1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
|
libmdbx
======================================
**Revised and extended descendant of [Symas LMDB](https://symas.com/lmdb/).**
*The Future will be positive.*
[](https://travis-ci.org/leo-yuriev/libmdbx)
[](https://ci.appveyor.com/project/leo-yuriev/libmdbx/branch/master)
[](https://scan.coverity.com/projects/reopen-libmdbx)
## Project Status for now
- The stable versions ([_stable/0.0_](https://github.com/leo-yuriev/libmdbx/tree/stable/0.0) and [_stable/0.1_](https://github.com/leo-yuriev/libmdbx/tree/stable/0.1) branches) of _MDBX_ are frozen, i.e. no new features or API changes, but only bug fixes.
- The next version ([_devel_](https://github.com/leo-yuriev/libmdbx/tree/devel) branch) **is under active non-public development**, i.e. current API and set of features are extreme volatile.
- The immediate goal of development is formation of the stable API and the stable internal database format, which allows realise all PLANNED FEATURES:
1. Integrity check by [Merkle tree](https://en.wikipedia.org/wiki/Merkle_tree);
2. Support for [raw block devices](https://en.wikipedia.org/wiki/Raw_device);
3. Separate place (HDD) for large data items;
4. Using "[Roaring bitmaps](http://roaringbitmap.org/about/)" inside garbage collector;
5. Non-sequential reclaiming, like PostgreSQL's [Vacuum](https://www.postgresql.org/docs/9.1/static/sql-vacuum.html);
6. [Asynchronous lazy data flushing](https://sites.fas.harvard.edu/~cs265/papers/kathuria-2008.pdf) to disk(s);
7. etc...
Don't miss [Java Native Interface](https://github.com/castortech/mdbxjni) by [Castor Technologies](https://castortech.com/).
-----
Nowadays MDBX intended for Linux, and support Windows (since
Windows Server 2008) as a complementary platform. Support for
other OS could be implemented on commercial basis. However such
enhancements (i.e. pull requests) could be accepted in
mainstream only when corresponding public and free Continuous
Integration service will be available.
## Contents
- [Overview](#overview)
- [Comparison with other DBs](#comparison-with-other-dbs)
- [History & Acknowledgments](#history)
- [Main features](#main-features)
- [Performance comparison](#performance-comparison)
- [Integral performance](#integral-performance)
- [Read scalability](#read-scalability)
- [Sync-write mode](#sync-write-mode)
- [Lazy-write mode](#lazy-write-mode)
- [Async-write mode](#async-write-mode)
- [Cost comparison](#cost-comparison)
- [Gotchas](#gotchas)
- [Long-time read transactions problem](#long-time-read-transactions-problem)
- [Data safety in async-write-mode](#data-safety-in-async-write-mode)
- [Improvements over LMDB](#improvements-over-lmdb)
## Overview
_libmdbx_ is an embedded lightweight key-value database engine oriented for performance under Linux and Windows.
_libmdbx_ allows multiple processes to read and update several key-value tables concurrently,
while being [ACID](https://en.wikipedia.org/wiki/ACID)-compliant, with minimal overhead and operation cost of Olog(N).
_libmdbx_ provides
[serializability](https://en.wikipedia.org/wiki/Serializability) and consistency of data after crash.
Read-write transactions don't block read-only transactions and are
[serialized](https://en.wikipedia.org/wiki/Serializability) by [mutex](https://en.wikipedia.org/wiki/Mutual_exclusion).
_libmdbx_ [wait-free](https://en.wikipedia.org/wiki/Non-blocking_algorithm#Wait-freedom) provides parallel read transactions
without atomic operations or synchronization primitives.
_libmdbx_ uses [B+Trees](https://en.wikipedia.org/wiki/B%2B_tree) and [mmap](https://en.wikipedia.org/wiki/Memory-mapped_file),
doesn't use [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging). This might have caveats for some workloads.
### Comparison with other DBs
Because _libmdbx_ is currently overhauled, I think it's better to just link
[chapter of Comparison with other databases](https://github.com/coreos/bbolt#comparison-with-other-databases) here.
### History
The _libmdbx_ design is based on [Lightning Memory-Mapped Database](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database).
