
diff options
| author | George Hazan <ghazan@miranda.im> | 2021-03-23 22:09:14 +0300 |
|---|---|---|
| committer | George Hazan <ghazan@miranda.im> | 2021-03-23 22:09:14 +0300 |
| commit | b63efb1fbceb4127c164377015889a979330a437 (patch) | |
| tree | b15fcca8b75021e3c6cb1e9fb519fff28cd37502 /plugins/Dbx_mdbx/src/libmdbx/README.md | |
| parent | 42143e9cf3719630ab370e9369764cdaac892821 (diff) | |
also for #2771 - removal of all MDBX utilities and libmdbx.mir itself
Diffstat (limited to 'plugins/Dbx_mdbx/src/libmdbx/README.md')
| -rw-r--r-- | plugins/Dbx_mdbx/src/libmdbx/README.md | 638 |
1 files changed, 638 insertions, 0 deletions
diff --git a/plugins/Dbx_mdbx/src/libmdbx/README.md b/plugins/Dbx_mdbx/src/libmdbx/README.md new file mode 100644 index 0000000000..66da37c454 --- /dev/null +++ b/plugins/Dbx_mdbx/src/libmdbx/README.md @@ -0,0 +1,638 @@ +<!-- Required extensions: pymdownx.betterem, pymdownx.tilde, pymdownx.emoji, pymdownx.tasklist, pymdownx.superfences --> + +> Please refer to the online [documentation](https://erthink.github.io/libmdbx/) +> with [`C` API description](https://erthink.github.io/libmdbx/group__c__api.html) +> and pay attention to the preliminary [`C++` API](https://github.com/erthink/libmdbx/blob/devel/mdbx.h%2B%2B). +> +> Questions, feedback and suggestions are welcome to the [Telegram' group](https://t.me/libmdbx). +> +> For NEWS take a look to the [ChangeLog](./ChangeLog.md). + +libmdbx +======== + +<!-- section-begin overview --> +_libmdbx_ is an extremely fast, compact, powerful, embedded, +transactional [key-value database](https://en.wikipedia.org/wiki/Key-value_database), +with [permissive license](./LICENSE). +_libmdbx_ has a specific set of properties and capabilities, +focused on creating unique lightweight solutions. + +1. Allows **a swarm of multi-threaded processes to +[ACID]((https://en.wikipedia.org/wiki/ACID))ly read and update** several +key-value [maps](https://en.wikipedia.org/wiki/Associative_array) and +[multimaps](https://en.wikipedia.org/wiki/Multimap) in a locally-shared +database. + +2. Provides **extraordinary performance**, minimal overhead through +[Memory-Mapping](https://en.wikipedia.org/wiki/Memory-mapped_file) and +`Olog(N)` operations costs by virtue of [B+ +tree](https://en.wikipedia.org/wiki/B%2B_tree). + +3. Requires **no maintenance and no crash recovery** since it doesn't use +[WAL](https://en.wikipedia.org/wiki/Write-ahead_logging), but that might +be a caveat for write-intensive workloads with durability requirements. + +4. **Compact and friendly for fully embedding**. Only ≈25KLOC of `C11`, +≈64K x86 binary code of core, no internal threads neither server process(es), +but implements a simplified variant of the [Berkeley +DB](https://en.wikipedia.org/wiki/Berkeley_DB) and +[dbm](https://en.wikipedia.org/wiki/DBM_(computing)) API. + +5. Enforces [serializability](https://en.wikipedia.org/wiki/Serializability) for +writers just by single +[mutex](https://en.wikipedia.org/wiki/Mutual_exclusion) and affords +[wait-free](https://en.wikipedia.org/wiki/Non-blocking_algorithm#Wait-freedom) +for parallel readers without atomic/interlocked operations, while +**writing and reading transactions do not block each other**. + +6. **Guarantee data integrity** after crash unless this was explicitly +neglected in favour of write performance. + +7. Supports Linux, Windows, MacOS, Android, iOS, FreeBSD, DragonFly, Solaris, +OpenSolaris, OpenIndiana, NetBSD, OpenBSD and other systems compliant with +**POSIX.1-2008**. +<!-- section-end --> + +Historically, _libmdbx_ is a deeply revised and extended descendant of the amazing +[Lightning Memory-Mapped Database](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database). +_libmdbx_ inherits all benefits from _LMDB_, but resolves some issues and adds [a set of improvements](#improvements-beyond-lmdb). + +<!