1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
|
<!-- Required extensions: pymdownx.betterem, pymdownx.tilde, pymdownx.emoji, pymdownx.tasklist, pymdownx.superfences -->
libmdbx
=======
_libmdbx_ is an extremely fast, compact, powerful, embedded,
transactional [key-value store](https://en.wikipedia.org/wiki/Key-value_database)
database, with [permissive license](LICENSE).
_MDBX_ has a specific set of properties and capabilities,
focused on creating unique lightweight solutions with extraordinary performance.
1. Allows **swarm of multi-threaded processes to
[ACID]((https://en.wikipedia.org/wiki/ACID))ly read and update** several
key-value [maps](https://en.wikipedia.org/wiki/Associative_array) and
[multimaps](https://en.wikipedia.org/wiki/Multimap) in a localy-shared
database.
2. Provides **extraordinary performance**, minimal overhead through
[Memory-Mapping](https://en.wikipedia.org/wiki/Memory-mapped_file) and
`Olog(N)` operations costs by virtue of [B+
tree](https://en.wikipedia.org/wiki/B%2B_tree).
3. Requires **no maintenance and no crash recovery** since doesn't use
[WAL](https://en.wikipedia.org/wiki/Write-ahead_logging), but that might
be a caveat for write-intensive workloads with durability requirements.
4. **Compact and friendly for fully embeddeding**. Only 25KLOC of `C11`,
64K x86 binary code, no internal threads neither processes, but
implements a simplified variant of the [Berkeley
DB](https://en.wikipedia.org/wiki/Berkeley_DB) and
[dbm](https://en.wikipedia.org/wiki/DBM_(computing)) API.
5. Enforces [serializability](https://en.wikipedia.org/wiki/Serializability) for
writers just by single
[mutex](https://en.wikipedia.org/wiki/Mutual_exclusion) and affords
[wait-free](https://en.wikipedia.org/wiki/Non-blocking_algorithm#Wait-freedom)
for parallel readers without atomic/interlocked operations, while
**writing and reading transactions do not block each other**.
6. **Guarantee data integrity** after crash unless this was explicitly
neglected in favour of write performance.
7. Supports Linux, Windows, MacOS, Android, iOS, FreeBSD, DragonFly, Solaris,
OpenSolaris, OpenIndiana, NetBSD, OpenBSD and other systems compliant with
**POSIX.1-2008**.
Historically, _MDBX_ is deeply revised and extended descendant of amazing
[Lightning Memory-Mapped Database](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database).
_MDBX_ inherits all benefits from _LMDB_, but resolves some issues and adds set of improvements.
The next version is under active non-public development from scratch and will be
released as **_MithrilDB_** and `libmithrildb` for libraries & packages.
Admittedly mythical [Mithril](https://en.wikipedia.org/wiki/Mithril) is
resembling silver but being stronger and lighter than steel. Therefore
_MithrilDB_ is rightly relevant name.
> _MithrilDB_ will be radically different from _libmdbx_ by the new
> database format and API based on C++17, as well as the [Apache 2.0
> License](https://www.apache.org/licenses/LICENSE-2.0). The goal of this
> revolution is to provide a clearer and robust API, add more features and
> new valuable properties of database.
[](https://t.me/libmdbx)
[](https://travis-ci.org/erthink/libmdbx)
[](https://ci.appveyor.com/project/erthink/libmdbx/branch/master)
[](https://scan.coverity.com/projects/reopen-libmdbx)
*The Future will (be) [Positive](https://www.ptsecurity.com). Всё будет хорошо.*
-----
## Table of Contents
- [Overview](#overview)
- [Features](#features)
- [Limitations](#limitations)
- [Caveats & Gotchas](#caveats--gotchas)
- [Comparison with other databases](#comparison-with-other-databases)
- [Improvements beyond LMDB](#improvements-beyond-lmdb)
- [History & Acknowledgments](#history)
- [Usage](#usage)
- [Building](#building)
- [API description](#api-description)
- [Bindings](#bindings)
- [Performance comparison](#performance-comparison)
- [Integral performance](#integral-performance)
- [Read scalability](#read-scalability)
- [Sync-write mode](#sync-write-mode)
- [Lazy-write mode](#lazy-write-mode)
- [Async-write mode](#async-write-mode)
- [Cost comparison](#cost-comparison)
# Overview
## Features
- Key-value data model, keys are always sorted.
- Fully [ACID](https://en.wikipedia.org/wiki/ACID)-compliant, through to
[MVCC](https://en.wikipedia.org/wiki/Multiversion_concurrency_control)
and [CoW](https://en.wikipedia.org/wiki/Copy-on-write).
