params.mdbx_keylen_max(); + if (params.keylen_min > keylen_max) + params.keylen_min = keylen_max; + if (params.keylen_max > keylen_max) + params.keylen_max = keylen_max; + const unsigned datalen_max = params.mdbx_datalen_max(); + if (params.datalen_min > datalen_max) + params.datalen_min = datalen_max; + if (params.datalen_max > datalen_max) + params.datalen_max = datalen_max; + continue; + } + if (config::parse_option(argc, argv, narg, "size-lower", params.size_lower, + mdbx_limits_dbsize_min(params.pagesize), + mdbx_limits_dbsize_max(params.pagesize))) + continue; + if (config::parse_option(argc, argv, narg, "size", params.size_now, + mdbx_limits_dbsize_min(params.pagesize), + mdbx_limits_dbsize_max(params.pagesize))) + continue; + if (config::parse_option(argc, argv, narg, "size-upper", params.size_upper, + mdbx_limits_dbsize_min(params.pagesize), + mdbx_limits_dbsize_max(params.pagesize))) + continue; + if (config::parse_option( + argc, argv, narg, "shrink-threshold", params.shrink_threshold, 0, + (int)std::min((intptr_t)INT_MAX, + mdbx_limits_dbsize_max(params.pagesize) - + mdbx_limits_dbsize_min(params.pagesize)))) + continue; + if (config::parse_option( + argc, argv, narg, "growth-step", params.growth_step, 0, + (int)std::min((intptr_t)INT_MAX, + mdbx_limits_dbsize_max(params.pagesize) - + mdbx_limits_dbsize_min(params.pagesize)))) continue; if (config::parse_option(argc, argv, narg, "keygen.width", @@ -188,20 +231,39 @@ int main(int argc, char *const argv[]) { config::duration, 1)) continue; if (config::parse_option(argc, argv, narg, "keylen.min", params.keylen_min, - config::no_scale, 0, params.keylen_max)) + config::no_scale, params.mdbx_keylen_min(), + params.mdbx_keylen_max())) { + if ((params.table_flags & MDBX_INTEGERKEY) || + params.keylen_max < params.keylen_min) + params.keylen_max = params.keylen_min; continue; + } if (config::parse_option(argc, argv, narg, "keylen.max", params.keylen_max, - config::no_scale, params.keylen_min, - mdbx_get_maxkeysize(0))) + config::no_scale, params.mdbx_keylen_min(), + params.mdbx_keylen_max())) { + if ((params.table_flags & MDBX_INTEGERKEY) || + params.keylen_min > params.keylen_max) + params.keylen_min = params.keylen_max; continue; + } if (config::parse_option(argc, argv, narg, "datalen.min", - params.datalen_min, config::no_scale, 0, - params.datalen_max)) + params.datalen_min, config::no_scale, + params.mdbx_datalen_min(), + params.mdbx_datalen_max())) { + if ((params.table_flags & MDBX_DUPFIXED) || + params.datalen_max < params.datalen_min) + params.datalen_max = params.datalen_min; continue; + } if (config::parse_option(argc, argv, narg, "datalen.max", params.datalen_max, config::no_scale, - params.datalen_min, MDBX_MAXDATASIZE)) + params.mdbx_datalen_min(), + params.mdbx_datalen_max())) { + if ((params.table_flags & MDBX_DUPFIXED) || + params.datalen_min > params.datalen_max) + params.datalen_min = params.datalen_max; continue; + } if (config::parse_option(argc, argv, narg, "batch.read", params.batch_read, config::no_scale, 1)) continue; diff --git a/libs/libmdbx/src/test/osal-windows.cc b/libs/libmdbx/src/test/osal-windows.cc index 109c835a96..b8cdb53513 100644 --- a/libs/libmdbx/src/test/osal-windows.cc +++ b/libs/libmdbx/src/test/osal-windows.cc @@ -53,7 +53,7 @@ void osal_wait4barrier(void) { } } -static HANDLE make_inharitable(HANDLE hHandle) { +static HANDLE make_inheritable(HANDLE hHandle) { assert(hHandle != NULL && hHandle != INVALID_HANDLE_VALUE); if (!DuplicateHandle(GetCurrentProcess(), hHandle, GetCurrentProcess(), &hHandle, 0, TRUE, @@ -71,7 +71,7 @@ void osal_setup(const std::vector<actor_config> &actors) { HANDLE