-- section-begin mithril --> +The next version is under active non-public development from scratch and will be +released as _**MithrilDB**_ and `libmithrildb` for libraries & packages. +Admittedly mythical [Mithril](https://en.wikipedia.org/wiki/Mithril) is +resembling silver but being stronger and lighter than steel. Therefore +_MithrilDB_ is a rightly relevant name. + > _MithrilDB_ will be radically different from _libmdbx_ by the new + > database format and API based on C++17, as well as the [Apache 2.0 + > License](https://www.apache.org/licenses/LICENSE-2.0). The goal of this + > revolution is to provide a clearer and robust API, add more features and + > new valuable properties of the database. +<!-- section-end --> + +[](https://t.me/libmdbx) +[](https://github.com/erthink/libmdbx/actions?query=workflow%3ACI) +[](https://travis-ci.org/erthink/libmdbx) +[](https://ci.appveyor.com/project/leo-yuriev/libmdbx/branch/master) +[](https://circleci.com/gh/erthink/libmdbx/tree/master) +[](https://cirrus-ci.com/github/erthink/libmdbx) +[](https://scan.coverity.com/projects/reopen-libmdbx) + +*The Future will (be) [Positive](https://www.ptsecurity.com). Всё будет хорошо.* + +----- + +## Table of Contents +- [Characteristics](#characteristics) + - [Features](#features) + - [Limitations](#limitations) + - [Gotchas](#gotchas) + - [Comparison with other databases](#comparison-with-other-databases) + - [Improvements beyond LMDB](#improvements-beyond-lmdb) + - [History & Acknowledgments](#history) +- [Usage](#usage) + - [Building](#building) + - [API description](#api-description) + - [Bindings](#bindings) +- [Performance comparison](#performance-comparison) + - [Integral performance](#integral-performance) + - [Read scalability](#read-scalability) + - [Sync-write mode](#sync-write-mode) + - [Lazy-write mode](#lazy-write-mode) + - [Async-write mode](#async-write-mode) + - [Cost comparison](#cost-comparison) + +# Characteristics + +<!-- section-begin characteristics --> + +## Features + +- Key-value data model, keys are always sorted. + +- Fully [ACID](https://en.wikipedia.org/wiki/ACID)-compliant, through to +[MVCC](https://en.wikipedia.org/wiki/Multiversion_concurrency_control) +and [CoW](https://en.wikipedia.org/wiki/Copy-on-write). + +- Multiple key-value sub-databases within a single datafile. + +- Range lookups, including range query estimation. + +- Efficient support for short fixed length keys, including native 32/64-bit integers. + +- Ultra-efficient support for [multimaps](https://en.wikipedia.org/wiki/Multimap). Multi-values sorted, searchable and iterable. Keys stored without duplication. + +- Data is [memory-mapped](https://en.wikipedia.org/wiki/Memory-mapped_file) and accessible directly/zero-copy. Traversal of database records is extremely-fast. + +- Transactions for readers and writers, ones do not block others. + +- Writes are strongly serialized. No transaction conflicts nor deadlocks. + +- Readers are [non-blocking](https://en.wikipedia.org/wiki/Non-blocking_algorithm), notwithstanding [snapshot isolation](https://en.wikipedia.org/wiki/Snapshot_isolation). + +- Nested write transactions. + +- Reads scale linearly across CPUs. + +- Continuous zero-overhead database compactification. + +- Automatic on-the-fly database size adjustment. + +- Customizable database page size. + +- `Olog(N)` cost of lookup, insert, update, and delete operations by virtue of [B+ tree characteristics](https://en.wikipedia.org/wiki/B%2B_tree#Characteristics). + +- Online hot backup. + +- Append operation for efficient bulk insertion of pre-sorted data. + +- No [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) nor any +transaction journal. No crash recovery needed. No maintenance is required. + +- No internal cache and/or memory management, all done by basic OS services. + +## Limitations + +- **Page size**: a power of 2, maximum `65536` bytes, default `4096` bytes. +- **Key size**: minimum 