- Multiple key-value sub-databases within a single datafile.
- Range lookups, including range query estimation.
- Efficient support for short fixed length keys, including native 32/64-bit integers.
- Ultra-efficient support for [multimaps](https://en.wikipedia.org/wiki/Multimap). Multi-values sorted, searchable and iterable. Keys stored without duplication.
- Data is [memory-mapped](https://en.wikipedia.org/wiki/Memory-mapped_file) and accessible directly/zero-copy. Traversal of database records is extremely-fast.
- Transactions for readers and writers, ones do not block others.
- Writes are strongly serialized. No transactions conflicts nor deadlocks.
- Readers are [non-blocking](https://en.wikipedia.org/wiki/Non-blocking_algorithm), notwithstanding [snapshot isolation](https://en.wikipedia.org/wiki/Snapshot_isolation).
- Nested write transactions.
- Reads scales linearly across CPUs.
- Continuous zero-overhead database compactification.
- Automatic on-the-fly database size adjustment.
- Customizable database page size.
- `Olog(N)` cost of lookup, insert, update, and delete operations by virtue of [B+ tree characteristics](https://en.wikipedia.org/wiki/B%2B_tree#Characteristics).
- Online hot backup.
- Append operation for efficient bulk insertion of pre-sorted data.
- No [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) nor any
transaction journal. No crash recovery needed. No maintenance is required.
- No internal cache and/or memory management, all done by basic OS services.
## Limitations
- **Page size**: a power of 2, maximum `65536` bytes, default `4096` bytes.
- **Key size**: minimum 0, maximum ≈¼ pagesize (`1300` bytes for default 4K pagesize, `21780` bytes for 64K pagesize).
- **Value size**: minimum 0, maximum `2146435072` (`0x7FF00000`) bytes for maps, ≈¼ pagesize for multimaps (`1348` bytes default 4K pagesize, `21828` bytes for 64K pagesize).
- **Write transaction size**: up to `4194301` (`0x3FFFFD`) pages (16 [GiB](https://en.wikipedia.org/wiki/Gibibyte) for default 4K pagesize, 256 [GiB](https://en.wikipedia.org/wiki/Gibibyte) for 64K pagesize).
- **Database size**: up to `2147483648` pages (8 [TiB](https://en.wikipedia.org/wiki/Tebibyte) for default 4K pagesize, 128 [TiB](https://en.wikipedia.org/wiki/Tebibyte) for 64K pagesize).
- **Maximum sub-databases**: `32765`.
## Caveats & Gotchas
1. There cannot be more than one writer at a time, i.e. no more than one write transaction at a time.
2. MDBX is based on [B+ tree](https://en.wikipedia.org/wiki/B%2B_tree), so access to database pages is mostly random.
Thus SSDs provide a significant performance boost over spinning disks for large databases.
3. MDBX uses [shadow paging](https://en.wikipedia.org/wiki/Shadow_paging) instead of [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging). Thus syncing data to disk might be bottleneck for write intensive workload.
4. MDBX uses [copy-on-write](https://en.wikipedia.org/wiki/Copy-on-write) for [snapshot isolation](https://en.wikipedia.org/wiki/Snapshot_isolation) during updates, but read transactions prevents recycling an old retired/freed pages, since it read ones. Thus altering of data during a parallel
long-lived read operation will increase the process work set, may exhaust entire free database space,
the database can grow quickly, and result in performance degradation.
Try to avoid long running read transactions.
5. MDBX is extraordinarily fast and provides minimal overhead for data access,
so you should reconsider about use brute force techniques and double check your code.
On the one hand, in the case of MDBX, a simple linear search may be more profitable than complex indexes.
On the other hand, if you make something suboptimally, you can notice a detrimentally only on sufficiently large data.
### Comparison with other databases
For now please refer to [chapter of "BoltDB comparison with other
databases"](https://github.com/coreos/bbolt#comparison-with-other-databases)
which is also (mostly) applicable to _libmdbx_.
Improvements beyond LMDB
========================
_libmdbx_ is superior to legendary _[LMDB](https://symas.com/lmdb/)_ in
terms of features and reliability, not inferior in performance. In
comparison to _LMDB_, _libmdbx_ make things "just work" perfectly and
out-of-the-box, not silently and catastrophically break down. The list
below is pruned down to the improvements most notable and obvious from
the user's point of view.