Initial development was going in [ReOpenLDAP](https://github.com/leo-yuriev/ReOpenLDAP) project, about a year later it
received separate development effort and in autumn 2015 was isolated to separate project, which was
[presented at Highload++ 2015 conference](http://www.highload.ru/2015/abstracts/1831.html).
Since early 2017 _libmdbx_ is used in [Fast Positive Tables](https://github.com/leo-yuriev/libfpta),
by [Positive Technologies](https://www.ptsecurity.com).
#### Acknowledgments
Howard Chu (Symas Corporation) - the author of LMDB,
from which originated the MDBX in 2015.
Martin Hedenfalk <martin@bzero.se> - the author of `btree.c` code,
which was used for begin development of LMDB.
Main features
=============
_libmdbx_ inherits all keys features and characteristics from
[LMDB](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database):
1. Data is stored in ordered map, keys are always sorted, range lookups are supported.
2. Data is [mmaped](https://en.wikipedia.org/wiki/Memory-mapped_file) to memory of each worker DB process, read transactions are zero-copy.
3. Transactions are [ACID](https://en.wikipedia.org/wiki/ACID)-compliant, thanks to
[MVCC](https://en.wikipedia.org/wiki/Multiversion_concurrency_control) and [CoW](https://en.wikipedia.org/wiki/Copy-on-write).
Writes are strongly serialized and aren't blocked by reads, transactions can't conflict with each other.
Reads are guaranteed to get only commited data
([relaxing serializability](https://en.wikipedia.org/wiki/Serializability#Relaxing_serializability)).
4. Reads and queries are [non-blocking](https://en.wikipedia.org/wiki/Non-blocking_algorithm),
don't use [atomic operations](https://en.wikipedia.org/wiki/Linearizability#High-level_atomic_operations).
Readers don't block each other and aren't blocked by writers. Read performance scales linearly with CPU core count.
> Though "connect to DB" (start of first read transaction in thread) and "disconnect from DB" (shutdown or thread
> termination) requires to acquire a lock to register/unregister current thread from "readers table"
5. Keys with multiple values are stored efficiently without key duplication, sorted by value, including integers
(reasonable for secondary indexes).
6. Efficient operation on short fixed length keys, including integer ones.
7. [WAF](https://en.wikipedia.org/wiki/Write_amplification) (Write Amplification Factor) и RAF (Read Amplification Factor)
are Olog(N).
8. No [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) and transaction journal.
In case of a crash no recovery needed. No need for regular maintenance. Backups can be made on the fly on working DB
without freezing writers.
9. No custom memory management, all done with standard OS syscalls.
Performance comparison
=====================
All benchmarks were done by [IOArena](https://github.com/pmwkaa/ioarena)
and multiple [scripts](https://github.com/pmwkaa/ioarena/tree/HL%2B%2B2015)
runs on Lenovo Carbon-2 laptop, i7-4600U 2.1 GHz, 8 Gb RAM,
SSD SAMSUNG MZNTD512HAGL-000L1 (DXT23L0Q) 512 Gb.
--------------------------------------------------------------------------------
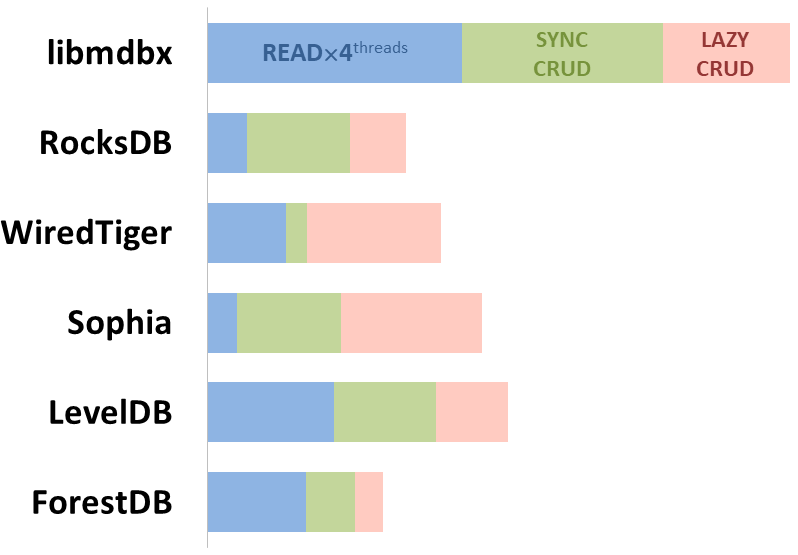
### Integral performance
Here showed sum of performance metrics in 3 benchmarks:
- Read/Search on 4 CPU cores machine;
- Transactions with [CRUD](https://en.wikipedia.org/wiki/CRUD) operations
in sync-write mode (fdatasync is called after each transaction);
- Transactions with [CRUD](https://en.wikipedia.org/wiki/CRUD) operations
in lazy-write mode (moment to sync data to persistent storage is decided by OS).