0, maximum ≈¼ pagesize (`1300` bytes for default 4K pagesize, `21780` bytes for 64K pagesize). +- **Value size**: minimum 0, maximum `2146435072` (`0x7FF00000`) bytes for maps, ≈¼ pagesize for multimaps (`1348` bytes for default 4K pagesize, `21828` bytes for 64K pagesize). +- **Write transaction size**: up to `4194301` (`0x3FFFFD`) pages (16 [GiB](https://en.wikipedia.org/wiki/Gibibyte) for default 4K pagesize, 256 [GiB](https://en.wikipedia.org/wiki/Gibibyte) for 64K pagesize). +- **Database size**: up to `2147483648` pages (8 [TiB](https://en.wikipedia.org/wiki/Tebibyte) for default 4K pagesize, 128 [TiB](https://en.wikipedia.org/wiki/Tebibyte) for 64K pagesize). +- **Maximum sub-databases**: `32765`. + +## Gotchas + +1. There cannot be more than one writer at a time, i.e. no more than one write transaction at a time. + +2. _libmdbx_ is based on [B+ tree](https://en.wikipedia.org/wiki/B%2B_tree), so access to database pages is mostly random. +Thus SSDs provide a significant performance boost over spinning disks for large databases. + +3. _libmdbx_ uses [shadow paging](https://en.wikipedia.org/wiki/Shadow_paging) instead of [WAL](https://en.wikipedia.org/wiki/Write-ahead_logging). Thus syncing data to disk might be a bottleneck for write intensive workload. + +4. _libmdbx_ uses [copy-on-write](https://en.wikipedia.org/wiki/Copy-on-write) for [snapshot isolation](https://en.wikipedia.org/wiki/Snapshot_isolation) during updates, but read transactions prevents recycling an old retired/freed pages, since it read ones. Thus altering of data during a parallel +long-lived read operation will increase the process work set, may exhaust entire free database space, +the database can grow quickly, and result in performance degradation. +Try to avoid long running read transactions. + +5. _libmdbx_ is extraordinarily fast and provides minimal overhead for data access, +so you should reconsider using brute force techniques and double check your code. +On the one hand, in the case of _libmdbx_, a simple linear search may be more profitable than complex indexes. +On the other hand, if you make something suboptimally, you can notice detrimentally only on sufficiently large data. + +## Comparison with other databases +For now please refer to [chapter of "BoltDB comparison with other +databases"](https://github.com/coreos/bbolt#comparison-with-other-databases) +which is also (mostly) applicable to _libmdbx_. + +<!-- section-end --> +<!-- section-begin improvements --> + +Improvements beyond LMDB +======================== + +_libmdbx_ is superior to legendary _[LMDB](https://symas.com/lmdb/)_ in +terms of features and reliability, not inferior in performance. In +comparison to _LMDB_, _libmdbx_ make things "just work" perfectly and +out-of-the-box, not silently and catastrophically break down. The list +below is pruned down to the improvements most notable and obvious from +the user's point of view. + +## Added Features + +1. Keys could be more than 2 times longer than _LMDB_. + > For DB with default page size _libmdbx_ support keys up to 1300 bytes + > and up to 21780 bytes for 64K page size. _LMDB_ allows key size up to + > 511 bytes and may silently loses data with large values. + +2. Up to 20% faster than _LMDB_ in [CRUD](https://en.wikipedia.org/wiki/Create,_read,_update_and_delete) benchmarks. + > Benchmarks of the in-[tmpfs](https://en.wikipedia.org/wiki/Tmpfs) scenarios, + > that tests the speed of the engine itself, showned that _libmdbx_ 10-20% faster than _LMDB_. + > These and other results could be easily reproduced with [ioArena](https://github.com/pmwkaa/ioarena) just by `make bench-quartet` command, + > including comparisons with [RockDB](https://en.wikipedia.org/wiki/RocksDB) + > and [WiredTiger](https://en.wikipedia.org/wiki/WiredTiger). + +3. Automatic on-the-fly database size adjustment, both increment and reduction. + > _libmdbx_ manages