### Added Features:
1. Keys could be more than 2 times longer than _LMDB_.
> For DB with default page size _libmdbx_ support keys up to 1300 bytes
> and up to 21780 bytes for 64K page size. _LMDB_ allows key size up to
> 511 bytes and may silently loses data with large values.
2. Up to 20% faster than _LMDB_ in [CRUD](https://en.wikipedia.org/wiki/Create,_read,_update_and_delete) benchmarks.
> Benchmarks of the in-[tmpfs](https://en.wikipedia.org/wiki/Tmpfs) scenarios,
> that tests the speed of engine itself, shown that _libmdbx_ 10-20% faster than _LMDB_.
> These and other results could be easily reproduced with [ioArena](https://github.com/pmwkaa/ioarena) just by `make bench-quartet`,
> including comparisons with [RockDB](https://en.wikipedia.org/wiki/RocksDB)
> and [WiredTiger](https://en.wikipedia.org/wiki/WiredTiger).
3. Automatic on-the-fly database size adjustment, both increment and reduction.
> _libmdbx_ manage the database size according to parameters specified
> by `mdbx_env_set_geometry()` function,
> ones include the growth step and the truncation threshold.
>
> Unfortunately, on-the-fly database size adjustment doesn't work under [Wine](https://en.wikipedia.org/wiki/Wine_(software))
> due to its internal limitations and unimplemented functions, i.e. the `MDBX_UNABLE_EXTEND_MAPSIZE` error will be returned.
4. Automatic continuous zero-overhead database compactification.
> During each commit _libmdbx_ merges suitable freeing pages into unallocated area
> at the end of file, and then truncate unused space when a lot enough of.
5. The same database format for 32- and 64-bit builds.
> _libmdbx_ database format depends only on the [endianness](https://en.wikipedia.org/wiki/Endianness) but not on the [bitness](https://en.wiktionary.org/wiki/bitness).
6. LIFO policy for Garbage Collection recycling. This can significantly increase write performance due write-back disk cache up to several times in a best case scenario.
> LIFO means that for reuse will be taken latest became unused pages.
> Therefore the loop of database pages circulation becomes as short as possible.
> In other words, the set of pages, that are (over)written in memory and on disk during a series of write transactions, will be as small as possible.
> Thus creates ideal conditions for the battery-backed or flash-backed disk cache efficiency.
7. Fast estimation of range query result volume, i.e. how many items can
be found between a `KEY1` and a `KEY2`. This is prerequisite for build
and/or optimize query execution plans.
> _libmdbx_ performs a rough estimate based on common B-tree pages of the paths from root to corresponding keys.
8. `mdbx_chk` tool for database integrity check.
9. Automated steady sync-to-disk upon several thresholds and/or timeout via cheap polling.
10. Sequence generation and three persistent 64-bit markers.
11. Callback for lack-of-space condition of database that allows you to control and/or resolve such situations.
12. Support for opening database in the exclusive mode, including on a network share.
### Added Abilities:
1. Zero-length for keys and values.
2. Ability to determine whether the particular data is on a dirty page
or not, that allows to avoid copy-out before updates.
3. Ability to determine whether the cursor is pointed to a key-value
pair, to the first, to the last, or not set to anything.
4. Extended information of whole-database, sub-databases, transactions, readers enumeration.
> _libmdbx_ provides a lot of information, including dirty and leftover pages
> for a write transaction, reading lag and holdover space for read transactions.
5. Extended update and delete operations.
> _libmdbx_ allows ones _at once_ with getting previous value
> and addressing the particular item from multi-value with the same key.
### Other fixes and specifics:
1. Fixed more than 10 significant errors, in particular: page leaks, wrong sub-database statistics, segfault in several conditions, unoptimal page merge strategy, updating an existing record with a change in data size (including for multimap), etc.
2. All cursors can be reused and should be closed explicitly, regardless ones were opened within write or read transaction.
3. Opening database handles are spared from race conditions and
pre-opening is not needed.
4. Returning `MDBX_EMULTIVAL` error in case of ambiguous update or delete.
5. Guarantee of database integrity even in asynchronous unordered write-to-disk mode.
> _libmdbx_ propose additional trade-off by implementing append-like manner for updates
> in `MDBX_SAFE_NOSYNC` and `MDBX_WRITEMAP|MDBX_MAPASYNC` modes, that avoid database corruption after a system crash
> contrary to LMDB. Nevertheless, the `MDBX_UTTERLY_NOSYNC` mode available to match LMDB behaviour,
> and for a special use-cases.