*Reasons why asynchronous mode isn't benchmarked here:*
1. It doesn't make sense as it has to be done with DB engines, oriented for keeping data in memory e.g.
[Tarantool](https://tarantool.io/), [Redis](https://redis.io/)), etc.
2. Performance gap is too high to compare in any meaningful way.
--------------------------------------------------------------------------------
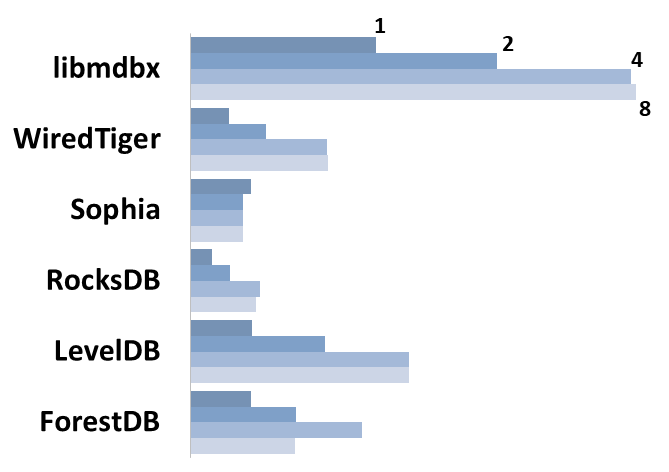
### Read Scalability
Summary performance with concurrent read/search queries in 1-2-4-8 threads on 4 CPU cores machine.
--------------------------------------------------------------------------------
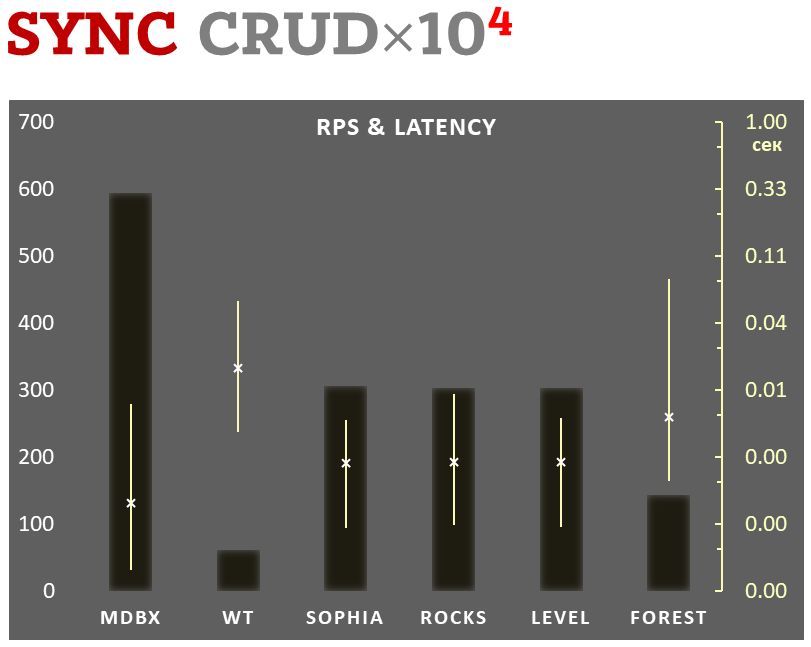
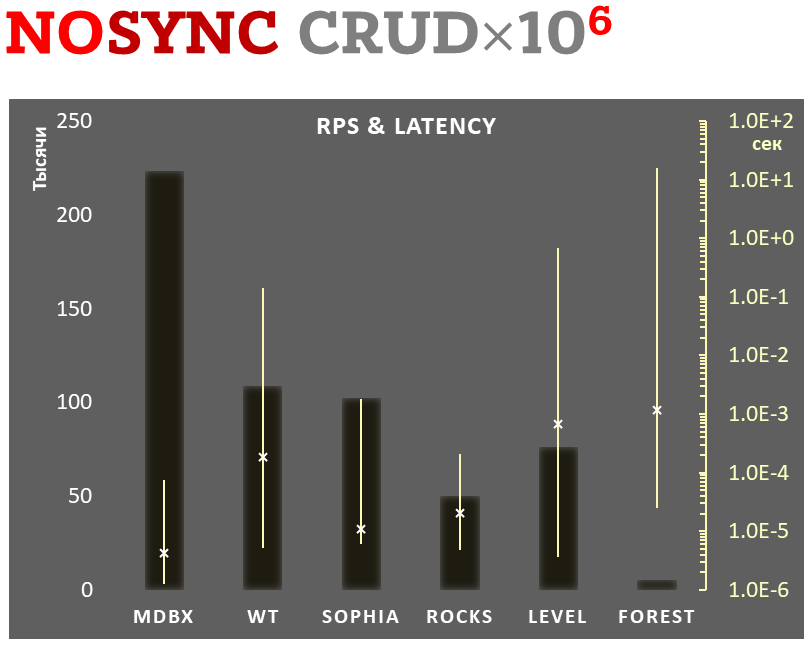
### Sync-write mode
- Linear scale on left and dark rectangles mean arithmetic mean transactions per second;
- Logarithmic scale on right is in seconds and yellow intervals mean execution time of transactions.