the database size according to parameters specified + > by `mdbx_env_set_geometry()` function, + > ones include the growth step and the truncation threshold. + > + > Unfortunately, on-the-fly database size adjustment doesn't work under [Wine](https://en.wikipedia.org/wiki/Wine_(software)) + > due to its internal limitations and unimplemented functions, i.e. the `MDBX_UNABLE_EXTEND_MAPSIZE` error will be returned. + +4. Automatic continuous zero-overhead database compactification. + > During each commit _libmdbx_ merges suitable freeing pages into unallocated area + > at the end of file, and then truncates unused space when a lot enough of. + +5. The same database format for 32- and 64-bit builds. + > _libmdbx_ database format depends only on the [endianness](https://en.wikipedia.org/wiki/Endianness) but not on the [bitness](https://en.wiktionary.org/wiki/bitness). + +6. LIFO policy for Garbage Collection recycling. This can significantly increase write performance due write-back disk cache up to several times in a best case scenario. + > LIFO means that for reuse will be taken the latest becomes unused pages. + > Therefore the loop of database pages circulation becomes as short as possible. + > In other words, the set of pages, that are (over)written in memory and on disk during a series of write transactions, will be as small as possible. + > Thus creates ideal conditions for the battery-backed or flash-backed disk cache efficiency. + +7. Fast estimation of range query result volume, i.e. how many items can +be found between a `KEY1` and a `KEY2`. This is a prerequisite for build +and/or optimize query execution plans. + > _libmdbx_ performs a rough estimate based on common B-tree pages of the paths from root to corresponding keys. + +8. `mdbx_chk` utility for database integrity check. +Since version 0.9.1, the utility supports checking the database using any of the three meta pages and the ability to switch to it. + +9. Automated steady sync-to-disk upon several thresholds and/or timeout via cheap polling. + +10. Sequence generation and three persistent 64-bit markers. + +11. Handle-Slow-Readers callback to resolve a database full/overflow issues due to long-lived read transaction(s). + +12. Support for opening databases in the exclusive mode, including on a network share. + +## Added Abilities + +1. Zero-length for keys and values. + +2. Ability to determine whether the particular data is on a dirty page +or not, that allows to avoid copy-out before updates. + +3. Ability to determine whether the cursor is pointed to a key-value +pair, to the first, to the last, or not set to anything. + +4. Extended information of whole-database, sub-databases, transactions, readers enumeration. + > _libmdbx_ provides a lot of information, including dirty and leftover pages + > for a write transaction, reading lag and holdover space for read transactions. + +5. Extended update and delete operations. + > _libmdbx_ allows one _at once_ with getting previous value + > and addressing the particular item from multi-value with the same key. + +## Other fixes and specifics + +1. Fixed more than 10 significant errors, in particular: page leaks, +wrong sub-database statistics, segfault in several conditions, +nonoptimal page merge strategy, updating an existing record with +a change in data size (including for multimap), etc. + +2. All cursors can be reused and should be closed explicitly, +regardless ones were opened within a write or read transaction. + +3. Opening database handles are spared from race conditions and +pre-opening is not needed. + +4. Returning `MDBX_EMULTIVAL` error in case of ambiguous update or delete. + +5. Guarantee of database integrity even in asynchronous unordered write-to-disk mode. + > _libmdbx_ propose additional trade-off by `MDBX_SAFE_NOSYNC` with append-like manner for updates, + > that avoids database corruption after a system