6. On **MacOS** the `fcntl(F_FULLFSYNC)` syscall is used _by
default_ to synchronize data with the disk, as this is [the only way to
guarantee data
durability](https://developer.apple.com/library/archive/documentation/System/Conceptual/ManPages_iPhoneOS/man2/fsync.2.html)
in case of power failure. Unfortunately, in scenarios with high write
intensity, the use of `F_FULLFSYNC` significant degrades performance
compared to LMDB, where the `fsync()` syscall is used. Therefore,
_libmdbx_ allows you to override this behavior by defining the
`MDBX_OSX_SPEED_INSTEADOF_DURABILITY=1` option while build the library.
7. On **Windows** the `LockFileEx()` syscall is used for locking, since
it allows place the database on network drives, and provides protection
against incompetent user actions (aka
[poka-yoke](https://en.wikipedia.org/wiki/Poka-yoke)). Therefore
_libmdbx_ may be a little lag in performance tests from LMDB where a
named mutexes are used.
### History
At first the development was carried out within the
[ReOpenLDAP](https://github.com/erthink/ReOpenLDAP) project. About a
year later _libmdbx_ was separated into standalone project, which was
[presented at Highload++ 2015
conference](http://www.highload.ru/2015/abstracts/1831.html).
Since 2017 _libmdbx_ is used in [Fast Positive Tables](https://github.com/erthink/libfpta),
and development is funded by [Positive Technologies](https://www.ptsecurity.com).
### Acknowledgments
Howard Chu <hyc@openldap.org> is the author of LMDB, from which
originated the MDBX in 2015.
Martin Hedenfalk <martin@bzero.se> is the author of `btree.c` code, which
was used for begin development of LMDB.
--------------------------------------------------------------------------------
Usage
=====
## Source code embedding
_libmdbx_ provides two official ways for integration in source code form:
1. Using the amalgamated source code.
> The amalgamated source code includes all files requires to build and
> use _libmdbx_, but not for testing _libmdbx_ itself.
2. Adding the complete original source code as a `git submodule`.
> This allows you to build as _libmdbx_ and testing tool.
> On the other hand, this way requires you to pull git tags, and use C++11 compiler for test tool.
**_Please, avoid using any other techniques._** Otherwise, at least
don't ask for support and don't name such chimeras `libmdbx`.
The amalgamated source code could be created from original clone of git
repository on Linux by executing `make dist`. As a result, the desired
set of files will be formed in the `dist` subdirectory.
## Building
Both amalgamated and original source code provides build through the use
[CMake](https://cmake.org/) or [GNU
Make](https://www.gnu.org/software/make/) with
[bash](https://en.wikipedia.org/wiki/Bash_(Unix_shell)). All build ways
are completely traditional and have minimal prerequirements like
`build-essential`, i.e. the non-obsolete C/C++ compiler and a
[SDK](https://en.wikipedia.org/wiki/Software_development_kit) for the
target platform. Obviously you need building tools itself, i.e. `git`,
`cmake` or GNU `make` with `bash`.
So just use CMake or GNU Make in your habitual manner and feel free to
fill an issue or make pull request in the case something will be
unexpected or broken down.
#### DSO/DLL unloading and destructors of Thread-Local-Storage objects
When building _libmdbx_ as a shared library or use static _libmdbx_ as a
part of another dynamic library, it is advisable to make sure that your
system ensures the correctness of the call destructors of
Thread-Local-Storage objects when unloading dynamic libraries.
If this is not the case, then unloading a dynamic-link library with
_libmdbx_ code inside, can result in either a resource leak or a crash
due to calling destructors from an already unloaded DSO/DLL object. The
problem can only manifest in a multithreaded application, which makes
the unloading of shared dynamic libraries with _libmdbx_ code inside,
after using _libmdbx_. It is known that TLS-destructors are properly
maintained in the following cases:
- On all modern versions of Windows (Windows 7 and later).
- On systems with the
[`__cxa_thread_atexit_impl()`](https://sourceware.org/glibc/wiki/Destructor%20support%20for%20thread_local%20variables)
function in the standard C library, including systems with GNU libc
version 2.18 and later.
- On systems with libpthread/ntpl from GNU libc with bug fixes
[#21031](https://sourceware.org/bugzilla/show_bug.cgi?id=21031) and
[#21032](https://sourceware.org/bugzilla/show_bug.cgi?id=21032), or
where there are no similar bugs in the pthreads implementation.
### Linux and other platforms with GNU Make
To build the library it is enough to execute `make all` in the directory
of source code, and `make check` for execute the basic tests.