Each interval shows minimal and maximum execution time, cross marks standard deviation.
**10,000 transactions in sync-write mode**. In case of a crash all data is consistent and state is right after last successful transaction. [fdatasync](https://linux.die.net/man/2/fdatasync) syscall is used after each write transaction in this mode.
In the benchmark each transaction contains combined CRUD operations (2 inserts, 1 read, 1 update, 1 delete).
Benchmark starts on empty database and after full run the database contains 10,000 small key-value records.
--------------------------------------------------------------------------------
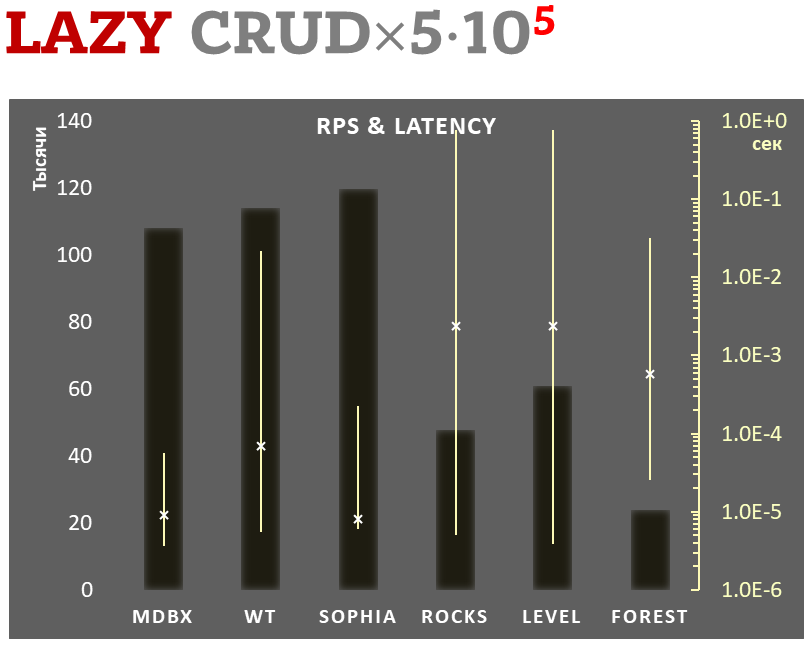
### Lazy-write mode
- Linear scale on left and dark rectangles mean arithmetic mean of thousands transactions per second;
- Logarithmic scale on right in seconds and yellow intervals mean execution time of transactions. Each interval shows minimal and maximum execution time, cross marks standard deviation.