crash contrary to LMDB. + > Nevertheless, the `MDBX_UTTERLY_NOSYNC` mode is available to match behaviour of the `MDB_NOSYNC` in LMDB. + +6. On **MacOS & iOS** the `fcntl(F_FULLFSYNC)` syscall is used _by +default_ to synchronize data with the disk, as this is [the only way to +guarantee data +durability](https://developer.apple.com/library/archive/documentation/System/Conceptual/ManPages_iPhoneOS/man2/fsync.2.html) +in case of power failure. Unfortunately, in scenarios with high write +intensity, the use of `F_FULLFSYNC` significantly degrades performance +compared to LMDB, where the `fsync()` syscall is used. Therefore, +_libmdbx_ allows you to override this behavior by defining the +`MDBX_OSX_SPEED_INSTEADOF_DURABILITY=1` option while build the library. + +7. On **Windows** the `LockFileEx()` syscall is used for locking, since +it allows place the database on network drives, and provides protection +against incompetent user actions (aka +[poka-yoke](https://en.wikipedia.org/wiki/Poka-yoke)). Therefore +_libmdbx_ may be a little lag in performance tests from LMDB where the +named mutexes are used. + +<!-- section-end --> +<!-- section-begin history --> + +# History + +Historically, _libmdbx_ is a deeply revised and extended descendant of the +[Lightning Memory-Mapped Database](https://en.wikipedia.org/wiki/Lightning_Memory-Mapped_Database). +At first the development was carried out within the +[ReOpenLDAP](https://github.com/erthink/ReOpenLDAP) project. About a +year later _libmdbx_ was separated into a standalone project, which was +[presented at Highload++ 2015 +conference](http://www.highload.ru/2015/abstracts/1831.html). + +Since 2017 _libmdbx_ is used in [Fast Positive Tables](https://github.com/erthink/libfpta), +and development is funded by [Positive Technologies](https://www.ptsecurity.com). + +## Acknowledgments +Howard Chu <hyc@openldap.org> is the author of LMDB, from which +originated the _libmdbx_ in 2015. + +Martin Hedenfalk <martin@bzero.se> is the author of `btree.c` code, which +was used to begin development of LMDB. + +<!-- section-end --> + +-------------------------------------------------------------------------------- + +Usage +===== + +<!-- section-begin usage --> +Currently, libmdbx is only available in a +[source code](https://en.wikipedia.org/wiki/Source_code) form. +Packages support for common Linux distributions is planned in the future, +since release the version 1.0. + +## Source code embedding + +_libmdbx_ provides two official ways for integration in source code form: + +1. Using the amalgamated source code. + > The amalgamated source code includes all files required to build and + > use _libmdbx_, but not for testing _libmdbx_ itself. + +2. Adding the complete original source code as a `git submodule`. + > This allows you to build as _libmdbx_ and testing tool. + > On the other hand, this way requires you to pull git tags, and use C++11 compiler for test tool. + +_**Please, avoid using any other techniques.**_ Otherwise, at least +don't ask for support and don't name such chimeras `libmdbx`. + +The amalgamated source code could be created from the original clone of git +repository on Linux by executing `make dist`. As a result, the desired +set of files will be formed in the `dist` subdirectory. + +## Building + +Both amalgamated and original source code provides build through the use +[CMake](https://cmake.org/) or [GNU +Make](https://www.gnu.org/software/make/) with +[bash](https://en.wikipedia.org/wiki/Bash_(Unix_shell)). All build ways +are completely traditional and have minimal prerequirements like +`build-essential`, i.e. the non-obsolete C/C++ compiler and a +[SDK](https://en.wikipedia.org/wiki/Software_development_kit) for the +target platform. Obviously you need building tools itself, i.e. `git`, +`cmake` or GNU `make` with `bash`. + +So just using CMake or GNU Make in your habitual manner and feel