If the `make` installed on the system is not GNU Make, there will be a
lot of errors from make when trying to build. In this case, perhaps you
should use `gmake` instead of `make`, or even `gnu-make`, etc.
### FreeBSD and related platforms
As a rule, in such systems, the default is to use Berkeley Make. And GNU
Make is called by the gmake command or may be missing. In addition,
[bash](https://en.wikipedia.org/wiki/Bash_(Unix_shell)) may be absent.
You need to install the required components: GNU Make, bash, C and C++
compilers compatible with GCC or CLANG. After that, to build the
library, it is enough execute `gmake all` (or `make all`) in the
directory with source code, and `gmake check` (or `make check`) to run
the basic tests.
### Windows
For build _libmdbx_ on Windows the _original_ CMake and [Microsoft Visual
Studio](https://en.wikipedia.org/wiki/Microsoft_Visual_Studio) are
recommended.
Building by MinGW, MSYS or Cygwin is potentially possible. However,
these scripts are not tested and will probably require you to modify the
CMakeLists.txt or Makefile respectively.
It should be noted that in _libmdbx_ was efforts to resolve
runtime dependencies from CRT and other libraries Visual Studio.
For this is enough define the `MDBX_AVOID_CRT` during build.
An example of running a basic test script can be found in the
[CI-script](appveyor.yml) for [AppVeyor](https://www.appveyor.com/). To
run the [long stochastic test scenario](test/long_stochastic.sh),
[bash](https://en.wikipedia.org/wiki/Bash_(Unix_shell)) is required, and
the such testing is recommended with place the test data on the
[RAM-disk](https://en.wikipedia.org/wiki/RAM_drive).
### MacOS
Current [native build tools](https://en.wikipedia.org/wiki/Xcode) for
MacOS include GNU Make, CLANG and an outdated version of bash.
Therefore, to build the library, it is enough to run `make all` in the
directory with source code, and run `make check` to execute the base
tests. If something goes wrong, it is recommended to install
[Homebrew](https://brew.sh/) and try again.
To run the [long stochastic test scenario](test/long_stochastic.sh), you
will need to install the current (not outdated) version of
[bash](https://en.wikipedia.org/wiki/Bash_(Unix_shell)). To do this, we
recommend that you install [Homebrew](https://brew.sh/) and then execute
`brew install bash`.
### Android
We recommend using CMake to build _libmdbx_ for Android.
Please refer to the [official guide](https://developer.android.com/studio/projects/add-native-code).
### iOS
To build _libmdbx_ for iOS, we recommend using CMake with the
"[toolchain file](https://cmake.org/cmake/help/latest/variable/CMAKE_TOOLCHAIN_FILE.html)"
from the [ios-cmake](https://github.com/leetal/ios-cmake) project.
### Windows Subsystem for Linux
_libmdbx_ could be using in [WSL2](https://en.wikipedia.org/wiki/Windows_Subsystem_for_Linux#WSL_2)
but NOT in [WSL1](https://en.wikipedia.org/wiki/Windows_Subsystem_for_Linux#WSL_1) environment.
This is a consequence of the fundamental shortcomings of _WSL1_ and cannot be fixed.
To avoid data loss, _libmdbx_ returns the `ENOLCK` (37, "No record locks available")
error when opening the database in a _WSL1_ environment.
## API description
For more information and API description see the [mdbx.h](mdbx.h) header.
Please do not hesitate to point out errors in the documentation,
including creating [PR](https://help.github.com/en/github/collaborating-with-issues-and-pull-requests/proposing-changes-to-your-work-with-pull-requests) with corrections and improvements.
## Bindings
| Runtime | GitHub | Author |
| -------- | ------ | ------ |
| Rust | [mdbx-rs](https://github.com/Kerollmops/mdbx-rs) | [@Kerollmops](https://github.com/Kerollmops) |
| Java | [mdbxjni](https://github.com/castortech/mdbxjni) | [Castor Technologies](https://castortech.com/) |
| .NET | [mdbx.NET](https://github.com/wangjia184/mdbx.NET) | [Jerry Wang](https://github.com/wangjia184) |
--------------------------------------------------------------------------------
Performance comparison
======================
All benchmarks were done in 2015 by [IOArena](https://github.com/pmwkaa/ioarena)
and multiple [scripts](https://github.com/pmwkaa/ioarena/tree/HL%2B%2B2015)
runs on Lenovo Carbon-2 laptop, i7-4600U 2.1 GHz (2 physical cores, 4 HyperThreading cores), 8 Gb RAM,
SSD SAMSUNG MZNTD512HAGL-000L1 (DXT23L0Q) 512 Gb.