**100,000 transactions in lazy-write mode**.
In case of a crash all data is consistent and state is right after one of last transactions, but transactions after it
will be lost. Other DB engines use [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) or transaction journal for that,
which in turn depends on order of operations in journaled filesystem. _libmdbx_ doesn't use WAL and hands I/O operations
to filesystem and OS kernel (mmap).
In the benchmark each transaction contains combined CRUD operations (2 inserts, 1 read, 1 update, 1 delete).
Benchmark starts on empty database and after full run the database contains 100,000 small key-value records.
--------------------------------------------------------------------------------
### Async-write mode
- Linear scale on left and dark rectangles mean arithmetic mean of thousands transactions per second;
- Logarithmic scale on right in seconds and yellow intervals mean execution time of transactions. Each interval shows minimal and maximum execution time, cross marks standard deviation.
**1,000,000 transactions in async-write mode**. In case of a crash all data will be consistent and state will be right after one of last transactions, but lost transaction count is much higher than in lazy-write mode. All DB engines in this mode do as little writes as possible on persistent storage. _libmdbx_ uses [msync(MS_ASYNC)](https://linux.die.net/man/2/msync) in this mode.
In the benchmark each transaction contains combined CRUD operations (2 inserts, 1 read, 1 update, 1 delete).
Benchmark starts on empty database and after full run the database contains 10,000 small key-value records.
--------------------------------------------------------------------------------
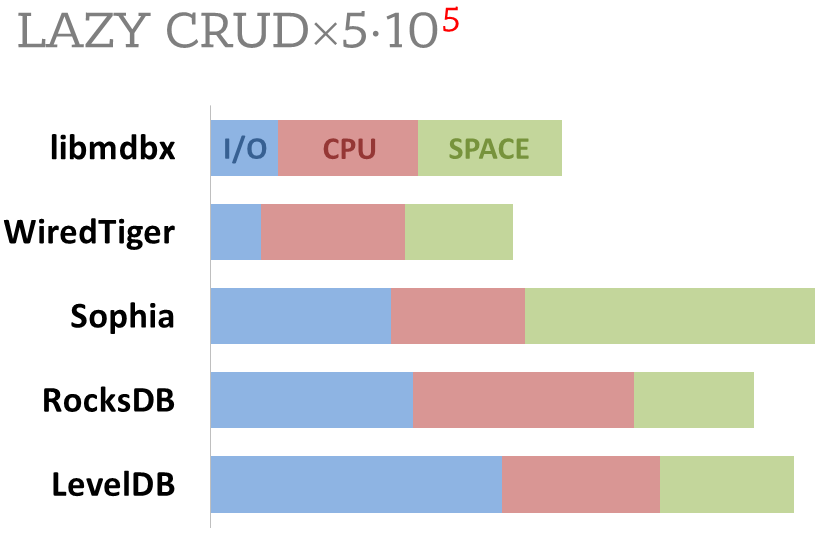
### Cost comparison
Summary of used resources during lazy-write mode benchmarks:
- Read and write IOPS;
- Sum of user CPU time and sys CPU time;
- Used space on persistent storage after the test and closed DB, but not waiting for the end of all internal
housekeeping operations (LSM compactification, etc).
_ForestDB_ is excluded because benchmark showed it's resource consumption for each resource (CPU, IOPS) much higher than other engines which prevents to meaningfully compare it with them.
All benchmark data is gathered by [getrusage()](http://man7.org/linux/man-pages/man2/getrusage.2.html) syscall and by
scanning data directory.
--------------------------------------------------------------------------------
## Gotchas
1. At one moment there can be only one writer. But this allows to serialize writes and eliminate any possibility
of conflict or logical errors during transaction rollback.
2. No [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) means relatively
big [WAF](https://en.wikipedia.org/wiki/Write_amplification) (Write Amplification Factor).
Because of this syncing data to disk might be quite resource intensive and be main performance bottleneck
during intensive write workload.
> As compromise _libmdbx_ allows several modes of lazy and/or periodic syncing, including `MAPASYNC` mode, which modificate
> data in memory and asynchronously syncs data to disk, moment to sync is picked by OS.