free to +fill an issue or make pull request in the case something will be +unexpected or broken down. + +#### DSO/DLL unloading and destructors of Thread-Local-Storage objects +When building _libmdbx_ as a shared library or use static _libmdbx_ as a +part of another dynamic library, it is advisable to make sure that your +system ensures the correctness of the call destructors of +Thread-Local-Storage objects when unloading dynamic libraries. + +If this is not the case, then unloading a dynamic-link library with +_libmdbx_ code inside, can result in either a resource leak or a crash +due to calling destructors from an already unloaded DSO/DLL object. The +problem can only manifest in a multithreaded application, which makes +the unloading of shared dynamic libraries with _libmdbx_ code inside, +after using _libmdbx_. It is known that TLS-destructors are properly +maintained in the following cases: + +- On all modern versions of Windows (Windows 7 and later). + +- On systems with the +[`__cxa_thread_atexit_impl()`](https://sourceware.org/glibc/wiki/Destructor%20support%20for%20thread_local%20variables) +function in the standard C library, including systems with GNU libc +version 2.18 and later. + +- On systems with libpthread/ntpl from GNU libc with bug fixes +[#21031](https://sourceware.org/bugzilla/show_bug.cgi?id=21031) and +[#21032](https://sourceware.org/bugzilla/show_bug.cgi?id=21032), or +where there are no similar bugs in the pthreads implementation. + +### Linux and other platforms with GNU Make +To build the library it is enough to execute `make all` in the directory +of source code, and `make check` to execute the basic tests. + +If the `make` installed on the system is not GNU Make, there will be a +lot of errors from make when trying to build. In this case, perhaps you +should use `gmake` instead of `make`, or even `gnu-make`, etc. + +### FreeBSD and related platforms +As a rule, in such systems, the default is to use Berkeley Make. And GNU +Make is called by the gmake command or may be missing. In addition, +[bash](https://en.wikipedia.org/wiki/Bash_(Unix_shell)) may be absent. + +You need to install the required components: GNU Make, bash, C and C++ +compilers compatible with GCC or CLANG. After that, to build the +library, it is enough to execute `gmake all` (or `make all`) in the +directory with source code, and `gmake check` (or `make check`) to run +the basic tests. + +### Windows +For build _libmdbx_ on Windows the _original_ CMake and [Microsoft Visual +Studio 2019](https://en.wikipedia.org/wiki/Microsoft_Visual_Studio) are +recommended. Otherwise do not forget to add `ntdll.lib` to linking. + +Building by MinGW, MSYS or Cygwin is potentially possible. However, +these scripts are not tested and will probably require you to modify the +CMakeLists.txt or Makefile respectively. + +It should be noted that in _libmdbx_ was efforts to resolve +runtime dependencies from CRT and other libraries Visual Studio. +For this is enough to define the `MDBX_AVOID_CRT` during build. + +An example of running a basic test script can be found in the +[CI-script](appveyor.yml) for [AppVeyor](https://www.appveyor.com/). To +run the [long stochastic test scenario](test/long_stochastic.sh), +[bash](https://en.wikipedia.org/wiki/Bash_(Unix_shell)) is required, and +such testing is recommended with placing the test data on the +[RAM-disk](https://en.wikipedia.org/wiki/RAM_drive). + +### Windows Subsystem for Linux +_libmdbx_ could be used in [WSL2](https://en.wikipedia.org/wiki/Windows_Subsystem_for_Linux#WSL_2) +but NOT in [WSL1](https://en.wikipedia.org/wiki/Windows_Subsystem_for_Linux#WSL_1) environment. +This is a consequence of the fundamental shortcomings of _WSL1_ and cannot be fixed. +To avoid data loss, _libmdbx_ returns the `ENOLCK` (37, "No record locks available") +error when opening the database in a _WSL1_ environment. + +### MacOS +Current [native build tools](https://en.wikipedia.org/wiki/Xcode) for +MacOS include GNU Make, CLANG and an outdated version of bash. +Therefore, to build the library, it is enough to run `make all` in the +directory with source code, and run `make check` to execute the base +tests. If something goes wrong, it is recommended to install +[Homebrew](https://brew.sh/) and try again. + +To run the [long stochastic test scenario](test/long_stochastic.sh), you +will need to install the current (not outdated) version of +[bash](https://en.wikipedia.org/wiki/Bash_(Unix_shell)). To do this, we +recommend that you install [Homebrew](https://brew.sh/) and then execute +`brew install bash`. + +### Android +We recommend using CMake to build _libmdbx_ for Android. +Please refer to the [official guide](https://developer.android.com/studio/projects/add-native-code). + +### iOS +To build _libmdbx_ for iOS, we recommend using CMake with the +"[toolchain file](https://cmake.org/cmake/help/latest/variable/CMAKE_TOOLCHAIN_FILE.html)" +from the [ios-cmake](https://github.com/leetal/ios-cmake) project. + +<!-- section-end --> + +## API description + +Please refer to the online [_libmdbx_ API reference](https://erthink.github.io/libmdbx/) +and/or see the [mdbx.h](mdbx.h) header. + +<!-- section-begin bindings --> + +Bindings +======== + +| Runtime | GitHub | Author | +| ------- | ------ | ------ | +| [Nim](https://en.wikipedia.org/wiki/Nim_(programming_language)) | [NimDBX](https://github.com/snej/nimdbx) | [Jens Alfke](https://github.com/snej) +| Rust | [heed](https://github.com/Kerollmops/heed), [mdbx-rs](https://github.com/Kerollmops/mdbx-rs) | [Clément Renault](https://github.com/Kerollmops) | +| Java | [mdbxjni](https://github.com/castortech/mdbxjni) | [Castor Technologies](https://castortech.com/) | +| .NET | [mdbx.NET](https://github.com/wangjia184/mdbx.NET) | [Jerry Wang](https://github.com/wangjia184) | + +<!-- section-end --> + +-------------------------------------------------------------------------------- + +<!-- section-begin performance --> + +Performance comparison +====================== + +All benchmarks were done in 2015 by [IOArena](https://github.com/pmwkaa/ioarena) +and multiple [scripts](https://github.com/pmwkaa/ioarena/tree/HL%2B%2B2015) +runs on Lenovo Carbon-2 laptop, i7-4600U 2.1 GHz (2 physical cores, 4 HyperThreading cores), 8 Gb RAM, +SSD SAMSUNG MZNTD512HAGL-000L1 (DXT23L0Q) 512 Gb. + +## Integral performance + +Here showed sum of performance metrics in 3 benchmarks: + + - Read/Search on the machine with 4 logical CPUs in HyperThreading mode (i.e. actually 2 physical CPU cores); + + - Transactions with [CRUD](https://en.wikipedia.org/wiki/CRUD) + operations in sync-write mode (fdatasync is called after each + transaction); + + - Transactions with [CRUD](https://en.wikipedia.org/wiki/CRUD) + operations in lazy-write mode (moment to sync data to persistent storage + is decided by OS). + +*Reasons why asynchronous mode isn't benchmarked here:* + + 1. It doesn't make sense as it has to be done with DB engines, oriented + for keeping data in memory e.g. [Tarantool](https://tarantool.io/), + [Redis](https://redis.io/)), etc. + + 2. Performance gap is too high to compare in any meaningful way. + +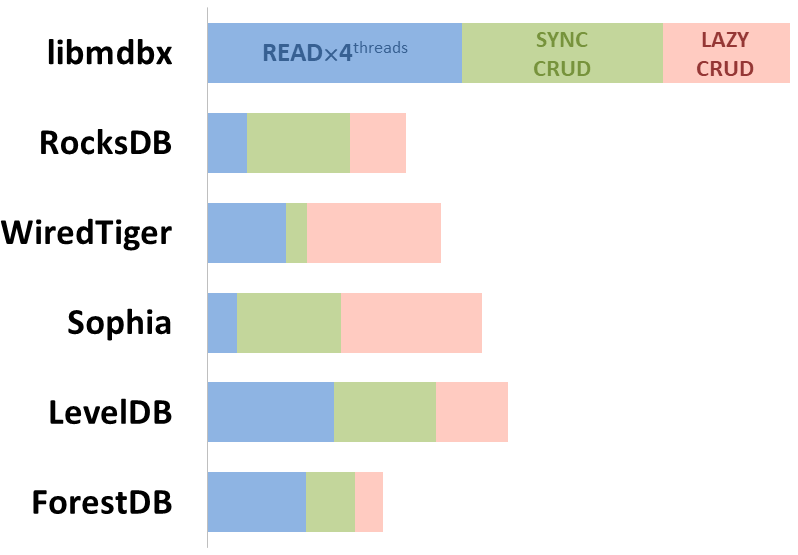 + +-------------------------------------------------------------------------------- + +## Read Scalability + +Summary performance with concurrent read/search queries in 1-2-4-8 +threads on the machine with 4 logical CPUs in HyperThreading mode (i.e. actually 2 physical CPU cores). + +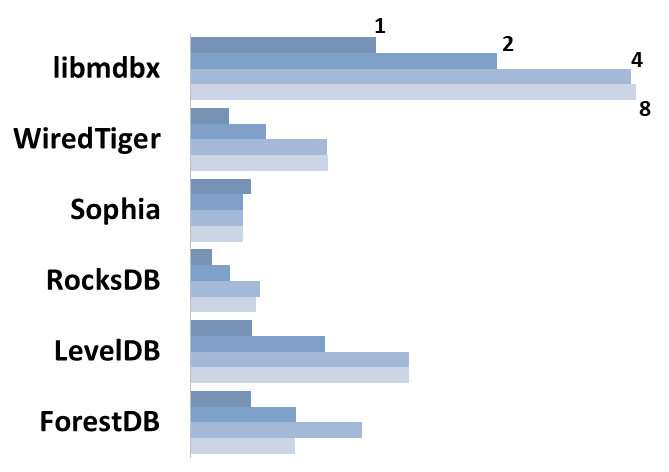 + +-------------------------------------------------------------------------------- + +## Sync-write mode + + - Linear scale on left and dark rectangles mean arithmetic mean + transactions per second; + + - Logarithmic scale on right is in seconds and yellow intervals mean + execution time