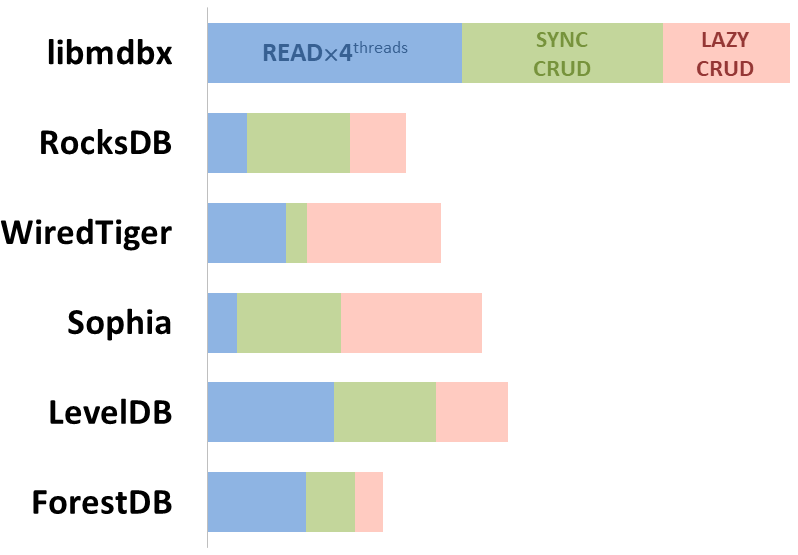
## Integral performance
Here showed sum of performance metrics in 3 benchmarks:
- Read/Search on machine with 4 logical CPU in HyperThreading mode (i.e. actually 2 physical CPU cores);
- Transactions with [CRUD](https://en.wikipedia.org/wiki/CRUD)
operations in sync-write mode (fdatasync is called after each
transaction);
- Transactions with [CRUD](https://en.wikipedia.org/wiki/CRUD)
operations in lazy-write mode (moment to sync data to persistent storage
is decided by OS).
*Reasons why asynchronous mode isn't benchmarked here:*
1. It doesn't make sense as it has to be done with DB engines, oriented
for keeping data in memory e.g. [Tarantool](https://tarantool.io/),
[Redis](https://redis.io/)), etc.
2. Performance gap is too high to compare in any meaningful way.
--------------------------------------------------------------------------------
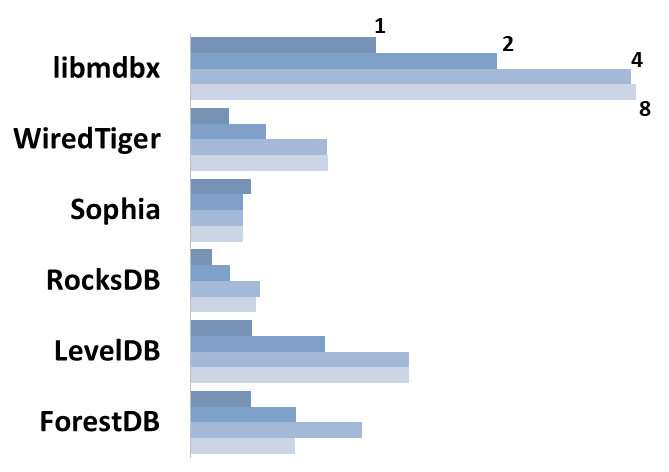
## Read Scalability
Summary performance with concurrent read/search queries in 1-2-4-8
threads on 4 CPU cores machine.