>
> Although this should be used with care, synchronous transactions in a DB with transaction journal will require 2 IOPS
> minimum (probably 3-4 in practice) because of filesystem overhead, overhead depends on filesystem, not on record
> count or record size. In _libmdbx_ IOPS count will grow logarithmically depending on record count in DB (height of B+ tree)
> and will require at least 2 IOPS per transaction too.
3. [CoW](https://en.wikipedia.org/wiki/Copy-on-write)
for [MVCC](https://en.wikipedia.org/wiki/Multiversion_concurrency_control) is done on memory page level with [B+
trees](https://ru.wikipedia.org/wiki/B-%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE).
Therefore altering data requires to copy about Olog(N) memory pages, which uses [memory bandwidth](https://en.wikipedia.org/wiki/Memory_bandwidth) and is main performance bottleneck in `MAPASYNC` mode.
> This is unavoidable, but isn't that bad. Syncing data to disk requires much more similar operations which will
> be done by OS, therefore this is noticeable only if data sync to persistent storage is fully disabled.
> _libmdbx_ allows to safely save data to persistent storage with minimal performance overhead. If there is no need
> to save data to persistent storage then it's much more preferable to use `std::map`.
4. LMDB has a problem of long-time readers which degrades performance and bloats DB
> _libmdbx_ addresses that, details below.
5. _LMDB_ is susceptible to DB corruption in `WRITEMAP+MAPASYNC` mode.
_libmdbx_ in `WRITEMAP+MAPASYNC` guarantees DB integrity and consistency of data.
> Additionally there is an alternative: `UTTERLY_NOSYNC` mode. Details below.
#### Long-time read transactions problem
Garbage collection problem exists in all databases one way or another (e.g. VACUUM in PostgreSQL).
But in _libmdbx_ and LMDB it's even more important because of high performance and deliberate
simplification of internals with emphasis on performance.
* Altering data during long read operation may exhaust available space on persistent storage.
* If available space is exhausted then any attempt to update data
results in `MAP_FULL` error until long read operation ends.
* Main examples of long readers is hot backup
and debugging of client application which actively uses read transactions.
* In _LMDB_ this results in degraded performance of all operations
of syncing data to persistent storage.
* _libmdbx_ has a mechanism which aborts such operations and `LIFO RECLAIM`
mode which addresses performance degradation.
Read operations operate only over snapshot of DB which is consistent on the moment when read transaction started.
This snapshot doesn't change throughout the transaction but this leads to inability to reclaim the pages until
read transaction ends.
In _LMDB_ this leads to a problem that memory pages, allocated for operations during long read, will be used for operations
and won't be reclaimed until DB process terminates. In _LMDB_ they are used in
[FIFO](https://en.wikipedia.org/wiki/FIFO_(computing_and_electronics)) manner, which causes increased page count
and less chance of cache hit during I/O. In other words: one long-time reader can impact performance of all database
until it'll be reopened.
_libmdbx_ addresses the problem, details below. Illustrations to this problem can be found in the
[presentation](http://www.slideshare.net/leoyuriev/lmdb). There is also example of performance increase thanks to
[BBWC](https://en.wikipedia.org/wiki/Disk_buffer#Write_acceleration) when `LIFO RECLAIM` enabled in _libmdbx_.
#### Data safety in async-write mode
In `WRITEMAP+MAPSYNC` mode dirty pages are written to persistent storage by kernel. This means that in case of application
crash OS kernel will write all dirty data to disk and nothing will be lost. But in case of hardware malfunction or OS kernel
fatal error only some dirty data might be synced to disk, and there is high probability that pages with metadata saved,
will point to non-saved, hence non-existent, data pages. In such situation, DB is completely corrupted and can't be
repaired even if there was full sync before the crash via `mdbx_env_sync().
_libmdbx_ addresses this by fully reimplementing write path of data:
* In `WRITEMAP+MAPSYNC` mode meta-data pages aren't updated in place, instead their shadow copies are used and their updates
are synced after data is flushed to disk.
* During transaction commit _libmdbx_ marks synchronization points as steady or weak depending on how much synchronization
needed between RAM and persistent storage, e.g. in `WRITEMAP+MAPSYNC` commited transactions are marked as weak,
but during explicit data synchronization - as steady.