of transactions. Each interval shows minimal and maximum + execution time, cross marks standard deviation. + +**10,000 transactions in sync-write mode**. In case of a crash all data +is consistent and conforms to the last successful transaction. The +[fdatasync](https://linux.die.net/man/2/fdatasync) syscall is used after +each write transaction in this mode. + +In the benchmark each transaction contains combined CRUD operations (2 +inserts, 1 read, 1 update, 1 delete). Benchmark starts on an empty database +and after full run the database contains 10,000 small key-value records. + +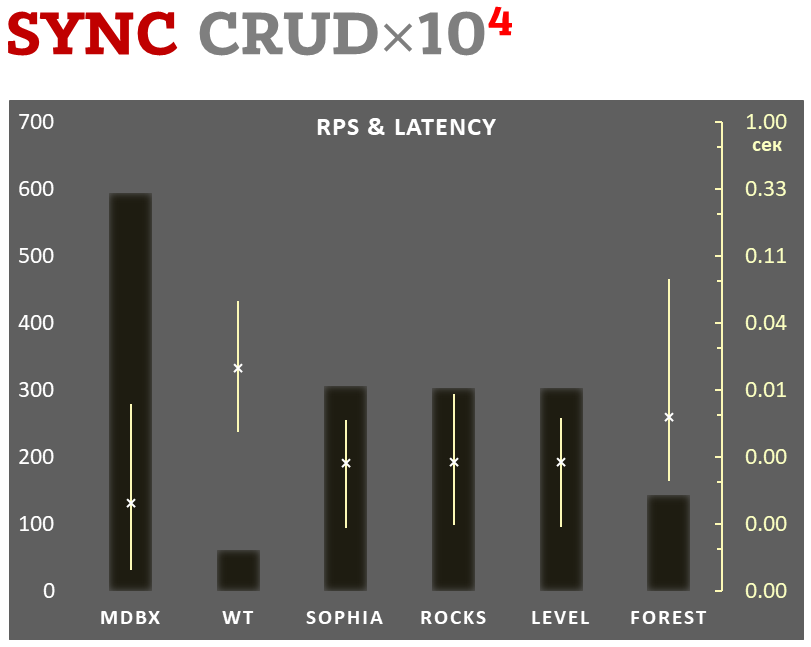 + +-------------------------------------------------------------------------------- + +## Lazy-write mode + + - Linear scale on left and dark rectangles mean arithmetic mean of + thousands transactions per second; + + - Logarithmic scale on right in seconds and yellow intervals mean + execution time of transactions. Each interval shows minimal and maximum + execution time, cross marks standard deviation. + +**100,000 transactions in lazy-write mode**. In case of a crash all data +is consistent and conforms to the one of last successful transactions, but +transactions after it will be lost. Other DB engines use +[WAL](https://en.wikipedia.org/wiki/Write-ahead_logging) or transaction +journal for that, which in turn depends on order of operations in the +journaled filesystem. _libmdbx_ doesn't use WAL and hands I/O operations +to filesystem and OS kernel (mmap). + +In the benchmark each transaction contains combined CRUD operations (2 +inserts, 1 read, 1 update, 1 delete). Benchmark starts on an empty database +and after full run the database contains 100,000 small key-value +records. + + +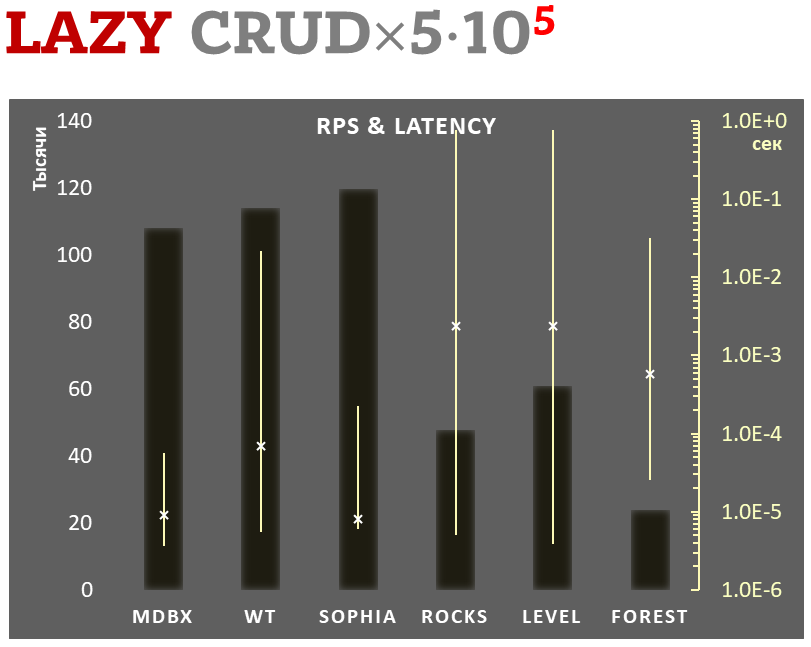 + +-------------------------------------------------------------------------------- + +## Async-write mode + + - Linear scale on left and dark rectangles mean arithmetic mean of + thousands transactions per second; + + - Logarithmic scale on right in seconds and yellow intervals mean + execution time of transactions. Each interval shows minimal and maximum + execution time, cross marks standard deviation. + +**1,000,000 transactions in async-write mode**. In case of a crash all data is consistent and conforms to the one of last successful transactions, but lost transaction count is much higher than in +lazy-write mode. All DB engines in this mode do as little writes as +possible on persistent storage. _libmdbx_ uses +[msync(MS_ASYNC)](https://linux.die.net/man/2/msync) in this mode. + +In the benchmark each transaction contains combined CRUD operations (2 +inserts, 1 read, 1 update, 1 delete). Benchmark starts on an empty database +and after full run the database contains 10,000 small key-value records. + +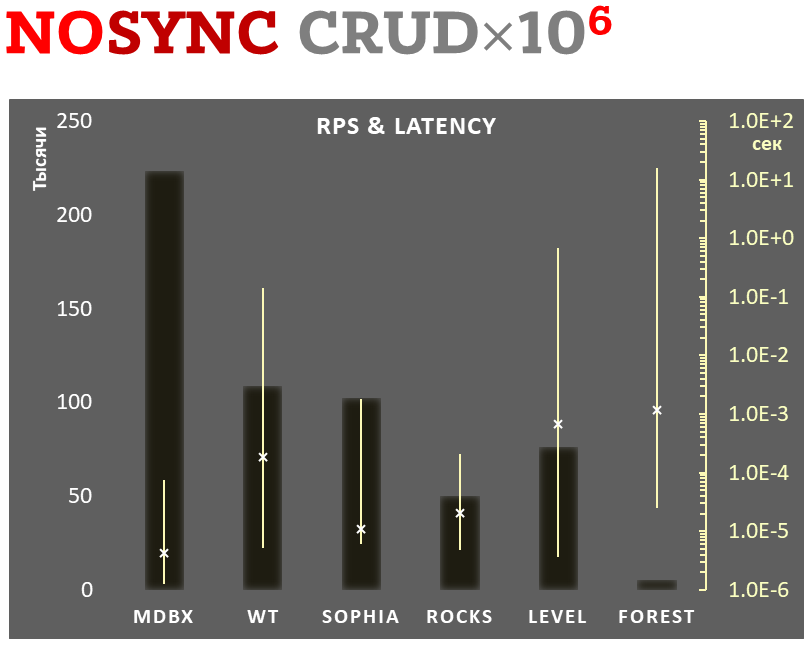 + +-------------------------------------------------------------------------------- + +## Cost comparison + +Summary of used resources during lazy-write mode benchmarks: + + - Read and write IOPs; + + - Sum of user CPU time and sys CPU time; + + - Used space on persistent storage after the test and closed DB, but not + waiting for the end of all internal housekeeping operations (LSM + compactification, etc). + +_ForestDB_ is excluded because benchmark showed it's resource +consumption for each resource (CPU, IOPs) much higher than other engines +which prevents to meaningfully compare it with them. + +All benchmark data is gathered by +[getrusage()](http://man7.org/linux/man-pages/man2/getrusage.2.html) +syscall and by scanning the data directory. + +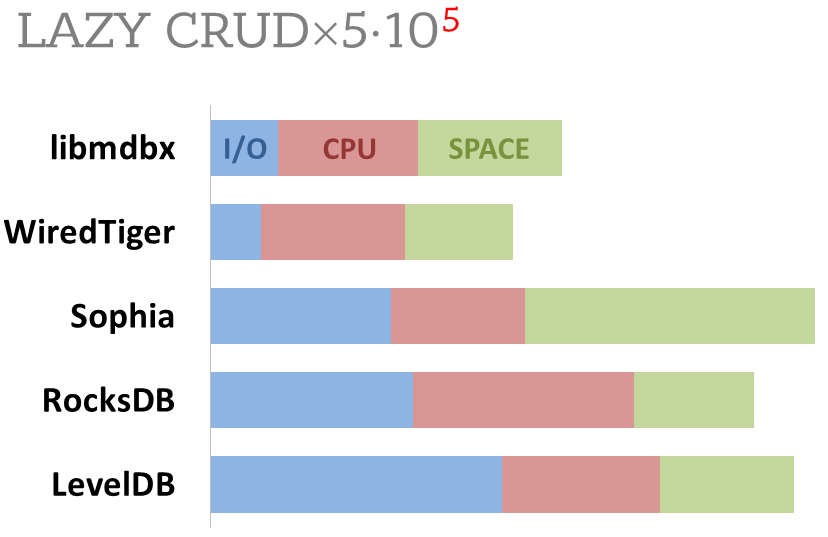 + +<!-- section-end --> + +-------------------------------------------------------------------------------- + +#### This is a mirror of the origin repository that was moved to [abf.io](https://abf.io/erthink/) because of discriminatory restrictions for Russian Crimea. |