--------------------------------------------------------------------------------
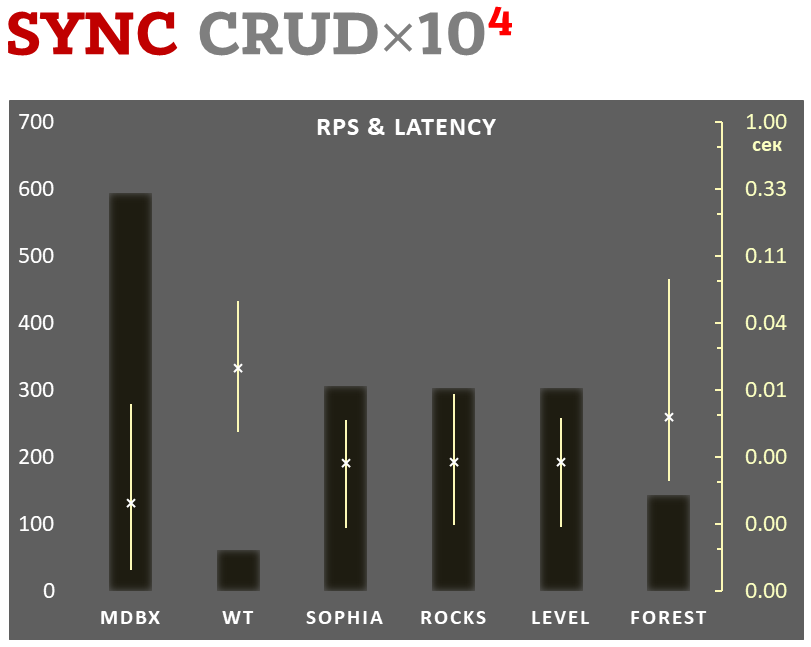
## Sync-write mode
- Linear scale on left and dark rectangles mean arithmetic mean
transactions per second;
- Logarithmic scale on right is in seconds and yellow intervals mean
execution time of transactions. Each interval shows minimal and maximum
execution time, cross marks standard deviation.
**10,000 transactions in sync-write mode**. In case of a crash all data
is consistent and state is right after last successful transaction.
[fdatasync](https://linux.die.net/man/2/fdatasync) syscall is used after
each write transaction in this mode.
In the benchmark each transaction contains combined CRUD operations (2
inserts, 1 read, 1 update, 1 delete). Benchmark starts on empty database
and after full run the database contains 10,000 small key-value records.
--------------------------------------------------------------------------------
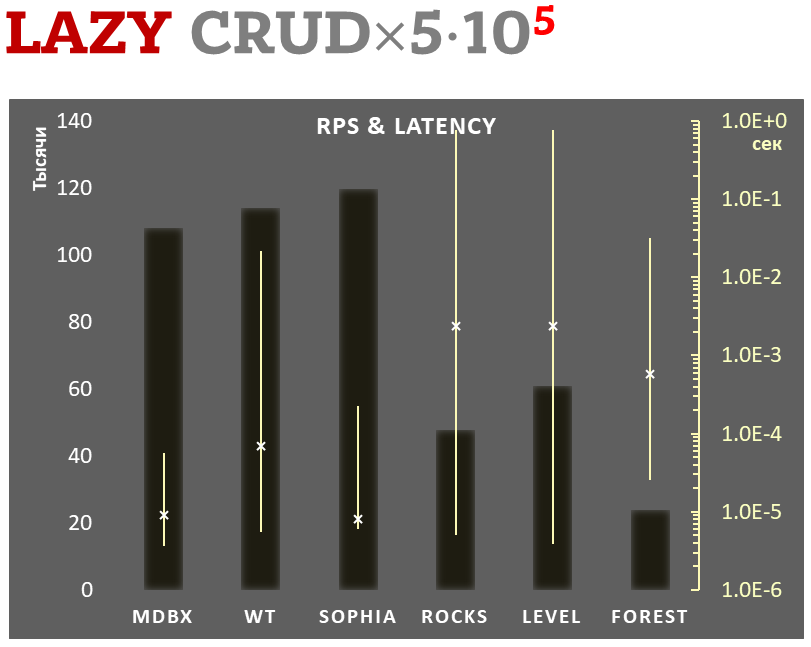
## Lazy-write mode
- Linear scale on left and dark rectangles mean arithmetic mean of
thousands transactions per second;
- Logarithmic scale on right in seconds and yellow intervals mean
execution time of transactions. Each interval shows minimal and maximum
execution time, cross marks standard deviation.
**100,000 transactions in lazy-write mode**. In case of a crash all data
is consistent and state is right after one of last transactions, but
transactions after it will be lost. Other DB engines use
[WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) or transaction
journal for that, which in turn depends on order of operations in
journaled filesystem. _libmdbx_ doesn't use WAL and hands I/O operations
to filesystem and OS kernel (mmap).
In the benchmark each transaction contains combined CRUD operations (2
inserts, 1 read, 1 update, 1 delete). Benchmark starts on empty database
and after full run the database contains 100,000 small key-value
records.