* _libmdbx_ maintains three separate meta-pages instead of two. This allows to commit transaction with steady or
weak synchronization point without losing two previous synchronization points (one of them can be steady, and second - weak).
This allows to order weak and steady synchronization points in any order without losing consistency in case of system crash.
* During DB open _libmdbx_ rollbacks to the last steady synchronization point, this guarantees database integrity.
For data safety pages which form database snapshot with steady synchronization point must not be updated until next steady
synchronization point. So last steady synchronization point creates "long-time read" effect. The only difference that in case
of memory exhaustion the problem will be immediately addressed by flushing changes to persistent storage and forming new steady
synchronization point.
So in async-write mode _libmdbx_ will always use new pages until memory is exhausted or `mdbx_env_sync()` is invoked. Total
disk usage will be almost the same as in sync-write mode.
Current _libmdbx_ gives a choice of safe async-write mode (default) and `UTTERLY_NOSYNC` mode which may result in full DB
corruption during system crash as with LMDB.
Next version of _libmdbx_ will create steady synchronization points automatically in async-write mode.
--------------------------------------------------------------------------------
Improvements over LMDB
================================================
1. `LIFO RECLAIM` mode:
The newest pages are picked for reuse instead of the oldest.
This allows to minimize reclaim loop and make it execution time independent of total page count.
This results in OS kernel cache mechanisms working with maximum efficiency.
In case of using disk controllers or storages with
[BBWC](https://en.wikipedia.org/wiki/Disk_buffer#Write_acceleration) this may greatly improve
write performance.
2. `OOM-KICK` callback.
`mdbx_env_set_oomfunc()` allows to set a callback, which will be called
in the event of memory exhausting during long-time read transaction.
Callback will be invoked with PID and pthread_id of offending thread as parameters.
Callback can do any of these things to remedy the problem:
* wait for read transaction to finish normally;
* kill the offending process (signal 9), if separate process is doing long-time read;
* abort or restart offending read transaction if it's running in sibling thread;
* abort current write transaction with returning error code.
3. Guarantee of DB integrity in `WRITEMAP+MAPSYNC` mode:
> Current _libmdbx_ gives a choice of safe async-write mode (default)
> and `UTTERLY_NOSYNC` mode which may result in full
> DB corruption during system crash as with LMDB. For details see
> [Data safety in async-write mode](#data-safety-in-async-write-mode).
4. Automatic creation of synchronization points (flush changes to persistent storage)
when changes reach set threshold (threshold can be set by `mdbx_env_set_syncbytes()`).
5. Ability to get how far current read-only snapshot is from latest version of the DB by `mdbx_txn_straggler()`.
6. `mdbx_chk` tool for DB checking and `mdbx_env_pgwalk()` for page-walking all pages in DB.
7. Control over debugging and receiving of debugging messages via `mdbx_setup_debug()`.
8. Ability to assign up to 3 markers to commiting transaction with `mdbx_canary_put()` and then get them in read transaction
by `mdbx_canary_get()`.
9. Check if there is a row with data after current cursor position via `mdbx_cursor_eof()`.
10. Ability to explicitly request update of present record without creating new record. Implemented as `MDBX_CURRENT` flag
for `mdbx_put()`.
11. Ability to update or delete record and get previous value via `mdbx_replace()` Also can update specific multi-value.
12. Support for keys and values of zero length, including sorted duplicates.
13. Fixed `mdbx_cursor_count()`, which returns correct count of duplicated for all table types and any cursor position.
14. Ability to open DB in exclusive mode with `MDBX_EXCLUSIVE` flag, e.g. for integrity check.
15. Ability to close DB in "dirty" state (without data flush and creation of steady synchronization point)
via `mdbx_env_close_ex()`.
16. Ability to get additional info, including number of the oldest snapshot of DB, which is used by one of the readers.
Implemented via `mdbx_env_info()`.
17. `mdbx_del()` doesn't ignore additional argument (specifier) `data`
for tables without duplicates (without flag `MDBX_DUPSORT`), if `data` is not zero then always uses it to verify
record, which is being deleted.