hEvent = CreateEvent(NULL, TRUE, FALSE, NULL); if (!hEvent) failure_perror("CreateEvent()", GetLastError()); - hEvent = make_inharitable(hEvent); + hEvent = make_inheritable(hEvent); log_trace("osal_setup: event %" PRIuPTR " -> %p", i, hEvent); events[i] = hEvent; } @@ -79,12 +79,12 @@ void osal_setup(const std::vector<actor_config> &actors) { hBarrierSemaphore = CreateSemaphore(NULL, 0, (LONG)actors.size(), NULL); if (!hBarrierSemaphore) failure_perror("CreateSemaphore(BarrierSemaphore)", GetLastError()); - hBarrierSemaphore = make_inharitable(hBarrierSemaphore); + hBarrierSemaphore = make_inheritable(hBarrierSemaphore); hBarrierEvent = CreateEvent(NULL, TRUE, FALSE, NULL); if (!hBarrierEvent) failure_perror("CreateEvent(BarrierEvent)", GetLastError()); - hBarrierEvent = make_inharitable(hBarrierEvent); + hBarrierEvent = make_inheritable(hBarrierEvent); } void osal_broadcast(unsigned id) { diff --git a/libs/libmdbx/src/test/test.cc b/libs/libmdbx/src/test/test.cc index 3750af525f..c28bbd221e 100644 --- a/libs/libmdbx/src/test/test.cc +++ b/libs/libmdbx/src/test/test.cc @@ -68,31 +68,6 @@ const char *keygencase2str(const keygen_case keycase) { //----------------------------------------------------------------------------- -static void mdbx_logger(int type, const char *function, int line, - const char *msg, va_list args) { - logging::loglevel level = logging::info; - if (type & MDBX_DBG_EXTRA) - level = logging::extra; - if (type & MDBX_DBG_TRACE) - level = logging::trace; - if (type & MDBX_DBG_PRINT) - level = logging::verbose; - - if (!function) - function = "unknown"; - if (type & MDBX_DBG_ASSERT) { - log_error("mdbx: assertion failure: %s, %d", function, line); - level = logging::failure; - } - - if (logging::output( - level, - strncmp(function, "mdbx_", 5) == 0 ? "%s: " : "mdbx: %s: ", function)) - logging::feed(msg, args); - if (type & MDBX_DBG_ASSERT) - abort(); -} - int testcase::oom_callback(MDBX_env *env, int pid, mdbx_tid_t tid, uint64_t txn, unsigned gap, int retry) { @@ -117,16 +92,8 @@ void testcase::db_prepare() { log_trace(">> db_prepare"); assert(!db_guard); - int mdbx_dbg_opts = MDBX_DBG_ASSERT | MDBX_DBG_JITTER | MDBX_DBG_DUMP; - if (config.params.loglevel <= logging::trace) - mdbx_dbg_opts |= MDBX_DBG_TRACE; - if (config.params.loglevel <= logging::verbose) - mdbx_dbg_opts |= MDBX_DBG_PRINT; - int rc = mdbx_setup_debug(mdbx_dbg_opts, mdbx_logger); - log_trace("set mdbx debug-opts: 0x%02x", rc); - MDBX_env *env = nullptr; - rc = mdbx_env_create(&env); + int rc = mdbx_env_create(&env); if (unlikely(rc != MDBX_SUCCESS)) failure_perror("mdbx_env_create()", rc); @@ -149,7 +116,10 @@ void testcase::db_prepare() { if (unlikely(rc != MDBX_SUCCESS)) failure_perror("mdbx_env_set_oomfunc()", rc); - rc = mdbx_env_set_mapsize(env, (size_t)config.params.size); + rc = mdbx_env_set_geometry( + env, config.params.size_lower, config.params.size_now, + config.params.size_upper, config.params.growth_step, + config.params.shrink_threshold, config.params.pagesize); if (unlikely(rc != MDBX_SUCCESS)) failure_perror("mdbx_env_set_mapsize()", rc); diff --git a/libs/libmdbx/src/test/utils.cc b/libs/libmdbx/src/test/utils.cc index 0855c7eef3..53a750e314 100644 --- a/libs/libmdbx/src/test/utils.cc +++ b/libs/libmdbx/src/test/utils.cc @@ -93,7 +93,7 @@ bool hex2data(const char *hex_begin, const char *hex_end, void *ptr, //----------------------------------------------------------------------------- -/* TODO: replace my 'libmera' fomr t1ha. */ +/* TODO: replace my 'libmera' from t1ha. */ uint64_t entropy_ticks(void) { #if defined(EMSCRIPTEN) return (uint64_t)emscripten_get_now(); |