--------------------------------------------------------------------------------
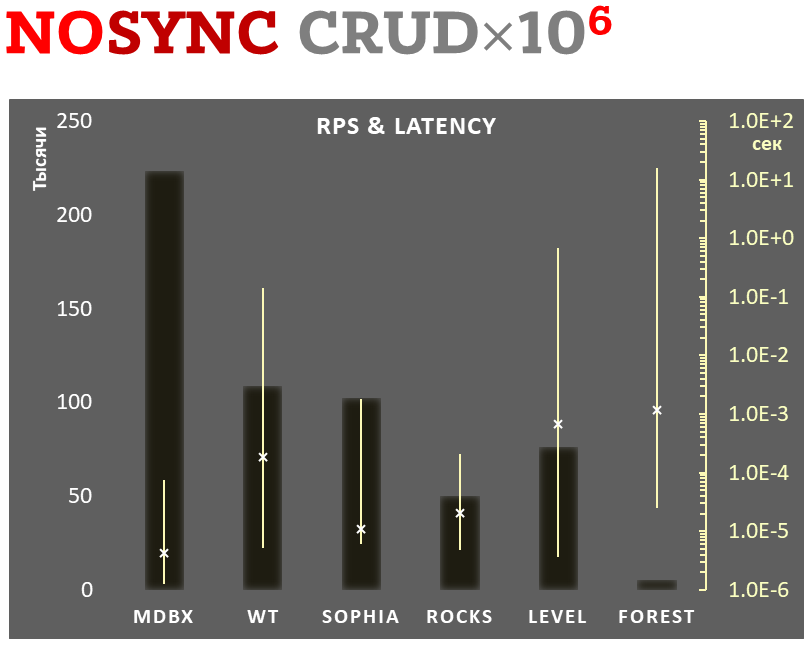
## Async-write mode
- Linear scale on left and dark rectangles mean arithmetic mean of
thousands transactions per second;
- Logarithmic scale on right in seconds and yellow intervals mean
execution time of transactions. Each interval shows minimal and maximum
execution time, cross marks standard deviation.
**1,000,000 transactions in async-write mode**. In case of a crash all
data will be consistent and state will be right after one of last
transactions, but lost transaction count is much higher than in
lazy-write mode. All DB engines in this mode do as little writes as
possible on persistent storage. _libmdbx_ uses
[msync(MS_ASYNC)](https://linux.die.net/man/2/msync) in this mode.
In the benchmark each transaction contains combined CRUD operations (2
inserts, 1 read, 1 update, 1 delete). Benchmark starts on empty database
and after full run the database contains 10,000 small key-value records.
--------------------------------------------------------------------------------
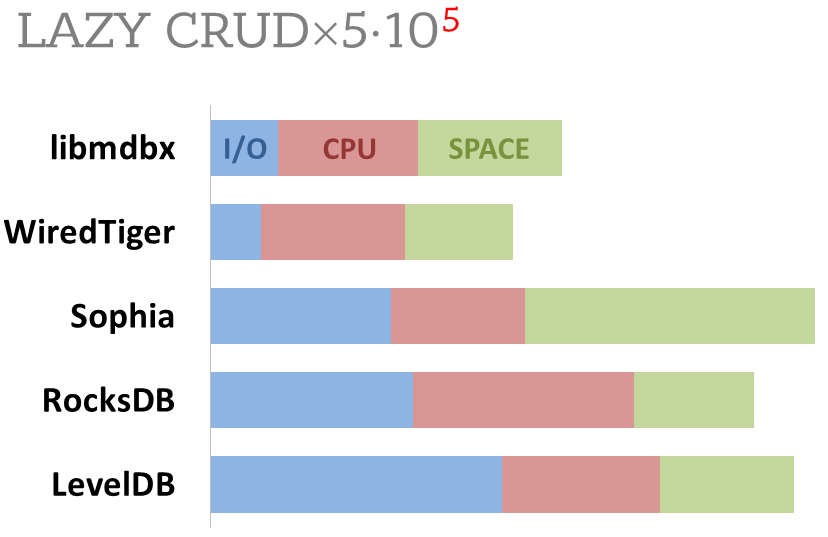
## Cost comparison
Summary of used resources during lazy-write mode benchmarks:
- Read and write IOPs;
- Sum of user CPU time and sys CPU time;
- Used space on persistent storage after the test and closed DB, but not
waiting for the end of all internal housekeeping operations (LSM
compactification, etc).
_ForestDB_ is excluded because benchmark showed it's resource
consumption for each resource (CPU, IOPs) much higher than other engines
which prevents to meaningfully compare it with them.
All benchmark data is gathered by
[getrusage()](http://man7.org/linux/man-pages/man2/getrusage.2.html)
syscall and by scanning data directory.
--------------------------------------------------------------------------------
#### This is a mirror of the origin repository that was moved to [abf.io](https://abf.io/erthink/) because of discriminatory restrictions for Russian Crimea.
|