18. Ability to open dbi-table with simultaneous setup of comparators for keys and values, via `mdbx_dbi_open_ex()`.
19. Ability to find out if key or value is in dirty page. This may be useful to make a decision to avoid
excessive CoW before updates. Implemented via `mdbx_is_dirty()`.
20. Correct update of current record in `MDBX_CURRENT` mode of `mdbx_cursor_put()`, including sorted duplicated.
21. All cursors in all read and write transactions can be reused by `mdbx_cursor_renew()` and MUST be freed explicitly.
> ## Caution, please pay attention!
>
> This is the only change of API, which changes semantics of cursor management
> and can lead to memory leaks on misuse. This is a needed change as it eliminates ambiguity
> which helps to avoid such errors as:
> - use-after-free;
> - double-free;
> - memory corruption and segfaults.
22. Additional error code `MDBX_EMULTIVAL`, which is returned by `mdbx_put()` and
`mdbx_replace()` in case is ambiguous update or delete.
23. Ability to get value by key and duplicates count by `mdbx_get_ex()`.
24. Functions `mdbx_cursor_on_first() and mdbx_cursor_on_last(), which allows to know if cursor is currently on first or
last position respectively.
25. If read transaction is aborted via `mdbx_txn_abort()` or `mdbx_txn_reset()` then DBI-handles, which were opened in it,
aren't closed or deleted. This allows to avoid several types of hard-to-debug errors.
26. Sequence generation via `mdbx_dbi_sequence()`.
27. Advanced dynamic control over DB size, including ability to choose page size via `mdbx_env_set_geometry()`,
including on Windows.
28. Three meta-pages instead of two, this allows to guarantee consistently update weak sync-points without risking to
corrupt last steady sync-point.
29. Automatic reclaim of freed pages to specific reserved space at the end of database file. This lowers amount of pages,
loaded to memory, used in update/flush loop. In fact _libmdbx_ constantly performs compactification of data,
but doesn't use additional resources for that. Space reclaim of DB and setup of database geometry parameters also decreases
size of the database on disk, including on Windows.
--------------------------------------------------------------------------------
```
$ objdump -f -h -j .text libmdbx.so
libmdbx.so: file format elf64-x86-64
architecture: i386:x86-64, flags 0x00000150:
HAS_SYMS, DYNAMIC, D_PAGED
start address 0x000030e0
Sections:
Idx Name Size VMA LMA File off Algn
11 .text 00014d84 00000000000030e0 00000000000030e0 000030e0 2**4
CONTENTS, ALLOC, LOAD, READONLY, CODE
```
```
$ gcc -v
Using built-in specs.
COLLECT_GCC=gcc
COLLECT_LTO_WRAPPER=/usr/lib/gcc/x86_64-linux-gnu/7/lto-wrapper
OFFLOAD_TARGET_NAMES=nvptx-none
OFFLOAD_TARGET_DEFAULT=1
Target: x86_64-linux-gnu
Configured with: ../src/configure -v --with-pkgversion='Ubuntu 7.2.0-8ubuntu3' --with-bugurl=file:///usr/share/doc/gcc-7/README.Bugs --enable-languages=c,ada,c++,go,brig,d,fortran,objc,obj-c++ --prefix=/usr --with-gcc-major-version-only --program-suffix=-7 --program-prefix=x86_64-linux-gnu- --enable-shared --enable-linker-build-id --libexecdir=/usr/lib --without-included-gettext --enable-threads=posix --libdir=/usr/lib --enable-nls --with-sysroot=/ --enable-clocale=gnu --enable-libstdcxx-debug --enable-libstdcxx-time=yes --with-default-libstdcxx-abi=new --enable-gnu-unique-object --disable-vtable-verify --enable-libmpx --enable-plugin --enable-default-pie --with-system-zlib --with-target-system-zlib --enable-objc-gc=auto --enable-multiarch --disable-werror --with-arch-32=i686 --with-abi=m64 --with-multilib-list=m32,m64,mx32 --enable-multilib --with-tune=generic --enable-offload-targets=nvptx-none --without-cuda-driver --enable-checking=release --build=x86_64-linux-gnu --host=x86_64-linux-gnu --target=x86_64-linux-gnu
Thread model: posix
gcc version 7.2.0 (Ubuntu 7.2.0-8ubuntu3)
```
|
